

Text clustering with K-means and tf-idf
In this post, I’ll try to describe how to clustering text with knowledge, how important word is to a string. Same words in different strings can be badly affected to clustering this kind of data isn’t important for deciding. The first part of this publication is the general information about TF-IDF with examples on Python. In the second part, I’ll provide you the example showed how this approach can be applied to real tasks.
TF-IDF is useful for clustering tasks, like a document clustering or in other words, tf-idf can help you understand what kind of document you got now.
TF-IDF
Term Frequency-Inverse Document Frequency is a numerical statistic that demonstrates how important a word is to a corpus.
Term Frequency is just ratio number of current word to the number of all words in document/string/etc.
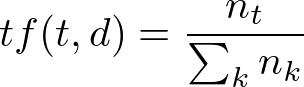
Frequency of term t_i, where n_t — the number of t_i in current document/string, the sum of n_k is the number of all terms in current document/string.
Inverse Document Frequency is a log of the ratio of the number of all documents/string in the corpus to the number of documents with term t_i.
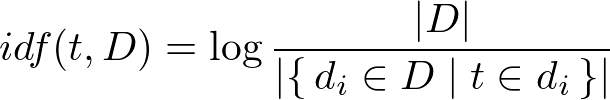
tf-idf(t, d, D) is the product tf(t, d) to idf(t, D).
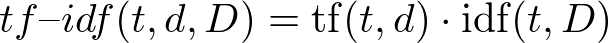
If you want more theoretic information about TF-IDF I want advice you read publication on Wikipedia about it or read NLP Stanford post.
Well, now time for a real example on Python.
TF-IDF example on Python
For all code below you need python 3.5 or newer and scikit-learn and pandas packages.
Firstly, let’s talk about a data set. For this really simple example, I just set a simple corpus with 3 strings. In this example, strings play a role documents.
After that lets make bags of words for our corpus and for every string too. But before we have to clear the data.
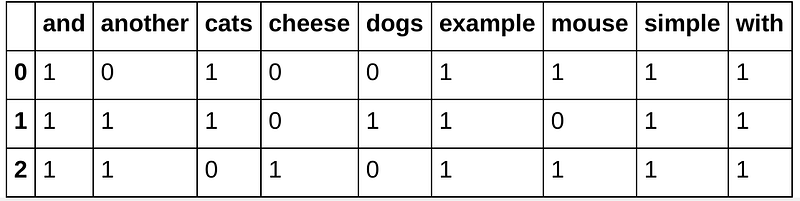
In the case of the term frequency, the simplest choice is to use the raw count of a term in a string. For calculating tf for all terms, we must fill a dictionary as follows.
idf is a measure of how much information the token or word in our case, provides. For calculating idf we need fill dict too.
Now, I remain you that tf-idf is the product of tf to idf. For our python example, tf-idf it dict with the corresponding products.
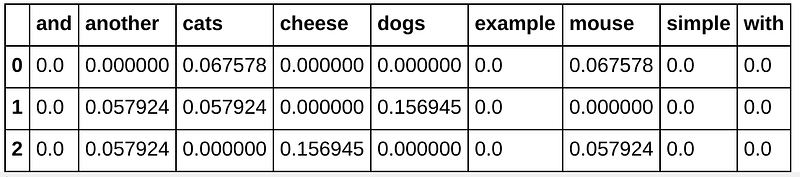
OK, now we have tf-idf weights for each word in our corpus. Below you can clearly see the difference between the original bag of words and the new bag of words with tf-idf weights. For example ‘dogs’, ‘cats’ and ‘mouse’ is important words, but word ‘and’ is not important, because this word is in all the strings and we can’t understand what is a string by the word ‘and’.
KMeans clustering with TF-IDF weights
Now, when we understand how TF-IDF work the time has come for almost real example of clustering with TF-IDF weights. For real life we can use scikit-learn implementation of TF-IDF and KMeans and I suggest you use implementations from scikit-learn or from another popular libraries or frameworks because it’s reducing a number of potential errors in your code.
For this example, we must import TF-IDF and KMeans, added corpus of text for clustering and process its corpus.
After that let’s fit Tfidf and let’s fit KMeans, with scikit-learn it’s really easy.
Now we have learned KMeans model with k = 2 for clustering strings, it’s easy, right? For predicting, just use predict method as follows.
There we can see, that string ‘tf and idf is awesome!’ and ‘some androids is there’ from different clusters and it’s right.
In addition, you can read Jupyter notebook with this examples.
Thanks for the reading, please leave a feedback. This can help me improve the quality of my future posts.
And don’t forget to follow me on twitter.




