
Synthetic Data In A Nutshell — Why VC Money Grow 10-fold

Ali, Alex, and John walk into a bar. All three are genius tech guys who worked at the NSA and know the bleeding edge of technology regarding data.
The three decide to create a company on the cutting edge of data. A question for you: What do you think they come up with?
AI? Well, not really. Do you think they’d use their experience to go into the security sector? Again, kind of, but not really. What the three come up with is surprising: They want to build a company around fake data.
The story sounds almost like a joke, yet it isn’t. Ali, Alex, and John are the co-founders of gretel, already practically a giant in synthetic data with the latest series B worth $50m.
In hindsight, it’s hard for the three to describe what led them down this particular path in 2020, quite early to the game. However, I think two visionary insights stand out if you look into their journey.
Ali and his team had seen the cutting-edge tech inside the NSA, and they know language models and likely other models will only get better at generating data. They knew the tech would get there.
“Gretel actually started in 2019 using language models to build synthetic data, because our assumption was language models actually carry much better insights from the data itself.” — How Gretel Found Product Market Fit
On the other hand, they knew the cold start problem wasn’t solved and wouldn’t be solved any time soon. In fact, it will become bigger and bigger as companies drive more and more AI into their products.
Gretel sits right at the intersection of these two insights:
- a growing cold-start problem
- and technology that can solve it.
Founding in synthetic data is already 10x from 2020–2022 and is likely to continue to multiply over the years, starting with almost 0 in 2020. People are starting to see that there might be something in synthetic data!
So let’s explore what is in it.
Synthetic data is…. fake. That’s it. It’s made-up stuff, not worth a penny. And yet, it looks like synthetic data is at the breach of going from “theoretically useful” to practical reality.
It’s a lot like VR Headsets; everyone sees how valuable they can be — in theory. However, there are obvious practical limitations right now: the software isn’t there, and the hardware is neither. We all know it’s going to come at some point in time, but not yet.
Everyone would love a cheap VR headset; it just doesn’t exist yet.
For synthetic data, two years ago, the situation was very similar; everyone knew it was helpful, but only a handful of professionals could get it right. Professionals like Ali, Alex, and John. But now…
Changing Currents
“No man ever steps in the same river twice, for it’s not the same river and he’s not the same man.” — Heraclitus
Two forces push for new currents in the river of synthetic data. One is generative AI (yeah, that one again), which provides high-quality synthetic data quickly. The second is the growing gap between the data we have readily available and the demand we have for data & machine learning models & products on top of it.
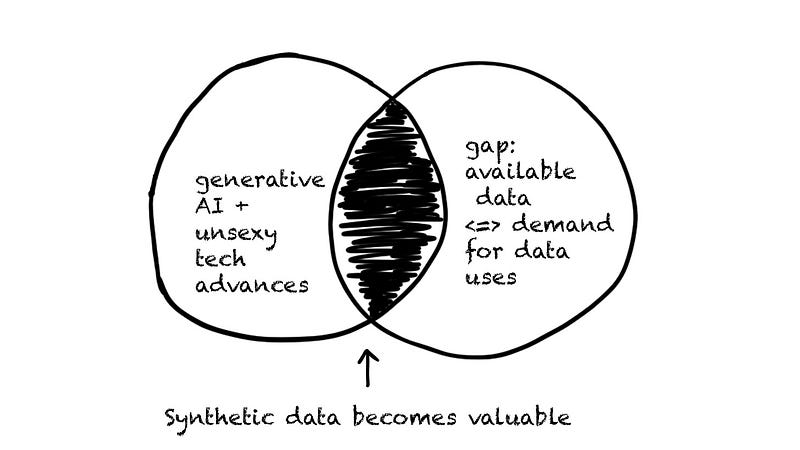
These two currents make one clear: Synthetic data is becoming useful, just like VR headsets. If you want to jump on early, now is the time.
What is synthetic data?
It’s fake data, period.
By fake, I mean it is generated by a machine — meant to imitate another type of data usually created differently.
The real beef, however, is in knowing how it is created because as in cooking, slight variations in recipes result in vastly different dishes.
- Generation using a probability distribution: The idea is pretty simple — you have a dataset of dice throws of six-faced dice for a couple of thousand throws. Then, you might as well use the probability distribution you know (or model one after the data you have) and generate any number of dice throws from it. The same principle applies to every single data set. Model a probability distribution after it, then use that to generate random new occurrences that conform to the data measurements like variance, mean, median, and the like.
- Generation through deep learning (or any ML): Using machine learning systems to generate synthetic data is very similar to the probability distribution approach, with one key difference: you don’t need to know the probability distribution. No specific modeling is needed, just some meta-modeling regarding choosing a proper ML model and the hyperparameters.
- GANs: GANs are trained specifically to mimic a certain dataset, so to train those, you’ll need a pretty large dataset to start. But the objective of the GAN is as close as you can get to actually generating synthetic data. The task of a GAN is to create new data points that look like they belong to the old ones as well as possible.
- Generative AI: With generative AI, you’re leveraging the power of a huge dataset and can tackle zero-shot problems quickly in situations where you have little data at all.
Both generative AI approaches and unique modeling using probability distributions work well without any data to start out at all — while GANs and ML approaches need a significant dataset to start.
Nothing is stopping you, though, from combining all these approaches. For instance, you can use GANs to generate 10x a dataset you already have 100,000 samples of and generative AI to generate one specific attribute you only have for a couple hundred of these samples.
Lack of data

When working as a machine learner at a b2b procurement platform, I used GANs in very much the same way to create a bunch of fake items like funky new industrial racks, electronic parts that looked like Dr. Frankenstein could’ve designed them, and lots of over-extreme variations of our catalog items.
But there’s one problem: The image above isn’t one of the ones I created because of data and privacy. I can’t share with you what I created because of privacy laws. Data belongs to people, and even if you get data, it might not be enough or not in the varieties you need it.
The privacy part is a key message for gretel.
“Generate artificial datasets with the same characteristics as real data, so you can develop and test AI models without compromising privacy.” — Gretel.ai
All I can tell you is that lack of data, or lack of fast data, lack of sufficient data, or lack of a variety of data use cases is always, and I mean always, a problem. Even if you have tons of data, data access might be a truly expensive problem for you.
For all purposes of doing AI (& data!): We lack sufficient readily available data, period.
What do you do with synthetic data?
The true question is not what you do currently with it but what the potentials are; because this technology is on the verge of becoming useful, you need to look just beyond the rim.
We know there is potential for synthetic data; Amazon used synthetic data to train its palm scanner because, as you might imagine, images of the human palm are not as frequent as machine learners might wish. In particular, generative AI was used to create variations, subtle changes, and edge cases for plam imagery.
OpenAI also used synthetic textual data to improve the skills of an image generation model.
Snowflake has now started to list synthetic data sets in its data marketplace.
The key idea is straightforward: Everything is better with lots of data! Synthetic data is easy to generate, so all use cases with relatively little data are good candidates for synthetic data supplements.
Where you could profit from synthetic data
I believe synthetic data can be used in all fields: data science, data engineering, data-heavy software development, and machine learning & AI. It is also a mistake to think of synthetic data only in terms of machine learning; most opportunities lie outside this domain.
Here are a bunch of examples where synthetic data can be helpful in different fields
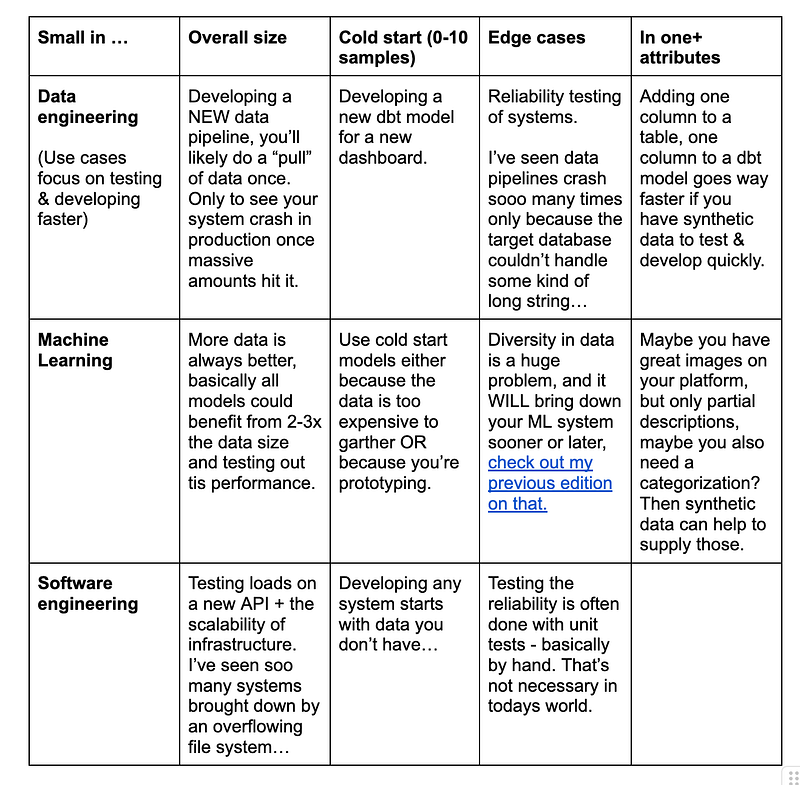
These examples are to spike your imagination; there’s plenty more once you start to think through it!
But how?
“But how?” That’s the catch and, in my opinion, the business opportunity. While, as you’ve seen above, there are many technical options to generate synthetic data, they still need quite a bit of data science knowledge and particular frameworks or DIY tools.
Towards AI lists a bunch of frameworks you can use to start generating synthetic data, but I’m still waiting for a few (product) breakthroughs in this area.
So what?
There is an opportunity here to improve how you build and test products from an entrepreneurial perspective. I’d love to chat if you share some thoughts on synth data!
Consider joining my free newsletter, “Three Data Point Thursday.” It’s become a trusted resource for data start-ups, VCs, and data leaders. — It will make your business smarter with data & AI.
Interested in data engineering in general? I share my favorite 6 articles of the week every week in my free newsletter, “Finish Slime.”





