
Testing memory saving on V100 and GTX 1080
These are instructions to reproduce experiments from https://readmedium.com/fitting-larger-networks-into-memory-583e3c758ff9
To test on Amazon, follow instructions to launch and connect to a gpu-enabled machine: https://github.com/diux-dev/cluster/tree/master/gpubox
Then install TensorFlow. You can do pip install tf-nightly-gpu or if you want a specific version that I tested, follow commands below. (Note, — upgrade-strategy flags is needed to prevent pip from overwriting Intel-optimized numpy). That particular version must be installed from local file because md5 doesn’t match.
source activate mxnet_p36
url=https://pypi.python.org/packages/9e/01/5199a2c78bd7351c78b88f8ab58407329b59f6f7ab6b4f3db69e67a8c43b/tf_nightly_gpu-1.5.0.dev20171220-cp36-cp36m-manylinux1_x86_64.whl#md5=90203db7437fd1400f2966aa4bead221a
fn=tf_nightly_gpu-1.5.0.dev20171220-cp36-cp36m-manylinux1_x86_64.whl
wget -O $fn $url
pip install --upgrade $fn --upgrade-strategy=only-if-neededTo get gradient checkpointing package and test that things work.
git clone https://github.com/openai/gradient-checkpointing.git
pip install toposort networkx pytest
cd gradient-checkpointing/test
pytestTesting on GPU machine takes about 60 seconds. AWS instances has additional 100–200 second warm-up time to do anything with Python.
Memory benchmark
Code below runs evaluation on model taken from TensorFlow official resnet CIFAR example, and runs it with gradient checkpointing for various resnet sizes.
To run the resnet benchmark with/without gradient checkpointing over sizes up to 5 blocks.
cd gradient-checkpointing/test
python deep_resnet_benchmark.py --max_blocks=5Once it’s running, you should see something like below on p2.xlarge instance. The numbers are: “number of blocks”, “peak memory in MBs”, “seconds per iteration”
Running with checkpoints
1 1683 3.51 seconds
2 1713 4.66 seconds
3 1934 6.50 seconds
4 1891 8.44 seconds
Running without checkpoints
1 1620 1.89 seconds
2 2145 3.38 seconds
3 2648 4.79 seconds
4 3172 6.20 secondsPlotting the numbers for larger sizes, you see this:
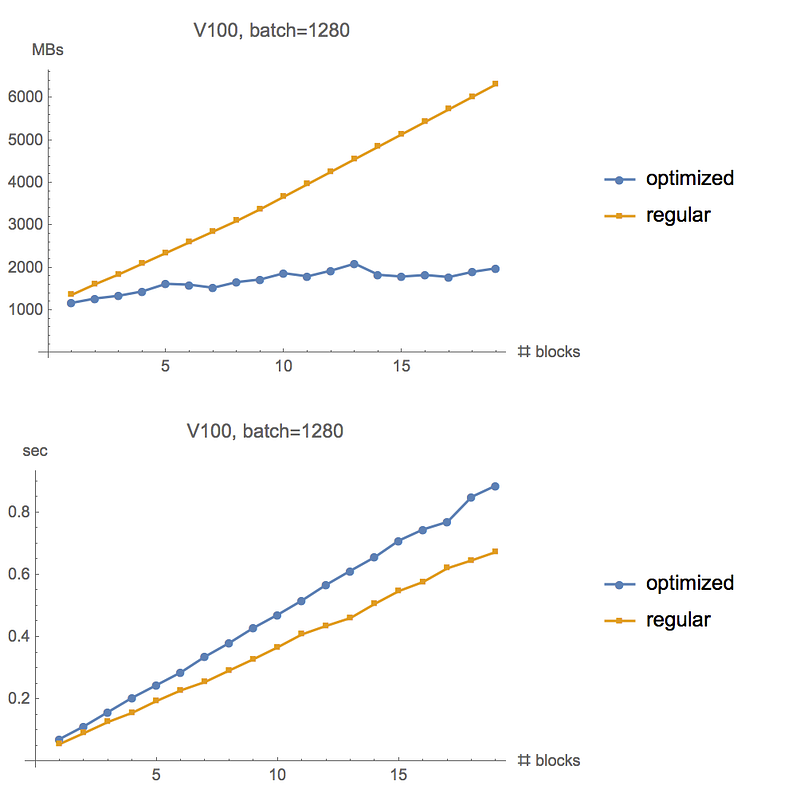
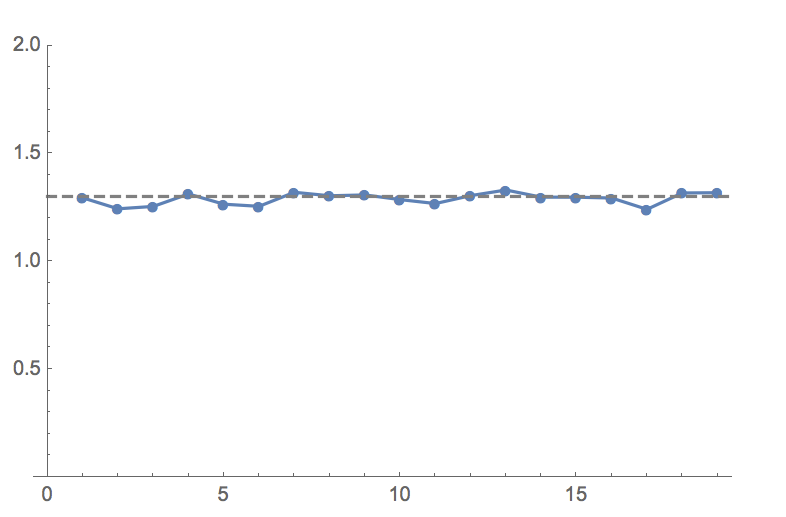
Per-iteration cost roughly stays constant as depth increases, about 30% over regular iteration cost. Below is a graph of time of rewritten iteration on V100 divided by original time.
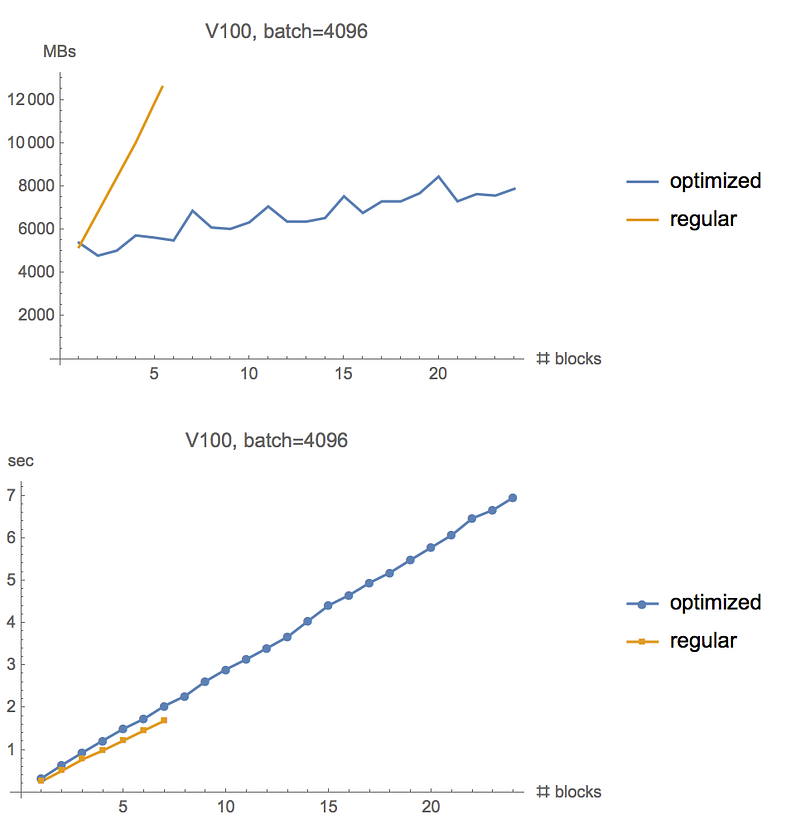
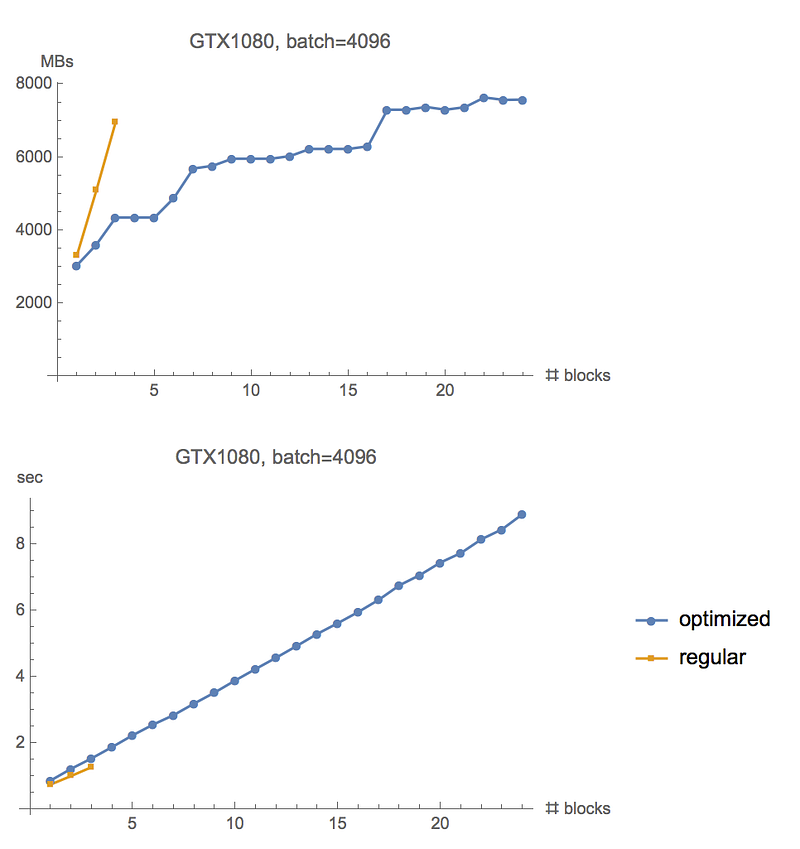
We can increase batch size to 4096, and the regular gradient computation runs out of memory after 5 resnet blocks, while gradient checkpointing allows it to go past 25.
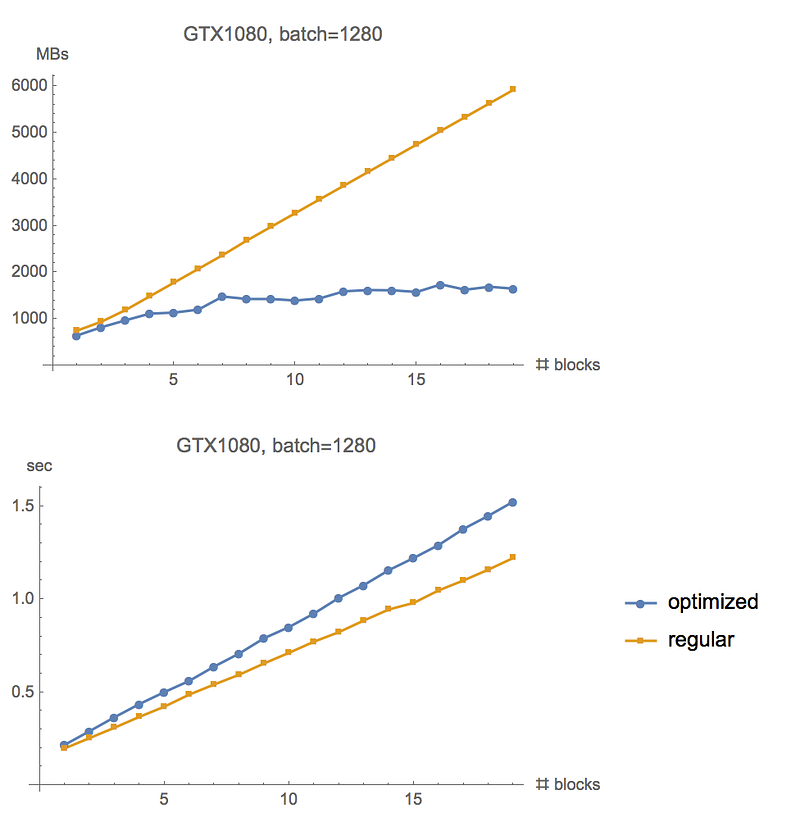
For completeness, here are graphs of experiments running on GTX 1080. Similar memory saving, but the recomputation overhead is slightly lower, at about 20%
Note that time to compile the graph can be slow. In particular, resnet with 200 blocks takes 30 mins to compile:
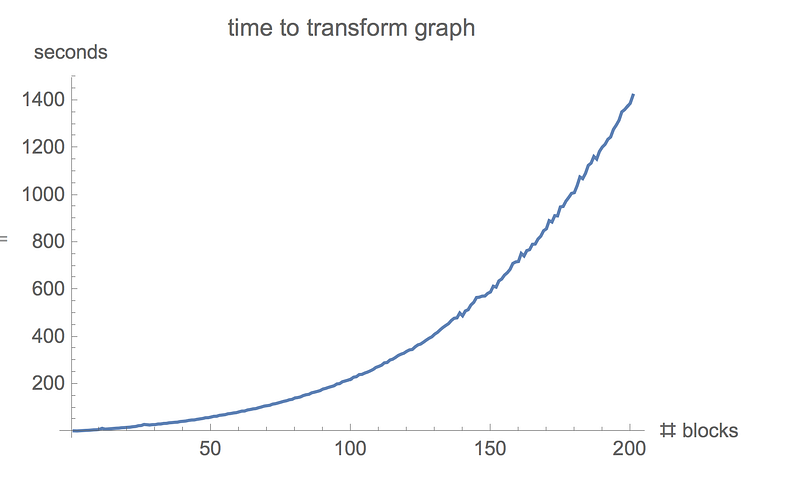
This slowness partly due to inefficiency intf.gradients. More specifically, the package does many tf.gradients calls over small subgraphs, which is slow becausetf.gradients while runtime scales linearly with size of overall graph rather than just size of subgraph (tracking issue: tf.gradients runtime scales suboptimally with size of the graph)
Raw data: https://wolfr.am/rEd8qTRJ