
System Architecture: Distributed task scheduling service
Microservices/event-driven worker-based architecture of highly scalable distributed task scheduling service

Key Features of System
- Task Submission and Management: Provides APIs for clients to submit tasks with metadata like priority, type, and deadline, and manages task queuing until execution.
2. Dynamic Scheduling: Dynamically assigns tasks to workers based on real-time availability, worker capacity, and task-specific requirements.
3. Worker Registration and Health Monitoring: Supports worker registration with capabilities and continuously monitors worker health via heartbeat signals to ensure reliability.
4. Task Execution and Status Tracking: Executes tasks on assigned workers and allows clients to query task progress, status (e.g., queued, in-progress, completed), and results.
5. Retry and Failure Management: Automatically retries failed tasks up to a configurable limit and moves permanently failed tasks to a Dead Letter Queue (DLQ) for recovery or analysis.
6. Real-Time Monitoring and Metrics: Collects and aggregates metrics like task processing times, queue depth, worker utilization, and failure rates, providing real-time visibility through dashboards.
7. Auto-Scaling and Load Balancing: Dynamically scales the worker pool based on system demand and evenly distributes tasks to prevent overload and maintain throughput.
Proposed system architecture: Microservices-based, event-driven architecture
Why ?
i. Microservices-Based Architecture: Modular, loosely coupled services, each focused on a specific domain like Task Submission, Scheduler, Worker Management, and Monitoring. ii. Event-Driven Communication: Central Event Bus (e.g., Kafka) facilitates asynchronous interactions for real-time responsiveness and high-throughput workloads. iii. Scalability and Fault Tolerance: Services are independently scalable, and event-driven design ensures resilience to component failures. iv. Dynamic Worker Management: Worker pools with auto-scaling capabilities dynamically adjust resources based on system demand, optimizing performance and cost. v. Robust Storage Layer: Includes relational databases for task persistence and time-series databases for metrics aggregation, ensuring durability and observability. vi. Real-Time Observability: Monitoring services and dashboards provide visibility into system performance, metrics, and failures. vii. Optimized for Distributed Workflows: Combines the flexibility of microservices with the resilience of event-driven design to handle complex, distributed processes efficiently.
High Level Architecture
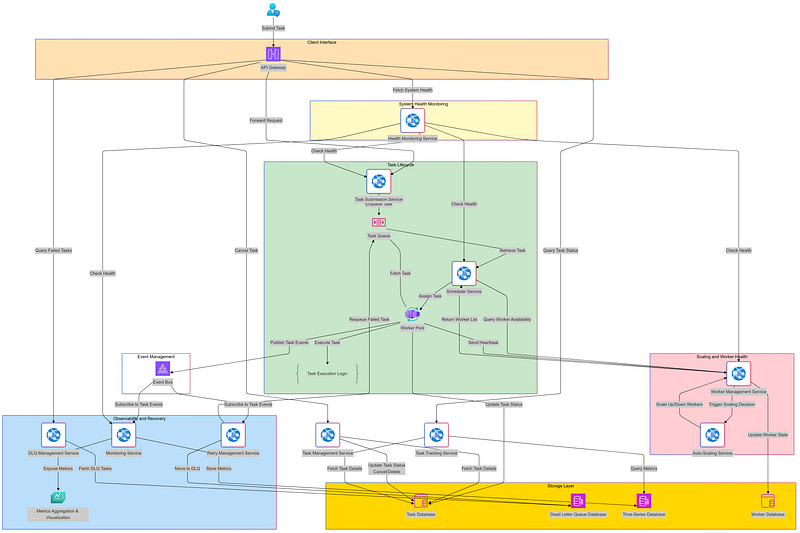
Core Services
1. Task Submission Service : It manages the submission of tasks into the system. This acts as the entry point for task submission into the system.
Responsibilities:
- Validate and authenticate incoming task requests.
- Assign unique
Task IDsfor tracking. - Enqueue tasks into the Task Queue with metadata like priority and client details.
- Provide acknowledgment to clients with the
Task ID.
2. Task Tracking Service : This service provides visibility into the status and lifecycle of tasks along with task progress.
Responsibilities:
- Fetch task details from the Task Database, including status (
queued,in-progress,completed,failed). - Retrieve task results and metadata for completed tasks.
- Expose APIs for querying task status by
Task ID.
3. Scheduler Service : This service assigns tasks from the queue to available workers.
Responsibilities:
- Retrieve tasks from the Task Queue.
- Query the Worker Management Service to identify suitable workers.
- Apply scheduling policies (e.g., priority-based, round-robin).
- Assign tasks to workers, ensuring efficient utilization.
- Handle task reassignment in case of worker failures.
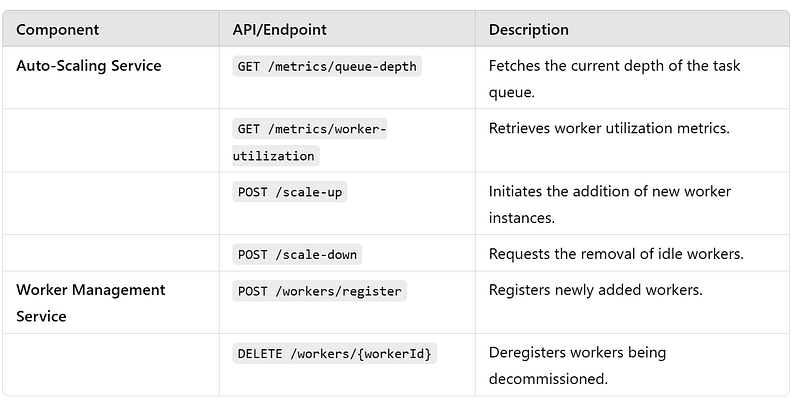
5. Worker Management Service : This service manages worker registration, health, and lifecycle.
Responsibilities:
- Register, deregister, and update worker metadata.
- Monitor worker health through periodic heartbeats.
- Track worker load and capacity to ensure proper task assignment.
- Integrate with the Auto-Scaling Service for dynamic worker scaling.
6. Monitoring Service : This service provides observability into the system’s health and performance.
Responsibilities:
- Aggregate and store metrics like task processing rates, worker utilization, and queue depth.
- Generate real-time visualizations on the Metrics Dashboard.
- Trigger alerts for SLA violations or system failures.
7. Health Monitoring Service : This services ensures the readiness and availability of the system’s components.
Responsibilities:
- Perform readiness and liveness checks for services like the Scheduler, Task Queue, and Worker Pool.
- Expose detailed health reports through APIs for external monitoring tools.
8. Event Management Service : This service manages events for inter-service communication and system observability.
Responsibilities:
- Publish and subscribe to events such as:
TaskQueued,TaskAssigned,TaskCompleted,TaskFailed,WorkerRegistered,WorkerFailed.- Ensure event durability and replayability for fault tolerance.
- Route events to appropriate services (e.g., Monitoring, Retry Manager).
9. Retry Management Service : This service handles retries for failed tasks and workers.
Responsibilities:
- Detect failed tasks and requeue them into the Task Queue.
- Manage retry policies (e.g., exponential backoff, retry limits).
- Move tasks exceeding retry limits to the Dead Letter Queue (DLQ).
- Expose APIs for manual intervention or retry of tasks in the DLQ.
12. Dead Letter Queue (DLQ) Management Service : This service provides visibility and control over tasks that failed permanently.
Responsibilities:
- List tasks in the DLQ with failure reasons.
- Enable manual reprocessing or deletion of failed tasks.
- Expose APIs for querying and interacting with DLQ tasks.
13. Auto-Scaling Service : This service dynamically manages the size of the worker pool.
Responsibilities:
- Monitor system load indicators like queue depth and task arrival rates.
- Scale up or down the worker pool to handle varying workloads.
- Register newly scaled workers with the Worker Management Service.
14. Task Management Service : This service allows clients to manage tasks post-submission.
Responsibilities:
- Cancel Tasks: Cancel tasks that are still in the queue but not yet assigned or executed.
- Retry Tasks: Requeue tasks that failed during execution, ensuring idempotency where applicable.
- Pause/Resume Tasks : Pause tasks or workflows and resume them later as required by business logic.
Workflows
a. Task Submission Workflow : The Task Submission Workflow is responsible for ensuring that tasks submitted by clients are validated, queued, and acknowledged. It provides the foundation for all subsequent workflows by ensuring tasks enter the system reliably and efficiently.
APIs and Events
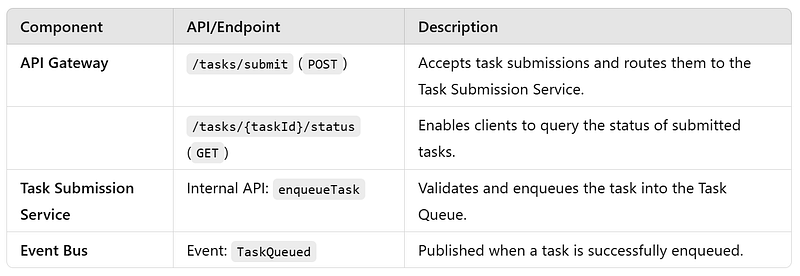
Events

DB Details
Database Type: PostgreSQL (Relational Database)
Reason for Choosing PostgreSQL
i. Structured Data: Tasks have a well-defined schema with fields like taskId, status, timestamps, and metadata.
ii. ACID Compliance: Guarantees transactional integrity, critical for operations like task insertion and status updates.
iii. Complex Queries: PostgreSQL supports advanced querying for task tracking, filtering, and reporting (e.g., by status or priority).
DB Schema
CREATE TABLE tasks (
task_id UUID PRIMARY KEY, -- Unique ID for the task
client_id VARCHAR(255) NOT NULL, -- Identifier for the client submitting the task
payload JSONB NOT NULL, -- Task-specific payload in JSON format
metadata JSONB, -- Additional metadata (e.g., priority, retries)
status VARCHAR(50) DEFAULT 'queued', -- Task status (queued, in-progress, completed, failed)
created_at TIMESTAMP DEFAULT NOW(), -- Task creation timestamp
updated_at TIMESTAMP DEFAULT NOW(), -- Last updated timestamp
priority INT DEFAULT 1, -- Priority of the task (1 = highest, n = lowest)
retries INT DEFAULT 0 -- Number of retry attempts
);
Indexing
i. Primary Key Index on task_id: Automatically created due to PRIMARY KEY constraint.
Ensures fast lookups for operations like fetching specific task details.
CREATE UNIQUE INDEX idx_task_id ON tasks (task_id);
ii. Index on status:
Facilitates quick filtering by task status (e.g., queued, in-progress, completed).
CREATE INDEX idx_task_status ON tasks (status);
iii. Index on priority:Optimizes queries that order or filter tasks by priority.
CREATE INDEX idx_task_priority ON tasks (priority);Following is the sequence of operations involving core components, services for Task Submission Workflow.
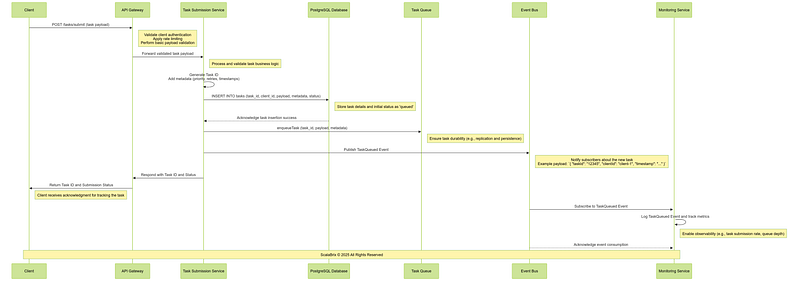
Critical Design Considerations
i. The Task Queue must guarantee durability (e.g., at-least-once delivery) to ensure tasks are not lost.
ii. The API Gateway and Task Submission Service should be stateless and horizontally scalable to handle large volumes of submissions.
iii. Ensure that repeated submissions of the same task (e.g., due to client retries) do not create duplicates by using Task ID deduplication mechanisms.
b. Task Scheduling Workflow : The Task Scheduling Workflow is responsible for assigning tasks from the Task Queue to workers in a way that optimizes resource utilization, respects priority levels, and ensures reliability. It is central to the execution phase of the system.
APIs
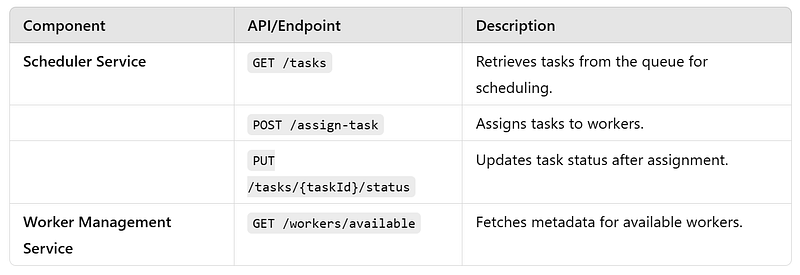
Events
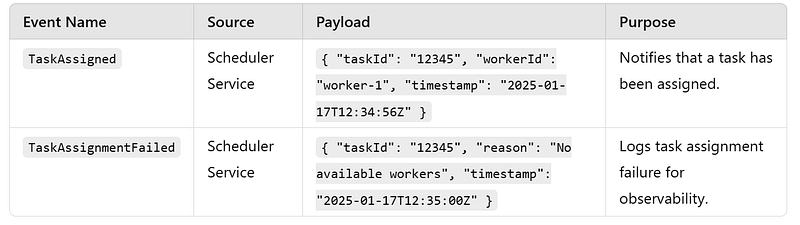
DB Details
Database Type: PostgreSQL (Relational Database)
Reason for Choosing PostgreSQL
i. Structured and Transactional Data: Task scheduling requires strict schemas for tasks, workers, and their relationships. PostgreSQL’s ACID compliance ensures data consistency and reliability for task status updates and assignments.
ii. Complex Queries: Efficient querying for task prioritization, worker availability, and load balancing (e.g., ORDER BY priority, WHERE status = 'queued').
DB Schema
CREATE TABLE tasks (
task_id UUID PRIMARY KEY, -- Unique task identifier
client_id VARCHAR(255) NOT NULL, -- Identifier for the client
payload JSONB NOT NULL, -- Task-specific payload
metadata JSONB, -- Additional metadata (e.g., priority, timestamps)
status VARCHAR(50) DEFAULT 'queued', -- Task status (queued, in-progress, completed)
worker_id UUID, -- Worker assigned to the task
priority INT DEFAULT 1, -- Priority of the task (1 = highest)
created_at TIMESTAMP DEFAULT NOW(), -- Creation timestamp
updated_at TIMESTAMP DEFAULT NOW() -- Last updated timestamp
);
CREATE TABLE workers (
worker_id UUID PRIMARY KEY, -- Unique worker identifier
capabilities JSONB NOT NULL, -- Worker capabilities (e.g., supported task types)
status VARCHAR(50) DEFAULT 'available', -- Worker status (available, busy, unhealthy)
current_load INT DEFAULT 0, -- Current number of assigned tasks
last_heartbeat TIMESTAMP DEFAULT NOW() -- Last heartbeat timestamp
);
Indexing
i. Primary Key Indexes on task_id and worker_id:
Automatically created by PostgreSQL for primary keys.
Ensure efficient lookups for tasks and workers.
CREATE UNIQUE INDEX idx_task_id ON tasks (task_id);
CREATE UNIQUE INDEX idx_worker_id ON workers (worker_id);
ii. Index on status for Task Retrieval:
Speeds up filtering tasks by status (queued, in-progress, etc.).
CREATE INDEX idx_task_status ON tasks (status);
iii. Compound Index on status and priority:
Optimizes queries that filter tasks by status and order them by priority.
CREATE INDEX idx_status_priority ON tasks (status, priority);
iv. Index on worker_id in the tasks table:
Facilitates efficient retrieval of tasks assigned to a specific worker.
CREATE INDEX idx_task_worker ON tasks (worker_id);
Following is the sequence of operations involving core components, services for Task Scheduling Workflow.
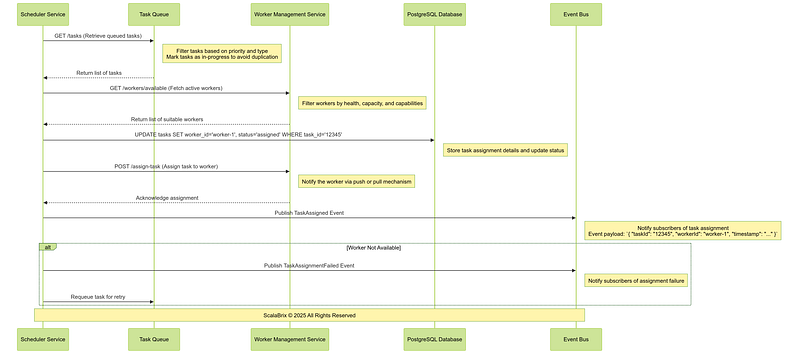
Critical Design Considerations
i. Implement prioritization in task retrieval to ensure high-priority tasks are assigned first. Use priority queues or separate task partitions for different priority levels.
ii. Allow multiple schedulers to operate concurrently using distributed locks or partitioned task queues. Ensure task consistency across schedulers to prevent duplication.
iii. Implement retry mechanisms for failed task assignments. Maintain idempotency to handle retries safely without duplicating tasks.
c. Task Execution Workflow : The Task Execution Workflow is the process where workers take ownership of assigned tasks, execute them, and ensure their status is updated in the system. It is the core operational phase of the system, converting queued tasks into actionable results.
APIs

Events
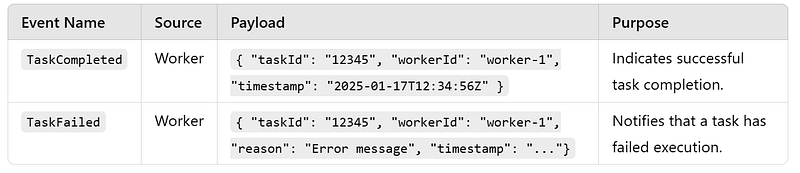
DB Details
Database Type: PostgreSQL (Relational Database)
Reason for Choosing PostgreSQL
i. Structured Data: Task execution requires strict schema definitions for tracking task status, worker performance, and retries. PostgreSQL enforces constraints, ensuring referential integrity (e.g., tasks referencing workers). ii. Transaction Support: PostgreSQL supports ACID transactions, ensuring reliable updates for task status changes.
Database Schema and Query
-- Tasks Table
CREATE TABLE tasks (
task_id UUID PRIMARY KEY, -- Unique identifier for each task
client_id VARCHAR(255) NOT NULL, -- Client submitting the task
payload JSONB NOT NULL, -- Task-specific payload
metadata JSONB, -- Metadata (e.g., priority, timestamps)
status VARCHAR(50) DEFAULT 'queued', -- Task status (e.g., queued, in-progress, completed, failed)
assigned_worker_id UUID, -- Reference to the assigned worker
retries INT DEFAULT 0, -- Number of retries attempted
created_at TIMESTAMP DEFAULT NOW(), -- Creation timestamp
updated_at TIMESTAMP DEFAULT NOW(), -- Last update timestamp
CONSTRAINT fk_worker FOREIGN KEY (assigned_worker_id)
REFERENCES workers (worker_id) -- Foreign key to workers table
);
-- Workers Table
CREATE TABLE workers (
worker_id UUID PRIMARY KEY, -- Unique identifier for each worker
capabilities JSONB NOT NULL, -- Capabilities of the worker (e.g., supported task types)
status VARCHAR(50) DEFAULT 'available', -- Worker status (e.g., available, busy, unhealthy)
current_load INT DEFAULT 0, -- Current load of the worker
last_heartbeat TIMESTAMP DEFAULT NOW() -- Last heartbeat timestamp
);
-- Indexes for Optimization
CREATE INDEX idx_task_status ON tasks (status);
CREATE INDEX idx_worker_status ON workers (status);
CREATE INDEX idx_task_priority ON tasks ((metadata->>'priority')); -- JSONB priority index
Query and Index Optimization
i. Task Querying:
SELECT * FROM tasks
WHERE status = 'queued'
ORDER BY (metadata->>'priority')::INT DESC, created_at ASC
LIMIT 1
FOR UPDATE SKIP LOCKED;
Index Used: idx_task_status, idx_task_priority.
ii. Worker querying:
SELECT * FROM workers
WHERE status = 'available'
AND current_load < (metadata->>'capacity')::INT
ORDER BY current_load ASC
LIMIT 1;
Index Used: idx_worker_status.
iii. Task Status Update:
UPDATE tasks
SET status = 'in-progress', updated_at = NOW()
WHERE task_id = '123e4567-e89b-12d3-a456-426614174000';Following is the sequence of operations involving core components, services for Task execution Workflow.
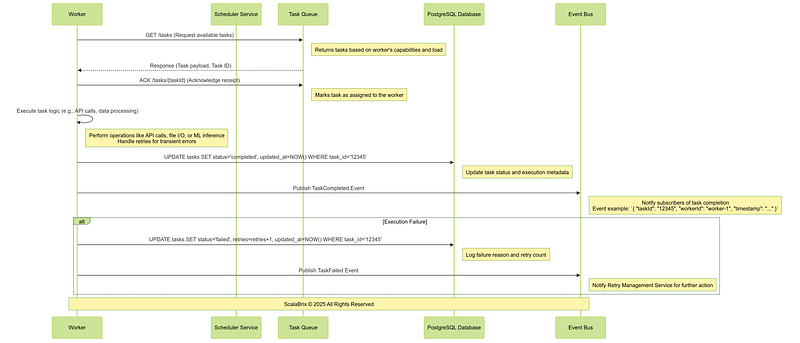
Critical Design Considerations
i. Ensure tasks can be executed multiple times without adverse effects (e.g., avoid duplicate processing).
ii. Allow workers to handle multiple tasks concurrently using threading or asynchronous execution.
iii. Ensure events (TaskCompleted, TaskFailed) are delivered reliably, even during failures.
d. Task Monitoring Workflow : The Task Monitoring Workflow ensures visibility into the system’s operations, including task progress, worker health, and system performance. It provides observability and helps identify anomalies, SLA violations, and system bottlenecks.
APIs

Events

DB Details
Database Type: Time-Series Database (e.g., InfluxDB, Prometheus TSDB)
Why Time-Series Database?
- Data Characteristics: Metrics are time-stamped and require high-frequency writes (e.g., task events, worker heartbeats, queue depth). Time-series databases are optimized for temporal queries like aggregations over specific time ranges.
- High Write Throughput: Handles high-frequency event writes with low latency. Ensures real-time ingestion of task lifecycle events and metrics.
Schema for time servies metrics
Measurement: task_events
Tags:
- taskId: Unique task identifier
- eventType: Type of event (e.g., TaskQueued, TaskCompleted, TaskFailed)
- workerId: Worker processing the task
- clientId: Client identifier
Fields:
- value: Numeric indicator (e.g., 1 for events, 0 for alerts)
- latency: Processing time in milliseconds (for TaskCompleted events)
- reason: Failure reason (for TaskFailed events)
Timestamp:
- Event timestamp (e.g., 2025-01-17T12:34:56Z)
Query Optimizations
i. Throughput Over Time :
SELECT COUNT(taskId)
FROM task_events
WHERE eventType = 'TaskCompleted'
AND time >= now() - 1h
GROUP BY time(1m)
ii. Failure Rate by Client:
SELECT COUNT(taskId)
FROM task_events
WHERE eventType = 'TaskFailed'
AND time >= now() - 24h
GROUP BY clientIdFollowing is the sequence of operations involving core components, services for Task Monitoring Workflow.
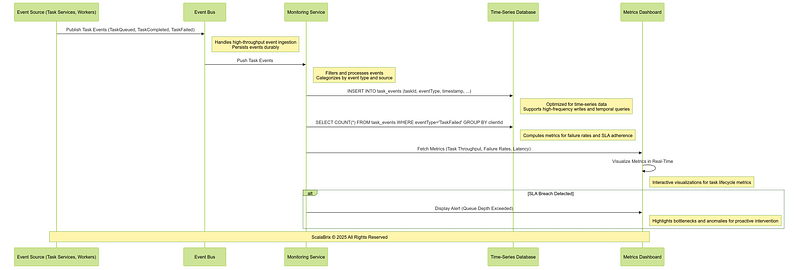
Critical Design Considerations
i. Ensure the Monitoring Service can handle a high volume of events during peak loads. Use partitioning and replication in the Event Bus to distribute the load.
ii. Define log retention periods to balance storage costs and debugging needs (e.g., retain 30 days of logs).
iii. Ensure the Monitoring Service can recover from failures and replay missed events using durable event logs in the Event Bus.
e. Task Retry Workflow : The Task Retry Workflow ensures system reliability by reprocessing tasks that have failed during execution. It uses configurable retry policies to recover from transient failures while preventing repeated processing of permanently failed tasks by moving them to a Dead Letter Queue (DLQ).
APIs
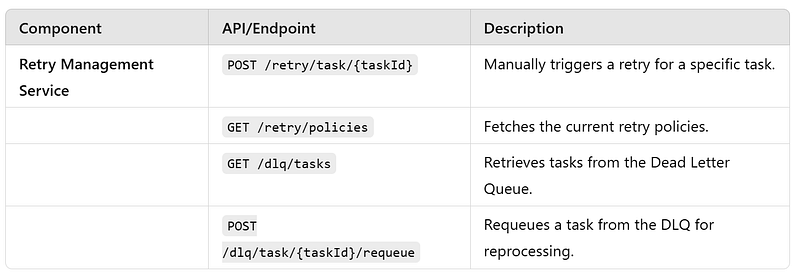
Events
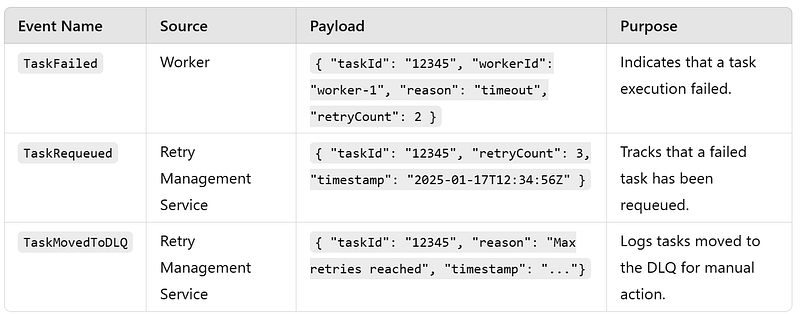
DB Details
Database Choice:
- a. Relational Database (PostgreSQL) for primary task and DLQ management.
- b. Time-Series Database (InfluxDB/Prometheus) for tracking retry metrics and event patterns.
Why PostgreSQL for DLQ?
- ACID Compliance: Ensures transactional integrity during task retry updates and moves to the DLQ.
2. Structured Data: DLQ requires strict schemas for retry counts, failure reasons, timestamps, and related metadata.
3. Flexibility for Querying: Supports querying DLQ by task status, retry attempts, and failure reasons for manual and automated processing.
DB Schema
i. Tasks table:
CREATE TABLE tasks (
task_id UUID PRIMARY KEY, -- Unique task identifier
client_id VARCHAR(255) NOT NULL, -- Client submitting the task
payload JSONB NOT NULL, -- Task-specific payload
metadata JSONB, -- Metadata (e.g., priority, timestamps)
status VARCHAR(50) DEFAULT 'queued', -- Task status (e.g., queued, in-progress, failed, completed)
retries INT DEFAULT 0, -- Number of retry attempts
max_retries INT DEFAULT 5, -- Maximum allowed retries
failure_reason TEXT, -- Reason for task failure
created_at TIMESTAMP DEFAULT NOW(), -- Creation timestamp
updated_at TIMESTAMP DEFAULT NOW() -- Last update timestamp
);
ii. Dead letter queue table:
CREATE TABLE dead_letter_queue (
task_id UUID PRIMARY KEY, -- Unique task identifier
client_id VARCHAR(255) NOT NULL, -- Client who owns the task
payload JSONB NOT NULL, -- Original task payload
failure_reason TEXT, -- Final failure reason
retry_count INT, -- Number of retries attempted
last_attempt_at TIMESTAMP DEFAULT NOW(), -- Timestamp of the last retry attempt
moved_to_dlq_at TIMESTAMP DEFAULT NOW() -- Timestamp when moved to DLQ
);
Time-Series Schema for Metrics (InfluxDB)
Measurement: task_retry_metrics
Tags:
- taskId: Unique task identifier
- eventType: Retry-related events (e.g., TaskFailed, TaskRequeued, TaskMovedToDLQ)
- clientId: Client identifier
Fields:
- retryCount: Number of retries attempted
- failureReason: Reason for the task failure
- latency: Time between task creation and failure/retry
Timestamp:
- Time of event occurrence
Query and Index Optimization
i. Index on task status for fast retrieval:
CREATE INDEX idx_task_status ON tasks (status);
ii. Index on retry counts to fetch tasks nearing the retry limit:
CREATE INDEX idx_task_retries ON tasks (retries);
iii. Index on DLQ timestamps for monitoring:
CREATE INDEX idx_dlq_moved_at ON dead_letter_queue (moved_to_dlq_at);Following is the sequence of operations involving core components, services for Task retry Workflow.
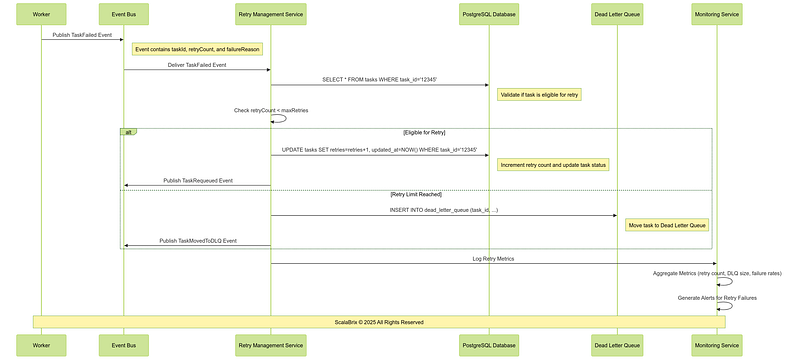
Critical Design Considerations
i. Ensure task operations can be safely retried without causing duplicates or inconsistent results.
ii. Maintain a scalable and queryable DLQ to handle large volumes of failed tasks. Provide manual and automated mechanisms for task reprocessing or deletion.
iii. Implement exponential backoff and jitter to prevent overloading the system during mass failures.
f. Task Query Workflow : The Task Query Workflow allows clients to retrieve the current status or results of submitted tasks. This ensures transparency and accountability, enabling clients to monitor task progress or retrieve outputs upon completion.
APIs

Events : No direct events are required in the Task Query Workflow as it is request-response driven. However, related events that feed into the Storage Layer include:
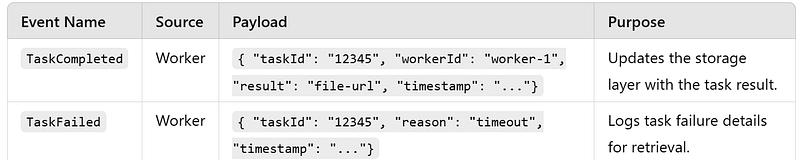
DB Details
Database Type: PostgreSQL (Relational Database)
Reason for Choosing PostgreSQL
- Structured and Transactional Data: Task metadata, status, timestamps, and results require a structured schema. PostgreSQL’s ACID compliance ensures reliable updates for task state changes and query consistency.
2. Indexing for Fast Retrieval: PostgreSQL supports advanced indexing (e.g., B-tree, GIN for JSONB) for optimized queries on task IDs and metadata.
DB Schema
CREATE TABLE tasks (
task_id UUID PRIMARY KEY, -- Unique identifier for each task
client_id VARCHAR(255) NOT NULL, -- Identifier for the client submitting the task
payload JSONB NOT NULL, -- Task-specific payload
status VARCHAR(50) DEFAULT 'queued', -- Task status (e.g., queued, in-progress, completed, failed)
result JSONB, -- Task result or output
metadata JSONB, -- Additional metadata (e.g., priority, retries, timestamps)
created_at TIMESTAMP DEFAULT NOW(), -- Task creation timestamp
updated_at TIMESTAMP DEFAULT NOW() -- Last update timestamp
);
Sample JSON for Task Result
{
"taskId": "123e4567-e89b-12d3-a456-426614174000",
"status": "completed",
"result": {
"output_url": "https://example.com/results/12345",
"size": "25MB"
},
"metadata": {
"priority": "high",
"retries": 1,
"timestamps": {
"queued_at": "2025-01-17T12:00:00Z",
"completed_at": "2025-01-17T12:10:00Z"
}
}
}
Indexing
i. Task Status Index: To efficiently retrieve tasks by status.
CREATE INDEX idx_task_status ON tasks (status);
ii. Task ID Index: For fast primary key lookups during task queries.
CREATE UNIQUE INDEX idx_task_id ON tasks (task_id);
iii. JSONB Metadata Index: For querying dynamic metadata fields like priority or retries.
CREATE INDEX idx_task_metadata_priority ON tasks ((metadata->>'priority'));Following is the sequence of operations involving core components, services for Task query Workflow.
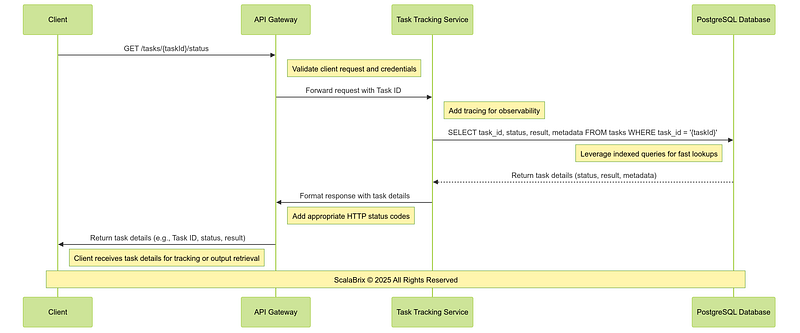
Critical Design Considerations
i. Ensure that the Storage Layer reflects the most up-to-date task status and results using eventual or strong consistency mechanisms.
ii. Design the Task Tracking Service to handle high query loads by implementing: Indexing in the Storage Layer for fast lookups, Read replicas for distributing database queries.
iii. Enforce strict access controls to ensure only authorized clients can query specific tasks.
g. Task Cancellation Workflow : The Task Cancellation Workflow allows clients to cancel tasks that are still in the queue and not yet executed or assigned to a worker. It ensures operational flexibility and prevents unnecessary processing of obsolete tasks.
APIs
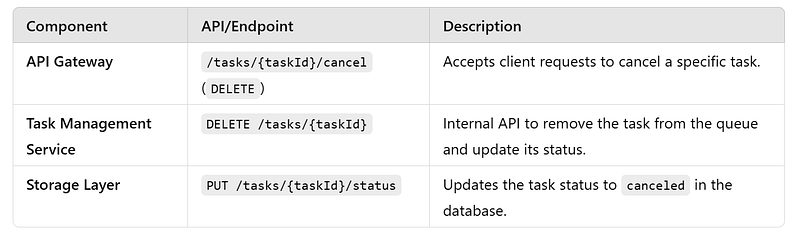
Events

DB Details
Database Type: PostgreSQL (Relational Database)
Reason for Choosing PostgreSQL
- Transactional Integrity: PostgreSQL ensures consistency during updates to task status and queue operations via ACID-compliant transactions.
- Concurrent Access Handling: Features like
SELECT FOR UPDATEallow safe concurrent access for task cancellation requests.
3. Structured Schema: Cancellations and task lifecycle updates benefit from PostgreSQL’s ability to enforce schema constraints.
DB Schema
CREATE TABLE tasks (
task_id UUID PRIMARY KEY, -- Unique identifier for each task
client_id VARCHAR(255) NOT NULL, -- Identifier for the client
payload JSONB NOT NULL, -- Task payload
status VARCHAR(50) DEFAULT 'queued', -- Task status (queued, in-progress, canceled)
metadata JSONB, -- Additional metadata (e.g., priority, timestamps)
cancellation_reason TEXT, -- Reason for cancellation
created_at TIMESTAMP DEFAULT NOW(), -- Creation timestamp
updated_at TIMESTAMP DEFAULT NOW() -- Last updated timestamp
);
Sample JSON for metadata
{
"priority": "high",
"timestamps": {
"queued_at": "2025-01-17T12:00:00Z",
"canceled_at": "2025-01-17T12:15:00Z"
}
}
Indexing
i. Task ID Index: For fast lookup during cancellation.
CREATE UNIQUE INDEX idx_task_id ON tasks (task_id);
ii. Task Status Index: For efficient filtering of tasks in the queued state.
CREATE INDEX idx_task_status ON tasks (status);
iii. Cancellation Reason Search: Use JSONB indexing for querying metadata fields like cancellation timestamps.
CREATE INDEX idx_task_metadata ON tasks USING gin (metadata);Following is the sequence of operations involving core components, services for Task cancellation Workflow.
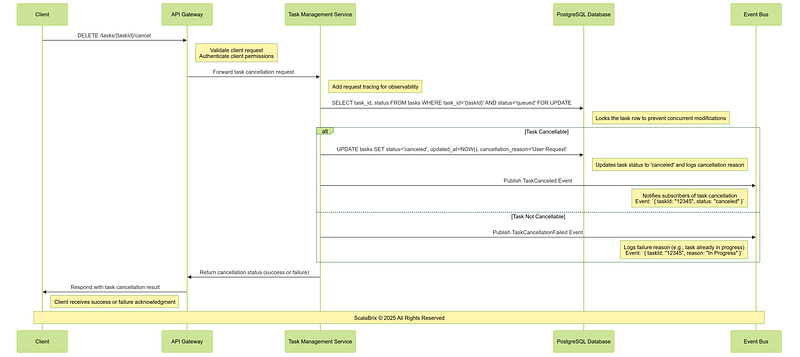
Critical Design Considerations
i. Ensure that repeated cancellation requests for the same task do not cause errors or duplicate processing.
ii. Ensure the task status update and removal from the queue happen as a single atomic operation to prevent inconsistencies.
iii. Use real-time state data from the Task Queue or Storage Layer to determine whether the task can still be canceled.
h. Dead Letter Queue (DLQ) Management Workflow : The Dead Letter Queue (DLQ) Management Workflow provides visibility into tasks that could not be processed successfully after multiple retries. It allows clients or administrators to view these tasks, understand the failure reasons, and take corrective actions like reprocessing or deletion.
APIs

Events

DB Details
Database Type: PostgreSQL (Relational Database)
Reason for Choosing PostgreSQL
i. ACID Compliance: Ensures reliable updates during task requeueing, deletion, and DLQ processing.
ii. Complex Querying: Supports filtering, aggregations, and advanced queries for monitoring DLQ contents (e.g., tasks by failure reason or client).
DB Schema and Indexing
CREATE TABLE dead_letter_queue (
task_id UUID PRIMARY KEY, -- Unique task identifier
client_id VARCHAR(255) NOT NULL, -- Identifier of the client
payload JSONB NOT NULL, -- Original task payload
failure_reason TEXT NOT NULL, -- Reason for the task failure
retry_count INT, -- Number of retries attempted
created_at TIMESTAMP DEFAULT NOW(), -- Task creation timestamp
moved_to_dlq_at TIMESTAMP DEFAULT NOW(), -- Timestamp when moved to DLQ
last_attempt_at TIMESTAMP -- Timestamp of the last retry attempt
);
JSON payload example
{
"taskId": "12345",
"clientId": "client-1",
"payload": {
"taskType": "data_processing",
"input": "s3://bucket/input.csv",
"output": "s3://bucket/output.csv"
},
"failureReason": "Max retries reached",
"retryCount": 5,
"movedToDLQAt": "2025-01-17T12:00:00Z",
"lastAttemptAt": "2025-01-17T11:59:59Z"
}
Indexing
1. Task ID Index: Optimizes retrieval of specific tasks by their ID.
CREATE UNIQUE INDEX idx_dlq_task_id ON dead_letter_queue (task_id);
2. Client ID Index: For querying tasks by client.
CREATE INDEX idx_dlq_client_id ON dead_letter_queue (client_id);
3. Failure Reason Index: Enables fast filtering by failure reason.
CREATE INDEX idx_dlq_failure_reason ON dead_letter_queue (failure_reason);Following is the sequence of operations involving core components, services for DLQ management Workflow.
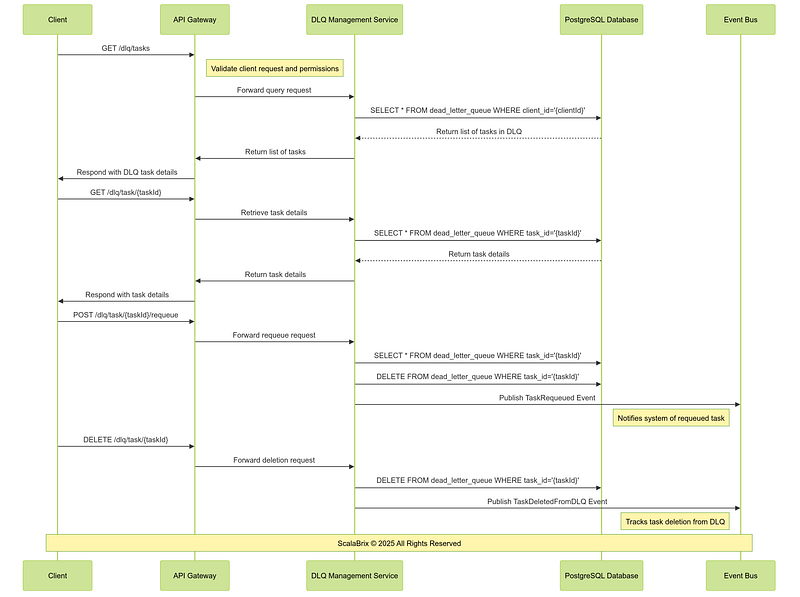
Critical Design Considerations
i. Provide APIs for listing and filtering tasks in the DLQ based on criteria like taskId, failureReason, timestamp, and retryCount.
ii. Restrict DLQ operations (e.g., requeue, delete) to authorized users or roles (e.g., system admins).
iii. Design the DLQ to handle large volumes of failed tasks without performance degradation. Use indexing for efficient querying.
i. Worker Registration Workflow : The Worker Registration Workflow ensures that workers dynamically join and leave the system, enabling scalability, fault tolerance, and efficient resource management. It maintains an up-to-date registry of active workers, their capabilities, and their health statuses.
APIs
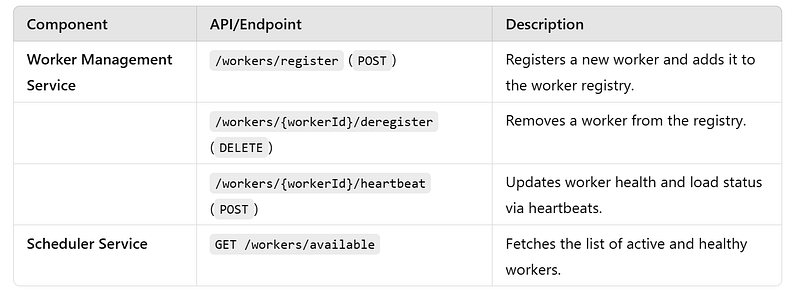
Events

DB Details
Database Type: PostgreSQL (Relational Database)
Reason for Choosing PostgreSQL
i. Structured Data: Worker metadata (e.g., capabilities, capacity, status) requires a well-defined schema for validation and consistency.
ii. Transaction Support: Ensures atomic updates when registering, updating, or deregistering workers, especially during concurrent operations.
DB Schema and indexing
Workers table:
CREATE TABLE workers (
worker_id UUID PRIMARY KEY, -- Unique worker identifier
capabilities JSONB NOT NULL, -- Worker capabilities (e.g., supported task types)
capacity INT DEFAULT 0, -- Maximum tasks worker can handle
status VARCHAR(50) DEFAULT 'available', -- Worker status (e.g., available, busy, unhealthy)
current_load INT DEFAULT 0, -- Current number of tasks being handled
last_heartbeat TIMESTAMP DEFAULT NOW(), -- Last heartbeat timestamp
registered_at TIMESTAMP DEFAULT NOW(), -- Registration timestamp
updated_at TIMESTAMP DEFAULT NOW() -- Last update timestamp
);
Sample JSON for Capabilities
{
"taskTypes": ["data_processing", "ml_training"],
"region": "us-east-1",
"specialFeatures": ["gpu", "high_memory"]
}
Indexing
i. Worker Status Index: For retrieving active workers efficiently.
CREATE INDEX idx_worker_status ON workers (status);
ii. Worker Capabilities Index: For filtering workers based on their JSONB capabilities.
CREATE INDEX idx_worker_capabilities ON workers USING gin (capabilities);
iii. Last Heartbeat Index: To monitor worker health efficiently.
CREATE INDEX idx_worker_heartbeat ON workers (last_heartbeat);Following is the sequence of operations involving core components, services for worker registration Workflow.
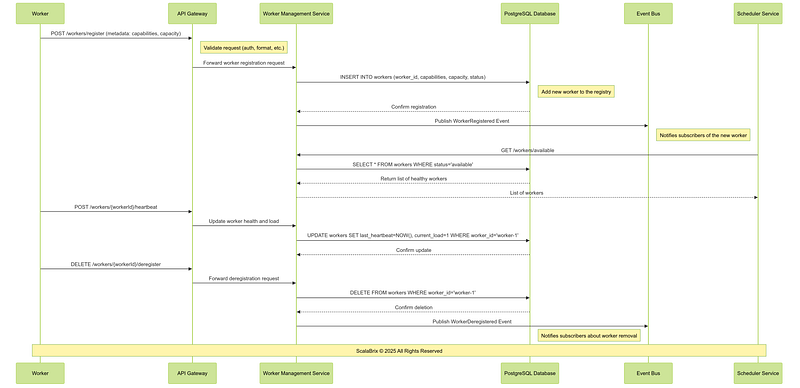
Critical Design Considerations
i. Support dynamic addition and removal of workers to handle scaling events without requiring manual intervention.
ii. Store detailed worker metadata to optimize task scheduling (e.g., task-to-worker matching based on capabilities).
iii. Ensure the worker registry can scale to handle a large number of workers in distributed environments.
j. Worker Health Monitoring Workflow : The Worker Health Monitoring Workflow ensures system reliability by continuously monitoring worker health and availability. It detects unresponsive workers, removes them from active scheduling, and initiates task reassignment to maintain operational continuity.
APIs

Events
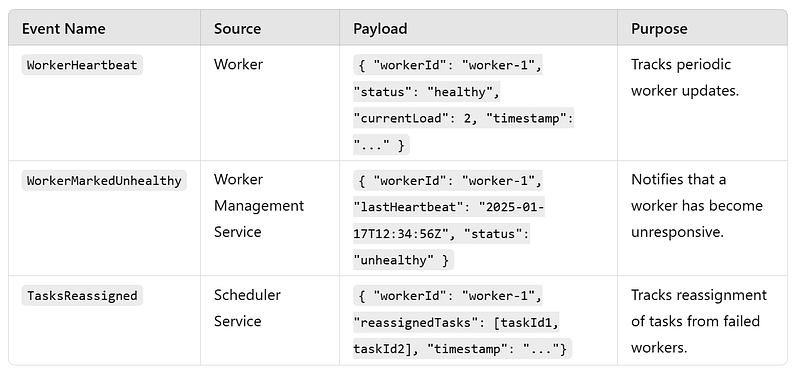
DB Details
Database Type: PostgreSQL (Relational Database)
Reason for Choosing PostgreSQL
i. Transactional Integrity: Ensures consistency during worker status updates and task reassignment in response to health changes.
ii. Structured Schema: Worker health monitoring involves clear relationships and attributes like workerId, lastHeartbeat, and status.
DB Schema and indexing
CREATE TABLE workers (
worker_id UUID PRIMARY KEY, -- Unique worker identifier
status VARCHAR(50) DEFAULT 'healthy', -- Worker health status (healthy, degraded, unhealthy)
current_load INT DEFAULT 0, -- Current number of tasks handled by the worker
capacity INT DEFAULT 10, -- Maximum tasks a worker can handle
last_heartbeat TIMESTAMP DEFAULT NOW(), -- Last heartbeat timestamp
metadata JSONB, -- Dynamic metadata (e.g., capabilities, region)
registered_at TIMESTAMP DEFAULT NOW(), -- Worker registration timestamp
updated_at TIMESTAMP DEFAULT NOW() -- Last update timestamp
);
Sample JSON for Metadata
{
"region": "us-west-1",
"capabilities": ["task-type-a", "task-type-b"]
}
Indexing
i. Worker Status Index: For retrieving unhealthy workers efficiently.
CREATE INDEX idx_worker_status ON workers (status);
ii. Last Heartbeat Index: Facilitates timely detection of unresponsive workers.
CREATE INDEX idx_last_heartbeat ON workers (last_heartbeat);
iii. Metadata Index: Enables querying worker capabilities using JSONB indexing.
CREATE INDEX idx_worker_metadata ON workers USING gin (metadata);Following is the sequence of operations involving core components, services for worker health management Workflow.
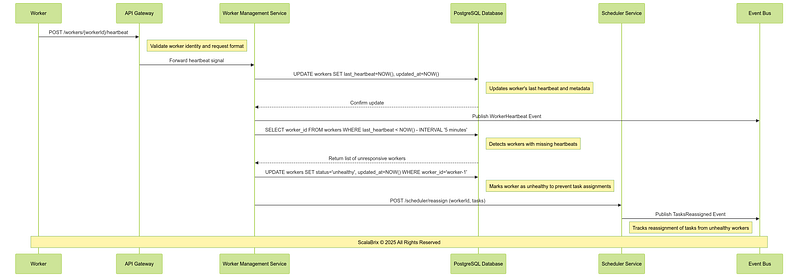
Critical Design Considerations
i. Ensure that the Worker Management Service is highly available and can handle a large volume of heartbeats simultaneously. Design for recovery of missed heartbeats during transient failures.
ii. Configure heartbeat intervals to balance responsiveness and overhead. Lower intervals improve failure detection but increase load.
iii. Use distributed data stores (e.g., etcd, Consul) for managing the worker registry in large-scale systems with thousands of workers.
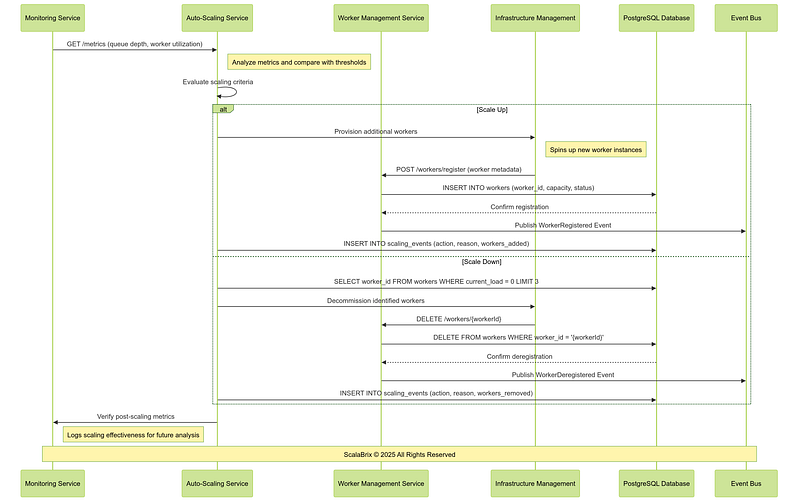
k. Auto-Scaling Workflow : The Auto-Scaling Workflow dynamically adjusts the size of the worker pool to meet system load demands. It ensures efficient resource utilization, cost control, and consistent task processing by scaling workers up or down based on key metrics like queue depth, task arrival rate, and worker utilization.
APIs
Events

DB Details
Database Type: PostgreSQL (Relational Database)
Reason for Choosing PostgreSQL
i. Structured Data: Worker registration, metrics, and scaling events have defined attributes that fit well into a relational schema.
ii. ACID Compliance: Ensures reliable updates for worker registration and scaling operations.
DB Schema and Indexing
CREATE TABLE workers (
worker_id UUID PRIMARY KEY, -- Unique identifier for the worker
status VARCHAR(50) DEFAULT 'available', -- Current status (available, busy, unhealthy)
capacity INT DEFAULT 0, -- Maximum tasks the worker can handle
current_load INT DEFAULT 0, -- Number of tasks currently assigned
capabilities JSONB, -- Capabilities (e.g., task types, special features)
registered_at TIMESTAMP DEFAULT NOW(), -- Registration timestamp
last_updated TIMESTAMP DEFAULT NOW() -- Last status update timestamp
);
CREATE TABLE scaling_events (
event_id SERIAL PRIMARY KEY, -- Unique event identifier
action VARCHAR(50), -- Scaling action (scale-up, scale-down)
reason TEXT, -- Reason for the scaling action
workers_added INT DEFAULT 0, -- Number of workers added
workers_removed INT DEFAULT 0, -- Number of workers removed
triggered_at TIMESTAMP DEFAULT NOW() -- Timestamp of the scaling event
);
Sample JSON for capabilities
{
"region": "us-west-1",
"task_types": ["data_processing", "ml_training"]
}
Indexing
1. Worker Status Index:
CREATE INDEX idx_worker_status ON workers (status);
2. Capabilities JSONB Index:
CREATE INDEX idx_worker_capabilities ON workers USING gin (capabilities);
3. Scaling Event Time Index:
CREATE INDEX idx_scaling_event_time ON scaling_events (triggered_at);Following is the sequence of operations involving core components, services for auto scaling Workflow.
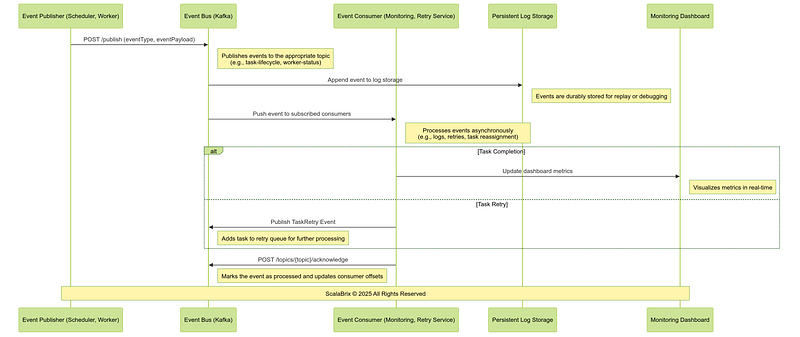
l. Event Notification Workflow : The Event Notification Workflow facilitates decoupled, asynchronous communication between system components through an Event Bus. This workflow ensures coordination, scalability, and observability by allowing components to publish and subscribe to events without tight coupling.
APIs

Events

DB Details
Database Type: Message Broker with Persistent Storage (Apache Kafka)
Why Kafka ?
i. Durability: Kafka provides built-in persistence for events, ensuring no data loss during failures.
ii. High Throughput: Capable of handling a large volume of events with low latency, ideal for asynchronous communication.
Event Schema
Schema defintion:
{
"eventType": "TaskAssigned",
"eventSource": "SchedulerService",
"eventPayload": {
"taskId": "12345",
"workerId": "worker-1",
"timestamp": "2025-01-17T12:34:56Z"
}
}
Schema Registry example:
{
"type": "record",
"name": "TaskAssigned",
"fields": [
{ "name": "eventType", "type": "string" },
{ "name": "eventSource", "type": "string" },
{
"name": "eventPayload",
"type": {
"type": "record",
"name": "Payload",
"fields": [
{ "name": "taskId", "type": "string" },
{ "name": "workerId", "type": "string" },
{ "name": "timestamp", "type": "string" }
]
}
}
]
}Query and Index Optimization
Kafka Configuration for Optimization
- Topic Partitioning: Partition by
eventTypeto ensure events of the same type are processed sequentially. - Retention Period: Configure
log.retention.hoursto retain events for debugging and replay. - Consumer Offsets: Use
enable.auto.commit=falseto allow manual control over offsets, ensuring reliable event processing.
Monitoring Kafka Topics
i. Fetch Events from a Topic:
kafka-console-consumer --topic task-events --from-beginning --bootstrap-server localhost:9092
ii.Check Partition Lag:
kafka-consumer-groups --describe --group task-group --bootstrap-server localhost:9092Following is the sequence of operations involving core components, services for event notification Workflow.
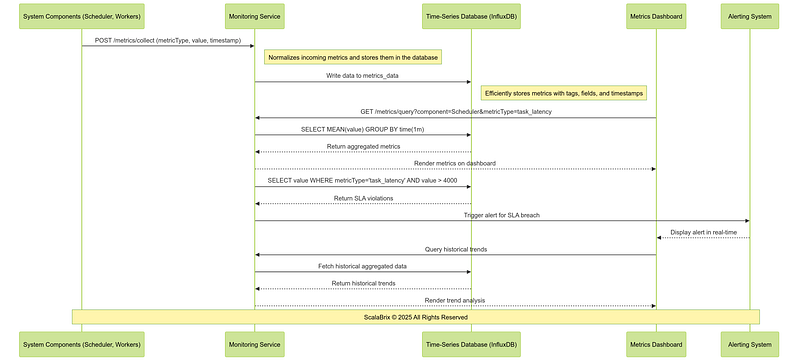
m. Metrics Aggregation Workflow: The Metrics Aggregation Workflow collects, processes, and visualizes performance data from various system components. It helps maintain system observability, monitor SLAs, and identify performance issues or bottlenecks in real time.
APIs
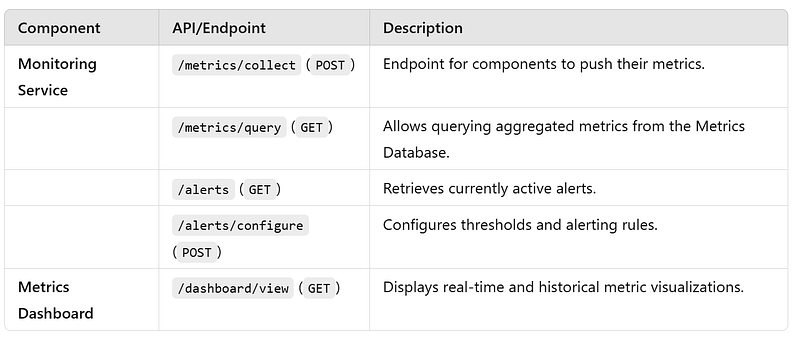
Events

DB Details
Database Type: Time-Series Database (InfluxDB or Prometheus TSDB)
Why Time-Series Database?
- Time-Stamped Data: Metrics have temporal attributes requiring efficient handling of high-frequency writes and queries.
- Optimized for Aggregations: Built-in functions for calculating averages, percentiles, and trends over time intervals.
Schema
Metrics Data (InfluxDB Example)
Measurement: metrics_data
Tags:
- component: Source of the metric (e.g., Scheduler, WorkerPool)
- metricType: Type of metric (e.g., task_latency, queue_depth)
Fields:
- value: Numeric value of the metric (e.g., latency in ms, queue depth count)
- unit: Measurement unit (e.g., ms, count)
Timestamp:
- Time the metric was captured.
Sample Json data
{
"measurement": "metrics_data",
"tags": {
"component": "Scheduler",
"metricType": "task_latency"
},
"fields": {
"value": 250,
"unit": "ms"
},
"timestamp": "2025-01-17T12:34:56Z"
}
Retention Policies
i. Raw Data: Retain raw metrics for 7 days
ii. Aggregated Data:Retain aggregated metrics for 1 year
Following is the sequence of operations involving core components, services for metric aggregation Workflow.
Conclusion✅
In designing a distributed task scheduler service, the combination of microservices and an event-driven architecture lays a robust foundation for scalability, fault tolerance, and operational efficiency. This architecture not only ensures seamless task assignment and execution but also adapts to fluctuating workloads through horizontal scaling and dynamic worker management. The use of decoupled components — such as task queues, schedulers, and workers — allows the system to achieve high availability and fault isolation while maintaining flexibility for future enhancements.
Refer to following for more system design concepts to gain in depth understanding about distributed systems.
🖥️📐🔍📝 System Design Concepts for Interviews
Happy System Designing !!!!🤖💻🎉🛠️🌟📐🚀✨. Clap and Follow link to support more such content.




