
Tensorflow 2的Quantization Aware Training指南
在低運算資源的平台上,神經網路的計算資源通常會有明顯的限制。為了追求低運算量的神經網路,有兩個常見大方向,一個大方向是透過各種魔改技巧,將最有效率的架構保留下來,包含架構設計 (如MobileNet) 、知識蒸餾 (knowledge distillation) 與網路剪枝 (network pruning) 等等。另一個大方向就就是從神經網路的根本計算著手,將所有運算量子化 (quantization),使用更低精度的資料表示型態進行計算。
Tensorflow作為各平台最全面支援的深度學習框架之一,提供了不同精度的quantization操作。除了支援直接quantize已訓練網路的post-quantization,也支援了在訓練時模擬低精度運算的training aware quantization (QAT)。QAT是目前quantization方法中,最能維持模型準度的方法之一。

文章難度:★★★☆☆ 閱讀建議: 這是一篇 Tensorflow 2或以上版本的 quantization aware training教學。開頭簡單介紹 quantization與 quantization aware training (QAT),而後主要介紹如何以 Tensorflow 2+的程式風格進行 QAT,後續也介紹了一些目前Tensorflow Model Optimization模組的問題與解決方案 (batch normalization folding與unsupported layers等等)。 推薦背景知識: convolution neural network, edge computing, quantization, quantization aware training, Tensorflow, Tensorflow Lite.
Quantization: Quick Review
所謂的model quantization指的是將原本使用floating point計算的model (大多為float32),在推理時改為使用更小精準度的單位 (常見int8或int16)。
如果模型在float32下做訓練,而推理時直接強迫壓縮到低精度 (以下用int8代替),稱為post-quantization。想當然,這樣的操作容易使網路的預測效果變差。與之對應的是在訓練時模擬int8的行為,實際上運行仍然是保持floating point的狀態,保證梯度的精準。這個模擬動作是來自於在原本的operator上插上將精度的operator (一般稱為fake quantization),這樣的訓練劇本稱為training aware quantization (QAT)。
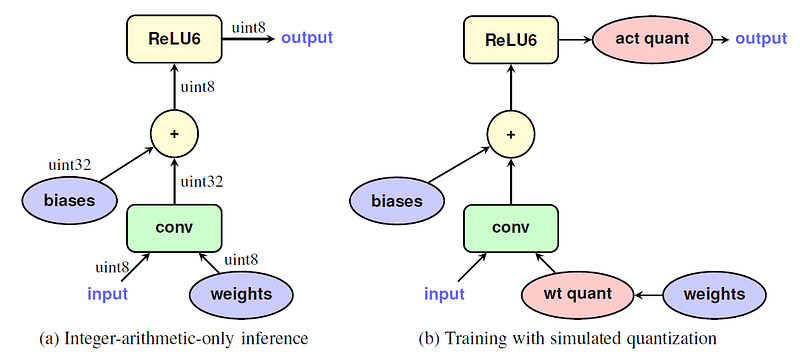
目前這樣的劇本大致來自 Google這篇論文 (“Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference” [1]),關於實際的細節有很多,就不在這篇文章多提。
Quantization Aware Training (QAT) on Tensorflow 2
在大多數的靜態圖框架上quantization aware training (QAT) 的作法都是先定義好原本的model,再將這個model中的operator插上額外的fake quantization operator,讓訓練的過程中保持計算為浮點數,卻可以近似模擬部屬(deployment) 時quantized的行為。
在Tensorflow 2 (TF2) 中,quantization aware training (QAT) 實作於Tensorflow Model Optimization (TFMOT) 這包library中,繼承了TF2與Keras物件概念上不可分割的邏輯,要直接使用官方支援的QAT方法必須使用Keras物件。基本上分為layer level與model level的quantized model轉換。
這邊要先特別說一件事情,截至今日 (2020.11.19) TFMOT的 QAT不支援 Keras subclass model的寫法,所有要被轉換的 keras model都要使用 Keras functional API。
Convert whole Keras model
直接轉換整個Keras model,是操作上最簡單的方法。首先,先使用Keras functional API建立一個Keras model,不論是keras.Sequential或是keras.Model(inputs, outputs)都可以。
Model: "BaseModel" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 20, 20, 1) 2 _________________________________________________________________ flatten_1 (Flatten) (None, 400) 0 _________________________________________________________________ dense_4 (Dense) (None, 32) 12832 _________________________________________________________________ dense_5 (Dense) (None, 1) 33 ================================================================= Total params: 12,867
Trainable params: 12,867
Non-trainable params: 0 接下來直接使用quantize_model 來轉換整個Keras model,這個function會自動在對應的operator前後插上fake quantization的operator。
Model: "BaseModel" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= quantize_layer_2 (QuantizeLa (None, 20, 20, 1) 3 _________________________________________________________________ quant_conv2d_1 (QuantizeWrap (None, 20, 20, 1) 7 _________________________________________________________________ quant_flatten_1 (QuantizeWra (None, 400) 1 _________________________________________________________________ quant_dense_4 (QuantizeWrapp (None, 32) 12837 _________________________________________________________________ quant_dense_5 (QuantizeWrapp (None, 1) 38 ================================================================= Total params: 12,886
Trainable params: 12,867
Non-trainable params: 19Layer成功轉換後,除了在Tensorboard上可以看到額外的fake quantization operator外,layer name上也會被刻上quant_的註記。
Convert annotated layers
有的時候並不是整個Keras model都需要被quantized,可能有些layer不適合被、不需要或者設計上不想要quantized,就可以使用quantize_annotate_layer的方法。
這樣我們就能控制要被quantized的layers,比如在這個例子中,只有dense layer要被quantized,而convolution則是保持原本的精度。
Model: "BaseModel" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 20, 20, 1) 2 _________________________________________________________________ flatten (Flatten) (None, 400) 0 _________________________________________________________________ quant_dense_2 (QuantizeWrapp (None, 32) 12837 _________________________________________________________________ quant_dense_3 (QuantizeWrapp (None, 1) 38 ================================================================= Total params: 12,877
Trainable params: 12,867
Non-trainable params: 10其實建模時就可以直接調用
quantize_annotate_layer來強制建立有 fake quantization行為的 layer,但是這樣的 layer在命名上會被強制加上quant_這會使得預載 pretrain weights變得複雜。而clone_model就是一個複製 Keras模型,並提供一個 transform mapping的機制。使用clone_model就可以先建立模型,預載參數,再執行 quantization model的轉換。
Load pretrained weights
經驗指出,加入fake quantization的網路訓練狀況比較不穩定,特別是在前期容易走到不可挽回的地方,因此大多數人在訓練的時候會在一開始關閉fake quantization的行為,或是先在floating point下訓練模型,而後才在quantization aware training的情況下finetune。
在Tensorflow 2這個的實作要在將model轉為quantization之前,也就是調用quantize_model或是quantize_annotate_layer之前。
Batch normalization folding
Batch normalization在quantization inference時有個細節。在實際上deploy model時,大多數的情況 (比如說Tensorflow Lite) 會將convolution + batch normalization + activation這三個組合成一個新的operator。實際上batch normalization的參數會藏到convolution中,這個動作就稱為batch normalization folding。
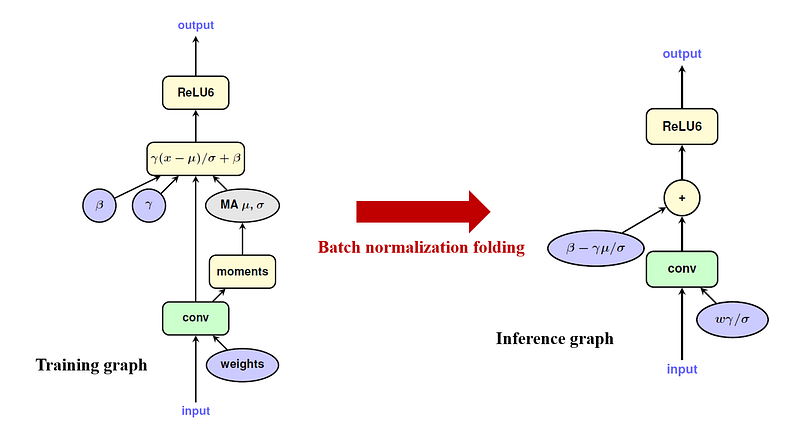
截至今日 (2020.11.19) TFMOT的 QAT只支援 Conv2D與 DepthwiseConv2D的 batch normalization folding,而且必須放在這兩個 layer的正後方,中間不可以有任何其他的 operator或 activation。
Advance: Not Supported Layers
一個在TF2的QAT中一個常見的問題是有許多layer官方不支援,如果使用到了會直接報錯,比如說簡單的Upsampling2D 。考慮以下一個簡單的model:
比起剛剛的model只是多了一個Upsampling2D ,然而在使用model based的quantization轉換時,不論是quantize_model 或是quantize_apply 都是無法通過的。
RuntimeError: Layer up_sampling2d:<class 'tensorflow.python.keras.layers.convolutional.UpSampling2D'> is not supported. You can quantize this layer by passing a `tfmot.quantization.keras.QuantizeConfig` instance to the `quantize_annotate_layer` API.目前官方支援的 layer可以參考 TFMOT的 whitelists。
以interpolation=”nearest”的Upsampling2D 來說,這邊其實不需要任何quantization操作,但是TFMOT會檢查所有的layer都是他預設認識的layer才會讓這個model通過轉換。
這時候就需要QuantizeConfig 來協助TFMOT認識這個layer,QuantizeConfig 描述了這個layer實際在quantized下的行為,以及要如何進行fake quantization。比如說以下是Dense 使用的QuantizeConfig,裡面定義了怎麼拿weight與activation輸出,並且設定對應使用使用的quantizer。
而interpolation=”nearest”的Upsampling2D 事實上不需要任何fake quantization的操作,所以可以直接調用官方寫好的NoOpQuantizeConfig,一個完全空白的QuantizeConfig 。
在轉換model時,要使用前面說的convert annotated layers的方法,並且使用QuantizeConfig 標註不支援的layer。在轉換model時,使用額外的scope告知TFMOT有哪些額外的QuantizeConfig 需要被考慮。
Model: "AdvancedModel" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= quantize_layer_1 (QuantizeLa (None, 20, 20, 1) 3 _________________________________________________________________ quant_conv2d_1 (QuantizeWrap (None, 20, 20, 1) 7 _________________________________________________________________ quant_up_sampling2d (Quantiz (None, 40, 40, 1) 1 _________________________________________________________________ quant_flatten_1 (QuantizeWra (None, 1600) 1 _________________________________________________________________ quant_dense_2 (QuantizeWrapp (None, 32) 51237 _________________________________________________________________ quant_dense_3 (QuantizeWrapp (None, 1) 38 ================================================================= Total params: 51,287
Trainable params: 51,267
Non-trainable params: 20Some Additional Memo
以下是一些關於quantization aware training與Tensorflow 2的額外筆記,為了避免內容過於冗長,簡單條列於此:
- 如果是
float32到int8的quantization,可以提供大約近四倍 (理論值) 到至多十多倍 (配合Hexagon具備向量加速的晶片) 的推理速度。 - 使用
clone_model搭配quantize_annotate_layer與quantize_apply是目前最穩定泛用的組合。 - Load pretrain weights不是必須,但是可以讓QAT變得更加穩定。
- 截至目前 (2020.11.19),
BatchNormalization一定要放在Conv2D或是DepthwiseConv2D的正後方。Conv2DTranspose(deconvolution) 目前是不支援batch normalization folding,建議暫時改用resize或upsample後接convolution。 - 截至目前 (2020.11.19) TFMOT的QAT不支援Keras subclass model的寫法,建議完全採用Keras functional API。
- 沒事盡量不要寫custom Keras layer,盡量使用functional API接法,重複常用的客製的layer可以用function銜接或是自己寫假的Keras layer。
好了~這篇文章就先到這。Tensorflow 2其實在大改版後,尚未到一個非常穩定的狀態,在quantization這邊也幾乎都由不同團隊進行模組的設計與維護,相信用過的人都會覺得還有很多的雷要採。不過事實上目前的QAT設計確實與Keras物件融合得不錯,搭配Tensorflow Lite的轉換也是相當輕鬆愉快,後續的許多支持就等待官方隨著時間陸續發布吧!
這篇文章使用的程式碼都可以在這個Colab中找到,有興趣可以自行調閱。
Related Topics
Reference
[1] Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference [CVPR 2018] [2] Quantizing deep convolutional networks for efficient inference: A whitepaper [arXiv 2018] [3] Quantization aware training comprehensive guide [Tensorflow Official]




