
Tagging Service System Design
Hashtag Service Design

You can subscribe to the system design newsletter to excel in system design interviews and software architecture. You will also receive the ultimate guide to approaching system design interviews on newsletter sign-up.
The original article was published on systemdesign.one website by the author NK. Some of the popular tagging services are the following:
- JIRA tags
- Confluence tags
- Stackoverflow tags
- Twitter hashtags
Disclaimer: Some of the linked resources are affiliates.
Requirements
- Tag an item
- View the items with a specific tag in near real-time
- Scalable
Newsletter
Subscribe to my newsletter and never miss a new blog post again, as you’ll get notified via email every time I publish something. You will also receive the ultimate guide to approaching system design interviews on newsletter sign-up.
If you’re planning to subscribe to Medium using my referral link, I wanted to let you know that I will receive a portion of the membership fees as a reward for referring you. This helps me continue to produce valuable content. However, I want to assure you that this doesn’t affect your subscription cost in any way. You’ll still get the same great benefits and features as any other Medium member. Thank you for considering my referral link and supporting my work!
Data storage
Database schema
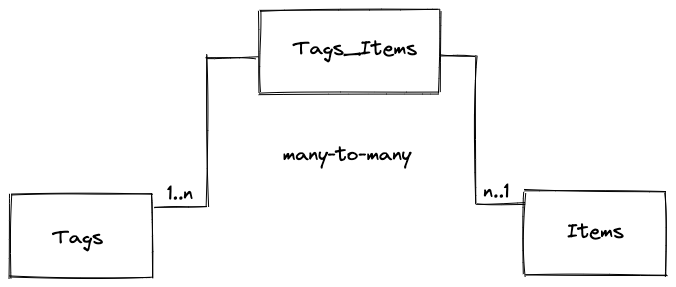
- The primary entities of the database are the Tags table, the Items table, and the Tags_Items table
- The Tags_Items is a join table to represent the relationship between the Items and the Tags
- The relationship between the Tags and the Items tables is many-to-many
Type of data store
- The media files (images, videos) and text files are stored in a managed object storage such as AWS S3
- A SQL database such as Postgres stores the metadata on the relationship between tags and items
- A NoSQL data store such as MongoDB stores the metadata of the item
- A cache server such as Redis stores the popular tags and items
High-level design
- When a new item is tagged, the metadata is stored on the SQL database
- The popular tags and items are cached on dedicated cache servers to improve latency
- The non-popular tags and items are fetched by querying the read replicas of SQL and NoSQL data stores
Write path
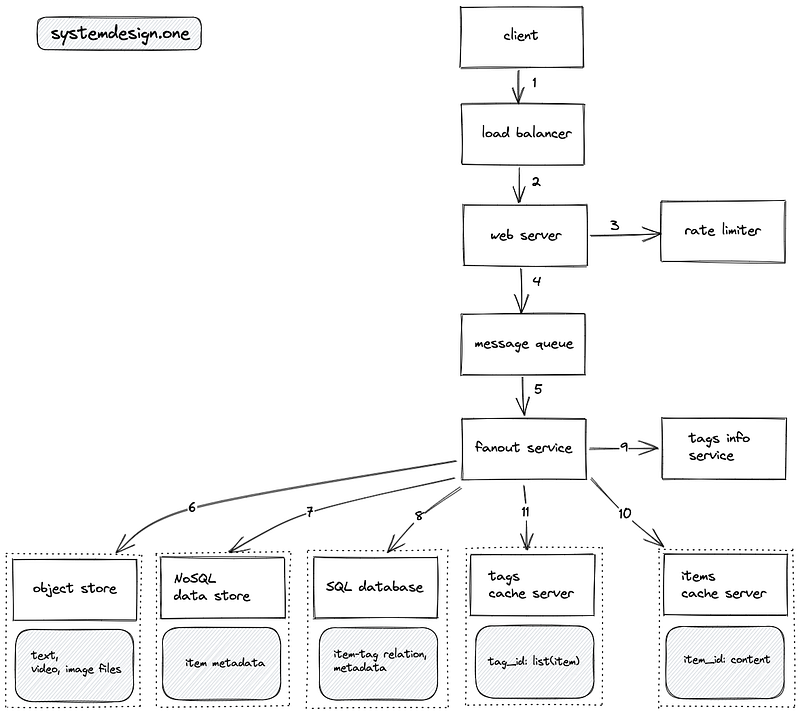
- The client makes an HTTP connection to the load balancer
- The load balancer delegates the client request to a web server with free capacity
- The write requests to create an item or tag an item are rate limited
- The write requests are stored on the message queue for asynchronous processing and improved fault tolerance
- The fanout service distributes the write request to multiple services to tag an item
- The object store persists the text files or media files embedded in an item
- The NoSQL data store persists the metadata of an item (comments, upvotes, published date)
- The SQL database persists metadata on the relationship between tags and items
- The tags info service is queried to identify the popular tags
- If the item was tagged with a popular tag, the item is stored on the items cache server
- The tags cache server stores the IDs of items that were tagged with popular tags
- LRU cache is used to evict the cache servers
- The data objects (items and tags) are replicated across data centers at the web server level to save bandwidth
Read path
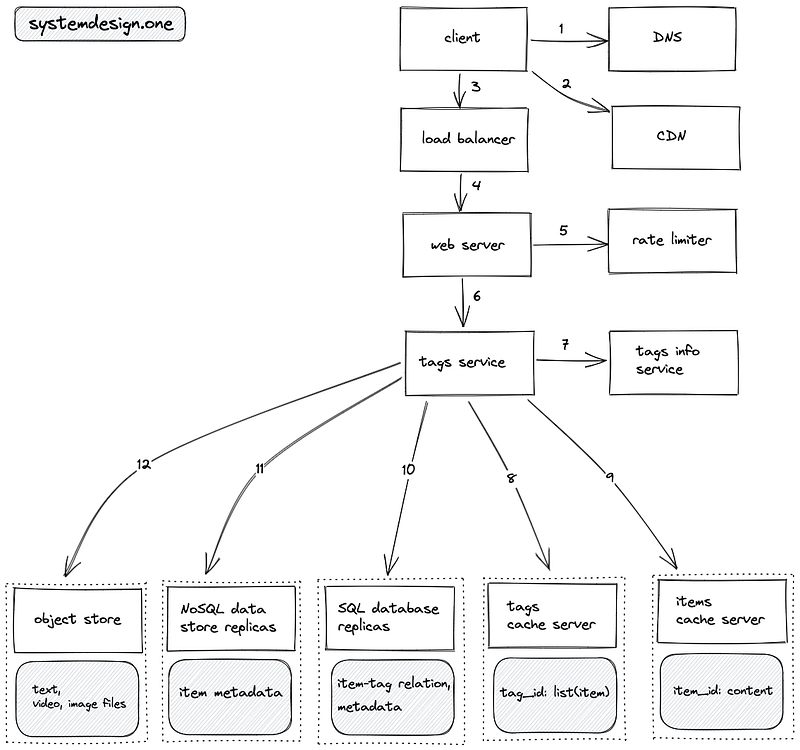
- The client executes a DNS query to resolve the domain name
- The client queries the CDN to check if the tag data is cached on the CDN
- The client creates an HTTP connection to the load balancer
- The load balancer delegates the client request to a web server with free capacity
- The read requests to fetch the tags or items are rate limited
- The web server queries the tags service to fetch the tags
- The tags service queries the tags info service to identify if the requested tag is popular
- The lists of tagged items for a popular tag are fetched from the tags cache server
- The tags service executes an MGET Redis request to fetch the relevant tagged items from the items cache server
- The list of items tagged with non-popular tags is fetched from the read replicas of the SQL database
- The items tagged with non-popular tags are fetched from the read replicas of the NoSQL data store
- The media files embedded in an item are fetched from the object store
- The trie data structure is used for typeahead autosuggestion for search queries on tags
Newsletter
Subscribe to my newsletter and never miss a new blog post again, as you’ll get notified via email every time I publish something. You will also receive the ultimate guide to approaching system design interviews on newsletter sign-up.
If you’re planning to subscribe to Medium using my referral link, I wanted to let you know that I will receive a portion of the membership fees as a reward for referring you. This helps me continue to produce valuable content. However, I want to assure you that this doesn’t affect your subscription cost in any way. You’ll still get the same great benefits and features as any other Medium member. Thank you for considering my referral link and supporting my work!
References
- Raffi Krikorian, Timelines at Scale, infoq.com
- How feed works, facebook.com
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 💰 Free coding interview course ⇒ View Course
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job





