
System Design Basics 3 — Concurrency
Concurrency is the idea of doing multiple tasks at the same time. Concurrency can happen in a single server, where it is achieved by assigning tasks to different threads. Concurrency can also happen in a multiple-server environment, where the workload is distributed among different servers. A good example of concurrency in a multiple-server environment is Spark, which splits data into smaller partitions and assigns them to multiple executor nodes to be processed. Having a solid understanding of concurrency is very critical to understanding some of the most common design decisions in system designs.
Multi-threading Primer
In this and the following sections, I will give you a quick introduction to multi-threading, thread-safe, race conditions and synchronization. To understand multi-threading, first you need to know five concepts and the relationships between them. They are
- Thread
- Task
- Process
- Thread scheduler
- CPU
A task is the piece of code we want to run. A thread is like a worker who gets assigned a task and works on the task. A process is the environment where the threads live and share common resources such as memory. CPU is one of the resources a thread needs to execute the task. The thread scheduler monitors threads and decides which thread gets a share of the CPU.
I like to use an Amazon fulfillment center analogy to explain multi-threading. Imagine an Amazon fulfillment center where there are multiple conveying belts delivering packages from one end to the other. At the end of each conveying belt, sits a worker who puts shipping labels on the packages. Each worker needs to use a tool to put the label, and imagine there is only a limited number of tools, so they must share. There is one supervisor who monitors the workers and passes the tools from worker to worker. In this analogy, the workers are threads, the packages are the work or task, and you can think of each package as a line of code. The tool is the CPU, and the supervisor is the thread scheduler.
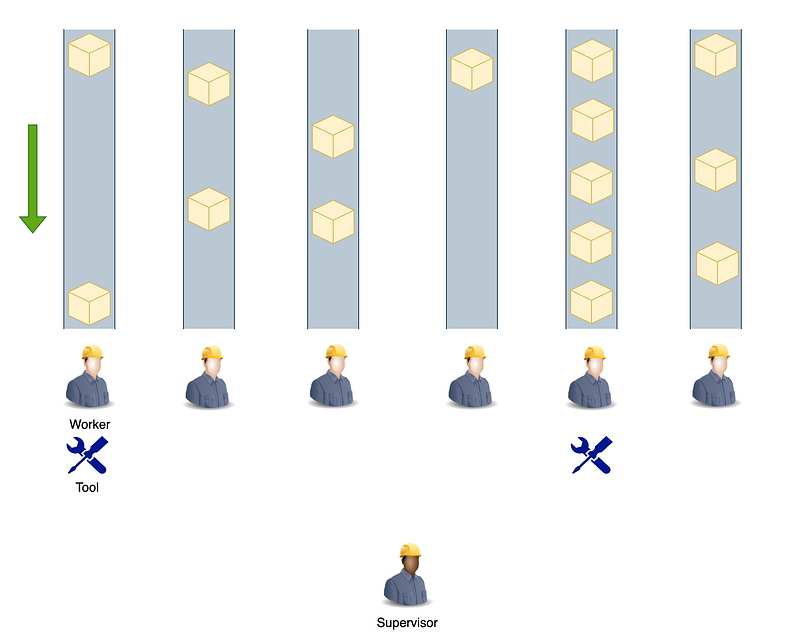
Now imagine a worker who just gets a package from the conveyor belt and uses the tool to put the shipping label on the package. The next package is still far away. You don’t want to let this worker hold the valuable tool and wait until his next package arrives, right? To make full use of the tool, the supervisor takes the tool and gives it to another worker who just gets a package. You can think of the the conveyor belt with dense packages as work that is CPU-intensive, and the belt with packages far apart as work that is IO-intensive. Now if you view a fulfillment center as a process, the tools (CPUs) are shared with other fulfillment centers. Thus you need to control the number of threads based on the number of CPUs, as well as how CPU-intensive the task is. For example, if you know there are going to be a lot of CPU-intensive tasks, you should limit the number of threads, as having too many threads executing CPU-intensive tasks would cause the computer to perform quite slowly as your process is occupying most of the CPU bandwidth. On the other hand, if the tasks are IO-intensive, you can increase the number of threads as most of the time the threads are just waiting on external resources.
Now done with our conveyor belt analogy. Let’s define concurrency. Concurrency is the property of executing multiple threads and processes at the same time. Of course, with a single-core CPU system, only one task is actually executing at a given time. Back to the conveyor belt analogy, if there is only one tool, only one worker can work at a given time. But from an outsider's point of view, it gives the illusion that all these workers are working simultaneously.
Java concurrency API
Java concurrency API provides an ExecutorService class, which is the preferred way to create a multi-threading program. It’s worth taking a look at an example to better understand how a multi-threading program can be created. In the code snippet below, we create a thread pool of 10 threads using the factory method newFixedThreadPool. Then we submit 10 tasks to the pool using the submit method. In each task, we call the private method workOnTask, which increments the taskId and prints out a message.
import java.util.concurrent.*;
public class TaskManager {
private int taskId = 0;
private void workOnTask() {
System.out.println("Task " + (taskId++) + " is done!");
}
public static void main(String[] args) {
ExecutorService service = null;
try {
service = Executors.newFixedThreadPool(10);
TaskManager manager = new TaskManager();
for (int i=0; i<10; i++)
service.submit(() -> manager.workOnTask());
} finally {
if(service != null) service.shutdown();
}
}
}Because it’s a multi-threading program, tasks will be executed concurrently, and there is no guarantee which task will be executed first. Here is one of the possible outputs. You can see that in the output below there are two Task 2 and there is no Task 9. I will explain it in the next section.
Task 1 is done!
Task 6 is done!
Task 2 is done!
Task 2 is done!
Task 3 is done!
Task 8 is done!
Task 4 is done!
Task 7 is done!
Task 0 is done!
Task 5 is done!Thread Safe & Synchronization
A multi-thread program isn’t thread-safe inherently. To understand what thread-safe is, first we need to understand race conditions. We have already seen a race condition in the previous example. Remember there are two Task 2. Let’s change the code a bit so you can understand better. The code below is equivalent to the original code.
private void workOnTask() {
String output = "Task " + taskId + " is done!"
taskId = taskId + 1
System.out.println(output);
}In a single thread environment, the tasks are executed in order and we should see Task Ids printed out in order. But in a multi-thread environment, two threads might be executing at the same time and both see taskId as 2, as illustrated below
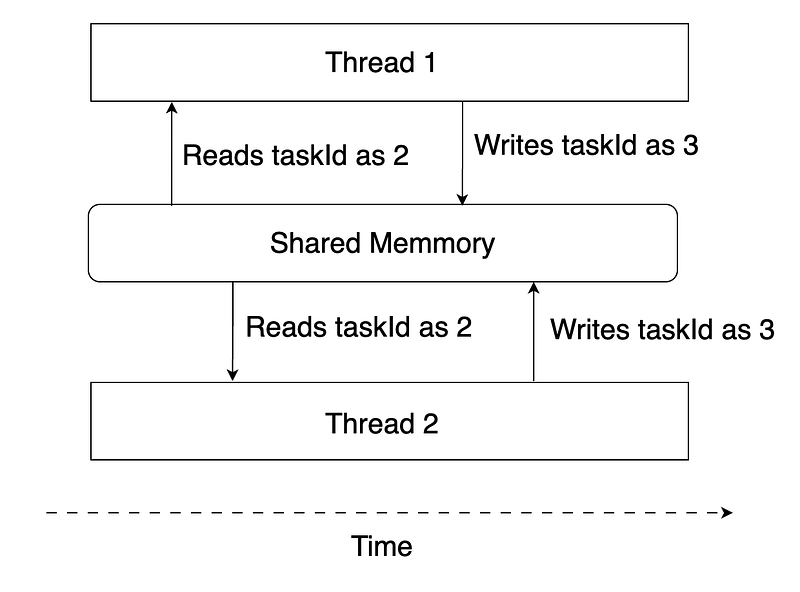
This is a great example of an unexpected result of two tasks executing at the same time. We call this race condition. To resolve race conditions and make the program thread-safe, we need synchronization. How do we apply synchronization to make our example thread-safe? Here is when the lock comes in. A lock, or a monitor is a structure that supports mutual exclusion, which means only one thread can execute a piece of code at a given time.
In Java, any object can be a lock. There are several ways to synchronize the code in the previous example, and one of the approaches is to use a synchronized block. To do that, you only need to add the synchronized keyword to the workOnTask method, as shown below.
private synchronized void workOnTask() {
System.out.println("Task " + (taskId++) + " is done!");
}This essentially synchronizes on the TaskManager object itself. Now the method is synchronized, only one thread can execute the method at a given time, the lost write problem will disappear and the output will be ordered, as shown below.
Task 0 is done!
Task 1 is done!
Task 2 is done!
Task 3 is done!
Task 4 is done!
Task 5 is done!
Task 6 is done!
Task 7 is done!
Task 8 is done!
Task 9 is done!This essentially turns the code from multi-threading into single-threading, because none of the tasks can be executed concurrently. Originally we had a multi-threading program, it’s not thread-safe and we made it thread-safe by applying synchronization, and now it’s back to a single-thread program. What’s the point of all this? The thing is in real-world applications, you might have some methods that can be executed concurrently, taking full advantage of multi-threading, while also having other methods that need to be synchronized. It’s not a game of all or nothing, rather you tune the balance between concurrency and synchronization based on your app’s needs.
Concurrency & System Design
Now you might be thinking how concurrency and synchronization have anything to do with system design. Admittedly system design rarely involves multi-threading and synchronization, but concurrency and synchronization prevail in software engineering. That being said, knowing concurrency and synchronization, at least on a high level, still helps a lot in system design interviews. Most of the time concurrency and synchronization are abstracted away within certain technologies and you don’t need to worry about it, just like how in high-level programming languages, memory management is abstracted away. Take a simple CRUD web application for example, web servers take care of managing a thread pool and assigning threads for incoming requests. On the storage side, a relational database handles race conditions and force constraints for us. For example, for a table with an auto-increment ID, it guarantees no two requests can generate the same ID.
You don’t need to worry about concurrency and synchronization within a web server or relational database. But it doesn’t mean you never need to design anything about concurrency and synchronization. Here I want to share a real-world project I worked on before. A little bit of context, it is a fintech app, and we store users’ bank account numbers in our database. We need to encrypt the account number before storing it and decrypt it when needing to send out payments, which happens in batch. We want to design a key management service, which has the following functionalities
- Generate a new key pair (we use asymmetric encryption)
- Rotate key pairs, i.e., decrypt all users’ bank account numbers using the old private key and encrypt using the new public key.
When a new user registers, her bank account needs to be encrypted using the existing key. We need to send out payments to our users regularly, which requires decrypting the account number. Among all these use cases, synchronization is required to prevent race conditions that would result in an invalid state. For example, if someone adds/updates her bank account while we are rotating keys, it’s possible that her account number is encrypted with the old key while all other users are encrypted with the new key, leaving our data in an invalid state. Next time when we need to pay out to our users, we will find that that specific user’s account can’t be decrypted because we are using the wrong key. Thus we need synchronization, specifically, we need an application-level lock to synchronize. Since we were already using MySQL, we decided to use MySQL’s built-in locking functions. When a user needs to add/update her bank account, it needs to get a lock. When we need to do key rotation, it also needs to get the same lock. This effectively prevents these two use cases from occurring at the same time.