Syncing Databases in a Microservices Architecture: When, Why, and How
In the modern software landscape, microservices architecture has become the go-to solution for creating scalable, resilient, and maintainable systems. Microservices break down monolithic applications into smaller, independent services that handle specific business capabilities, each with its own logic and, often, its own database. While this separation offers immense flexibility and scalability, it introduces a key challenge: data synchronization across different microservices and databases.
In this article, we’ll explore the various methods for syncing databases in a microservices architecture and when it’s better to choose database synchronization over APIs. We’ll also discuss real-world examples from the industry and how companies handle cross-domain database sync challenges.
The Role of Microservices in Modern Architecture
At its core, microservices architecture involves breaking an application down into distinct services that each handle a specific function. Each service manages its own data and communicates with other services through well-defined APIs. This enables:
- Scalability: Each service can be scaled independently based on traffic and resource needs.
- Flexibility: Each microservice can be developed, deployed, and maintained independently.
- Resilience: Failure in one service doesn’t necessarily affect the entire system.
However, the distributed nature of microservices brings data consistency challenges. If each service has its own database, how do you ensure data synchronization between these isolated systems, especially when business processes span across multiple domains?
Database Sync vs. APIs: What’s the Difference?
Before diving into the use cases for database synchronization, it’s important to understand the distinction between syncing databases and using APIs for communication between microservices.
- API-Based Sync: APIs (Application Programming Interfaces) are typically used to request data on-demand. For example, if a microservice needs to retrieve customer details from another service, it sends an API request and waits for the response.
- Pros: Real-time, decouples services, easy to apply security policies.
- Cons: Adds latency, can be inefficient for bulk data, can be error-prone in high-traffic environments.
- Database Sync: Database synchronization refers to automatically syncing data between databases, often in real time or on a scheduled basis, without relying on API calls.
- Pros: Efficient for large data transfers, low latency, strong data consistency, and performance.
- Cons: More complex to manage, requires specialized tools, may introduce tight coupling if not properly handled.
When is Database Synchronization the Best Choice?
APIs are excellent for lightweight, real-time interactions, but there are cases where database synchronization is the better approach. Let’s explore some of these scenarios.
1. Handling Large Volumes of Data Efficiently
When you need to transfer large volumes of data between microservices, such as syncing customer orders, sales reports, or IoT device data across different domains, APIs quickly become inefficient. In this case, direct database synchronization is the better choice.
Example: In e-commerce platforms, it’s common to have a dedicated service for handling product inventory. Multiple services (such as order management, shipping, and warehouse systems) rely on this inventory data. Instead of sending frequent API calls for large datasets, companies often sync databases between the inventory and warehouse systems using database synchronization tools.
Best Practice: Use database synchronization tools such as Change Data Capture (CDC) or ETL (Extract, Transform, Load) processes. Tools like Debezium or SQL Server Integration Services (SSIS) can capture changes in the source database and sync them in bulk to the target database.
2. Real-Time Synchronization for Mission-Critical Data
In industries like finance or healthcare, real-time data synchronization between microservices is crucial. For instance, a financial system may need to sync transaction data across different services to ensure that all parts of the system reflect the latest state.
Example: A stock trading platform processes thousands of transactions per second. In such an environment, APIs may struggle to handle the sheer volume of requests for syncing account balances between the transaction service and the customer service. Instead, real-time database replication using tools like Oracle GoldenGate ensures sub-second latency, enabling each service to have up-to-date information without the bottleneck of API requests.
Best Practice: Use database replication for real-time updates, especially when high availability and immediate data consistency are required. Tools like GoldenGate or Apache Kafka with Debezium can replicate data changes instantly across microservices.
3. Achieving Strong Data Consistency Across Microservices
Ensuring data consistency between microservices is one of the most critical challenges in a distributed system. When multiple services rely on shared data (e.g., order fulfillment and billing services in an e-commerce platform), inconsistency can lead to critical issues.
Example: In ride-sharing platforms like Uber or Lyft, various services (such as ride booking, driver management, and payments) need to share data about customer trips, driver availability, and billing. Inconsistent data could lead to overbooking or incorrect billing. To ensure eventual consistency, ride-sharing companies use a combination of database synchronization and event-driven architectures to ensure all systems eventually sync, without the need for complex API logic.
Best Practice: Implement event-driven database synchronization with event streaming platforms like Kafka. By using event sourcing, each service can publish and subscribe to changes, ensuring eventual consistency across all services.
4. Legacy System Integration
Legacy systems are often tightly coupled with their databases and don’t expose modern APIs. When integrating legacy systems with modern microservices, direct database synchronization is often the only viable approach.
Example: In the banking industry, many core systems are legacy mainframes with proprietary databases. Modernizing these systems by integrating them with new microservices (e.g., mobile banking) often requires direct database synchronization. For example, JP Morgan relies on GoldenGate to sync legacy core banking systems with modern payment gateways.
Best Practice: Use ETL tools or CDC technologies like Oracle GoldenGate or Attunity Replicate to sync databases between legacy systems and microservices. This approach avoids API complexity and ensures that legacy systems are seamlessly integrated with modern services.
5. High Availability and Disaster Recovery
Database synchronization is essential for ensuring high availability and disaster recovery in microservices. Having synchronized databases allows you to maintain a secondary, failover system that can immediately take over if the primary system goes down.
Example: Netflix, one of the largest users of microservices, leverages Cassandra and DynamoDB for its distributed database architecture. These databases are replicated across multiple regions to ensure that, if one data center goes down, another region can take over seamlessly.
Best Practice: Use multi-region database replication tools like Cassandra, GoldenGate, or DynamoDB Streams to ensure high availability. These systems can automatically sync data across regions and provide failover capabilities.
Common Tools for Database Synchronization
- Debezium: An open-source CDC (Change Data Capture) tool that integrates with Kafka for event-driven database synchronization. Ideal for capturing real-time changes in databases like MySQL, PostgreSQL, and SQL Server.
- Oracle GoldenGate: A high-performance tool for real-time data integration, replication, and transactional change data capture across heterogeneous environments.
- SQL Server Integration Services (SSIS): A built-in Microsoft tool for ETL processes that allows you to extract, transform, and load data between SQL Server and other databases.
- Apache Kafka: A distributed streaming platform that can be used in combination with CDC tools like Debezium to provide real-time, event-driven sync between databases.
When to Use APIs Instead of Database Synchronization
While database synchronization is powerful, there are situations where APIs make more sense:
- Real-Time User Interactions: If a service needs immediate data for real-time user requests (e.g., search queries), APIs are more suitable.
- Microservice Communication: APIs help decouple services, allowing them to request data only when needed, reducing unnecessary data syncs.
- Security and Access Control: APIs allow for granular security policies, enabling authentication and authorization at a more detailed level.
- Dynamic Data: APIs are ideal for retrieving frequently changing data or small, dynamic data sets, where syncing entire databases would be inefficient.
Conclusion: Database Synchronization in a Microservices World
In a microservices architecture, database synchronization offers an efficient and scalable way to handle large volumes of data, maintain real-time consistency, and ensure high availability. By using the right tools and strategies — such as Change Data Capture (CDC), ETL, and database replication — you can overcome many of the data challenges that arise from distributed systems.
However, it’s essential to know when to use database synchronization and when to opt for API-based communication. In many cases, combining both approaches can yield the best results, ensuring data integrity while maintaining flexibility and scalability.
As the industry continues to evolve, finding the right balance between APIs and database synchronization will be key to building reliable and scalable microservices systems.
Best Practices for Database Synchronization (Without APIs)
When syncing tables between databases without using APIs, the approach typically depends on the use case, volume of data, and performance requirements. The following are best practices for synchronizing tables directly between databases:
1. Asynchronous, Event-Driven Synchronization
- Best Practice: Use Change Data Capture (CDC) or event-driven architectures like Debezium or Kafka to track changes in the source database (e.g., SQL Server) and propagate them to the target database (e.g., Oracle).
- How It Works: Tools like Debezium capture data changes (inserts, updates, deletes) in real-time and propagate them to the target database.
- Benefits:
- Low Latency: Near real-time updates between databases.
- Scalability: Easily scales as more tables and services need syncing.
- Decoupling: Keeps the source and target databases loosely coupled, aligning with microservice principles.
2. Periodic Synchronization via ETL (Extract, Transform, Load)
- Best Practice: Use ETL tools (e.g., SQL Server Integration Services (SSIS), Azure Data Factory) for periodic synchronization between databases.
- How It Works: Data is extracted from the source database, optionally transformed, and then loaded into the target database at regular intervals (e.g., hourly, daily).
- Benefits:
- Cost-Effective: Useful for syncing large volumes of data at scheduled intervals.
- Flexibility: Ideal for less time-sensitive data, such as warehouses or aggregated data.
3. Database Replication
- Best Practice: For high-availability or redundancy needs, use database replication (e.g., SQL Server Replication or Oracle GoldenGate) to synchronize tables between databases.
- How It Works: Replication keeps a near real-time copy of the data in the target database by propagating changes as they occur.
- Benefits:
- Real-Time Updates: Ensures real-time or near real-time replication of data.
- Fault Tolerance: Provides redundancy and failover capabilities.
4. Use Materialized Views (for Read-Only Data)
- Best Practice: For read-heavy, less frequently changing data, use materialized views in the target database.
- How It Works: Materialized views are periodically refreshed from the source database.
- Benefits:
- Performance: Reduces load on the source database by caching the data in the target system.
- Simple to Implement: Minimal configuration and management.
5. Conflict Handling and Idempotency
- Best Practice: Ensure conflict handling mechanisms are in place if both databases may make changes. Use idempotent operations to ensure that reapplying the same data does not cause issues (e.g., duplicate entries).
- Benefits:
- Data Consistency: Avoids issues like duplicate data or failed syncs.
- Stability: Ensures that retrying a failed sync does not introduce inconsistencies.
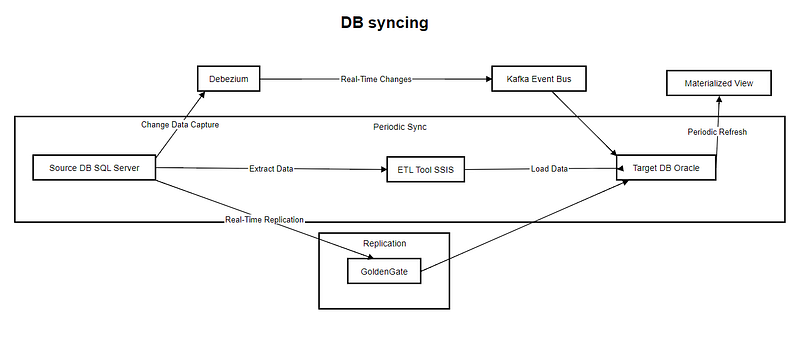
Explanation of Mermaid Diagram:
- Source DB (SQL Server): This is where the data originates.
- Debezium + Kafka: Captures real-time changes in the source database and uses Kafka to broadcast these changes asynchronously.
- Target DB (Oracle): The destination where the synchronized data resides.
- ETL (SSIS): A periodic synchronization process that extracts and loads data at scheduled intervals.
- GoldenGate Replication: Real-time replication mechanism for high-availability use cases.
- Materialized View: Periodically refreshed view for less dynamic, read-heavy data.
Conclusion:
For a best-practice database sync strategy without using APIs:
- Use Debezium with Kafka for real-time, event-driven sync.
- Apply ETL jobs (SSIS) for periodic sync of non-critical data.
- Use GoldenGate for high-availability or critical real-time replication.
- Utilize materialized views for caching read-heavy, less frequently updated data.
- Implement idempotent sync and conflict resolution mechanisms for data integrity.





