

Swish: Booting ReLU from the Activation Function Throne
How Swish Beats ReLU in the Deep Learning Activation Function Competition
Activation functions have long been a focus of interest in neural networks — they generalize the inputs repeatedly and are integral to the success of a neural network. ReLU has been defaulted as the best activation function in the deep learning community for a long time, but there’s a new activation function — Swish — that’s here to take the throne.
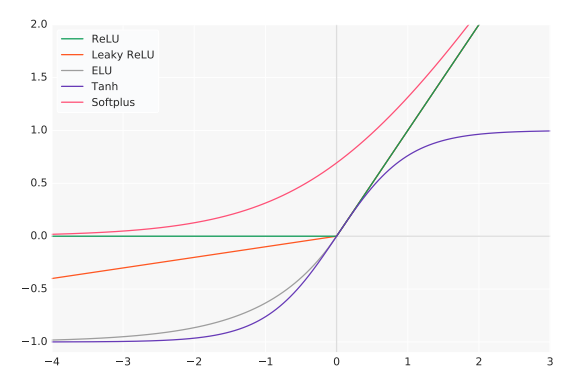
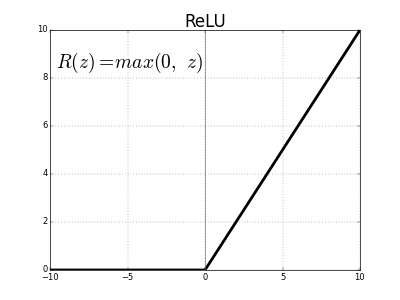
Activation functions have a long history. First, the sigmoid function was chosen for its easy derivative, range between 0 and 1, and smooth probabilistic shape. The tanh function was also considered as being an alternative to the sigmoid function, fitted on a scale between -1 and 1, but these classical activation functions have been replaced with ReLU. The Rectified Linear Unit (ReLU) is currently the most popular activation function because the gradient can flow when the input to the ReLU function is positive. Its simplicity and effectiveness has pushed ReLU and branching methods like Leaky ReLU and Parametrized ReLU past the sigmoid and tanh units.
Prajit Ramachandran, Barret Zoph, and Quoc V. Le propose a new activation function in their paper (link at bottom), which they call Swish. Swish is simple — it’s x times the sigmoid function.
Research by the authors of the papers shows that simply be substituting ReLU units with Swish units improves the best classification accuracy on ImageNet by 0.9% for Mobile NASNet-A and 0.6% for Inception-ResNet-v2.
What is the Swish Activation Function?
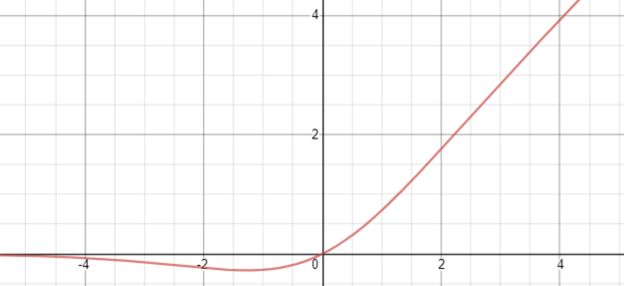
Formally stated, the Swish activation function is…
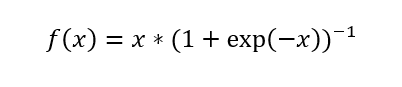
Like ReLU, Swish is bounded below (meaning as x approaches negative infinity, y approaches some constant value) but unbounded above (meaning as x approaches positive infinity, y approaches infinity). However, unlike ReLU, Swish is smooth (it does not have sudden changes of motion or a vertex):
Additionally, Swish is non-monotonic, meaning that there is not always a singularly and continually positive (or negative) derivative throughout the entire function. (Restated, the Swish function has a negative derivative at certain points and a positive derivative at other points, instead of only a positive derivative at all points, like Softplus or Sigmoid.
The derivative of the Swish function is…
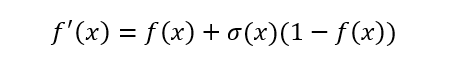
The first and second derivatives of Swish, plotted:
For inputs less than about 1.25, the derivative has a magnitude of less than 1.
Properties of Swish
Unboundedness is desirable for activation functions because it avoids a slow training time during near-zero gradients — functions like sigmoid or tanh are bounded above and below, so the network needs to be carefully initialized to stay within the limitations of these functions.
The ReLU function is an improvement over tanh because it is bounded above — this property is so important that every successful activation function after ReLU is unbounded above.
Being bounded below may be advantageous because of strong regularization — functions that approach zero in a limit to negative infinity are great at regularization because large negative inputs are discarded. This is important at the beginning of training when large negative activation inputs are common.
These bounds are satisfied by Softplus, ReLU, and Swish, but Swish’s non-monotonicity increases ‘expressivity’ of an input and improves gradient flow.
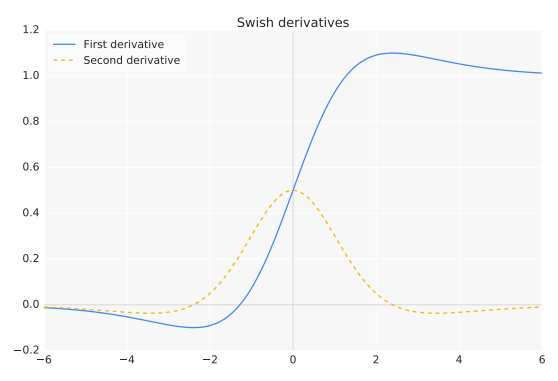
Additionally, smoothness helps optimize and generalize the neural network. In the output landscapes below, it is obvious that ReLU’s output landscape is sharp and jarring because of its non-smooth nature, whereas the Swish network landscape is much smoother.

The output landscape smoothness directly correlates with the error landscape. A smoother error space is easier to traverse and find a minima — consider it like walking in the jarring range of altitudes of the Himalayan range versus walking in the smooth, rolling hills of the English countryside.

Swish Performance
The authors of the Swish paper compare Swish to the following other activation functions:
- Leaky ReLU, where f(x) = x if x ≥ 0, and ax if x < 0, where a = 0.01. This allows for a small amount of information to flow when x < 0, and is considered to be an improvement over ReLU.
- Parametric ReLU is the same as Leaky Relu, but a is a learnable parameter, initialized to 0.25.
- Softplus, defined by f(x) = log(1 + exp(x)), is a smooth function with properties like Swish, but is strictly positive and monotonic.
- Exponential Linear Unit (ELU), defined by f(x) = x if x ≥ 0 and a(exp(x) — 1) if x < 0 where a = 1.
- Scaled Exponential Linear Unit (SELU), identical to ELU but with the output multiplied by a value s.
The below table demonstrates how many times Swish performed better, equal, or worse than the outlined baseline activation functions at 9 experiments.

Swish vs. ReLU
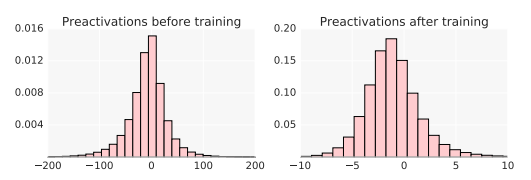
The authors find that by substituting the ReLU units for Swish units, there is significant improvement over ReLU as the number of layers increases from 42 (when optimization becomes more difficult).
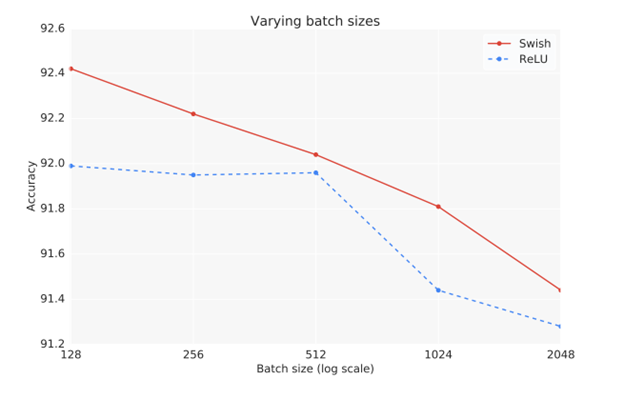
The authors also found that Swish outperforms ReLU with diverse sizes of batches.
Testing on Various Datasets
The authors tested Swish against the following baseline activation functions with the following results:
- CIFAR-10 and CIFAR-100 datasets — Swish consistently matches or outperforms ReLU on every model for both CIFAR-10 and CIFAR-100.
- ImageNet — Swish outperforms ReLU by 0.6%, with a 0.9% boosts on Mobile NASNet-A and a 2.2% boost on MobileNet over ReLU.
- WMT 2014 English to German — Swish outperforms ReLU on all of four test datasets.
Implementation
Implementing Swish is very simple — most deep learning libraries should support Swish…
tn.nn.swish(x)…or can be represented as x multiplied by the sigmoid function
x * tf.sigmoid(x)Convinced Yet?
Next time you are training a deep neural network, give Swish a try!
Thanks for reading! If you enjoyed, feel free to check out some of my other work as well.
The Swish paper can be found here.



{kind=link}
{kind=link}
{kind=link}
{kind=link}