
Sweetviz-一個在資料分析前必須先使用的套件
大家好久不見,轉眼間已經準備要11月了,自身的能力也隨著時間的推移不斷的進步著,世界也是一直在變化著。現在沒有意外的話,應該都是2~3週會新增一篇技術文章,讓自己不斷保持著學習狀態。
此次文章流程:
(1) 回想
(2) 介紹
(3) 實際Demo
(4) 結論
再開始之前,可以連結至我的Github,搭配著文章一起觀賞!
(1) 回想
請各位可以試著回想或想像一下,當自己在面對一個從來沒看過的資料集時,你會怎麼做分析?我認為可能會需要以下步驟:
- 暸解為什麼要分析這個資料集,通常是痛點
- 暸解Y定義,就是你要用什麼方法來解決通點
- 暸解資料集的樣態
- 暸解資料集的X變數的含義和類型
- 進行EDA(探索性資料分析)嘗試利用X變數或Y定義來找出或驗證特別的Insights
以上的步驟非常吃你對你在做的事情的專業知識,以第4到第5的步驟來說,在一般進行變數的EDA時,如果剛好X變數非常的多,你根本會像個無頭蒼蠅似的,不知道要從哪個變數的畫圖開始,要精準的判斷與準備EDA圖表會非常困難,雖然我們都知道在分析的過程實在是無法完美的估算完成時間,但是如果有個工具能夠幫助你先一次的畫出圖表,你再從看似最有影響力或可發揮性最大的變數開始,我認爲是一個很有效的方法。
(2) 介紹
所以,這篇文章介紹的是Sweetviz,一個非常強大的Python套件,能夠
- 快速幫你完成你的資料集的EDA(探索性資料分析)和相關統計量的計算,同時也能幫助你
- 比較兩個不同資料集的特徵樣態或是
- 比較兩個子資料集的特徵樣態
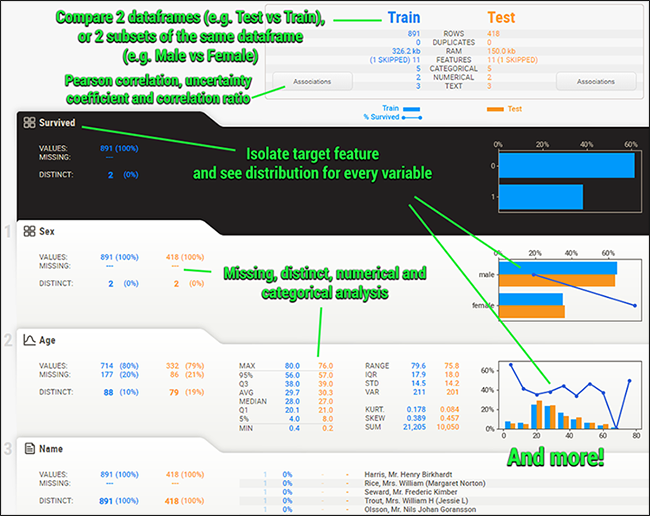
(3) 實際Demo
要成功介紹一個套件的最好的方法就是實際demo給你們看,那在開始前,如果你還沒有安裝sweetviz的話,可以開啟cmd來pip
pip install sweetviz在demo之前,想先提醒你們,因為資料量和X變數的量有大有小,Sweetviz對於製作圖表的時候,都會預先針對變數去計算correlation,這個方法在資料集變大的時候就會使得產生報表的時間顯著變慢,所以,你可以考慮在接下來analyze或compare的時候,多加入一個參數:
pairwise_analysis='off'在這次Demo,所使用的資料集一個大家耳熟能詳,來自Kaggle的Titanic資料集,讓大家可以花越少的時間去熟悉資料,這樣就可以花越少的去熟練套件。
那在使用sweetviz前,有前置作業需要被完成,那就是讀取資料
train = pd.read_csv('./titanic/train.csv', index_col=0)
test = pd.read_csv('./titanic/test.csv', index_col=0)再來就可以針對每種不同的報表去寫code了
# 要記得import!
import sweetviz as sv1. 基本報表
基本報表顧名思義就是不需要更改太多的參數,只要使用其預設的參數就會獲得的報表
report_train = sv.analyze([train, 'train']) # 'train'是指會給這個資料集命名為train
report_train.show_html(filepath='Basic_train_report.html') # 儲存為html的格式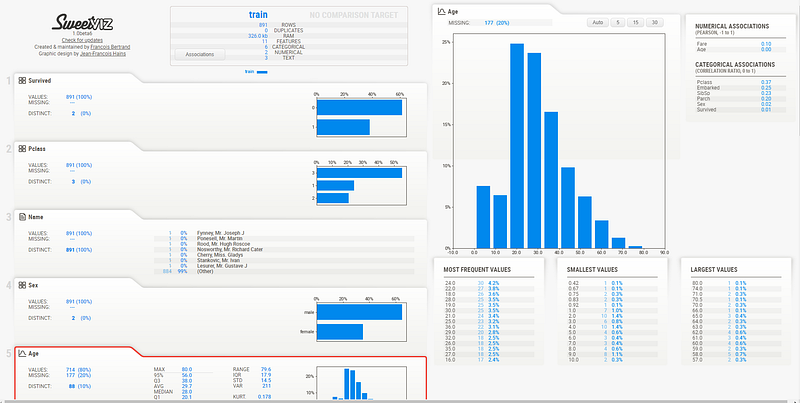
2. 加入目標變數(Y定義)的報表
如果你已經有畫過基本報表,可能會發現Sweetviz會去自動推斷你的X變數分別是屬於哪個型態,文字型、數值型或是類別型,而它的自動判定的型態不一定你期待的,所以你可以進行更改。
feature_config = sv.FeatureConfig(skip='Name', # 要忽略哪個特徵
force_cat=['Pclass', 'Sex', 'SibSp', 'Parch', 'Ticket', 'Cabin'], # Categorical特徵
force_num=['Age', 'Fare'], # Numerical特徵
force_text=None) # Text特徵處理好X變數型態的錯誤後,可以將目標變數的名稱告訴Sweetviz,它會基於原本的基本報表,將各個X變數在目標變數下的狀況都額外畫給你看,請看以下:
report_train_with_target = sv.analyze([train, 'train'],
target_feat='Survived', # 加入特徵變數
feat_cfg=feature_config)
report_train_with_target.show_html(filepath='Basic_train_report_with_target.html')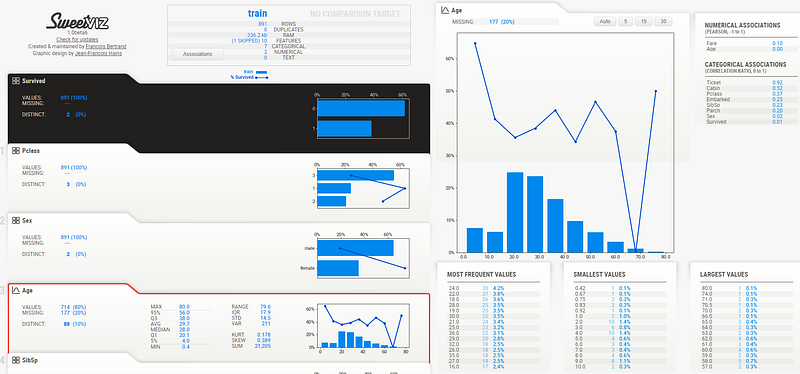
3. 比較train和test的報表
我們在切分train和test兩個資料集的時候,常常會需要比較其是否具有的變數特性,如只有一資料集具備某種特性,會使得訓練和預測時產生overfitting或underfiiting的狀況。
compare_report = sv.compare([train, 'Training Data'], # 使用compare
[test, 'Test Data'],
'Survived',
feat_cfg=feature_config)
compare_report.show_html(filepath='Compare_train_test_report.html')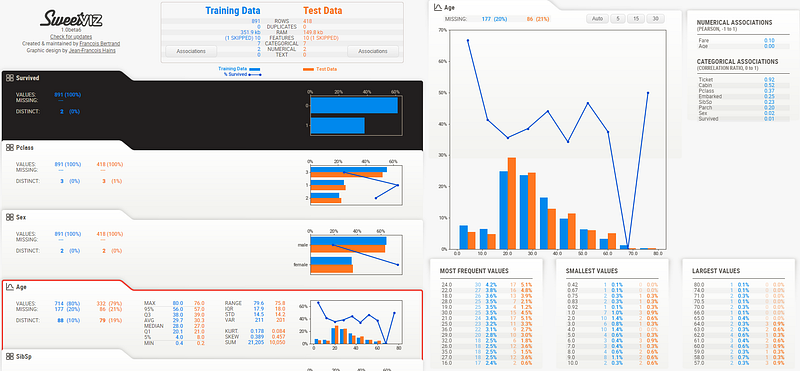
4. 比較Male和Female兩個子資料集的報表
來到了最後一個報表,剛剛上面的報表是在比較兩個不同的母資料集的樣態,而現在這個報表目的是在比較同個母體中,一個二元的X變數所代表的兩個不同的資料集的樣態,這邊以男和女為例,可以更進階的去分析,是否男生和女生在其他的X變數中會有不一樣的樣態。
compare_subsets_report = sv.compare_intra(train,
train['Sex']=='male', # 給條件區分
['Male', 'Female'], # 為兩個子資料集命名
target_feat='Survived',
feat_cfg=feature_config)
compare_subsets_report.show_html(filepath='Compare_male_female_report.html'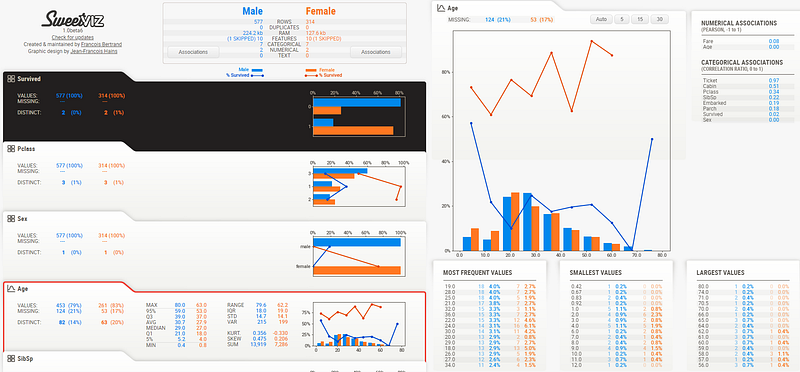
(4) 結論
透過我的引導,相信你也輕鬆寫意的學會了這個套件,但是真正難的部分,還是在你做完報表後,要怎麼分析,怎麼讓你的圖表產生巨大的價值,這也是你的價值所在
又到了這篇文章的最後,感謝你看到這裡,希望我每次的文章都可以帶給你新的東西,讓你不管在工作中或者是其他個人專案上,都有著些許的突破,也能不斷的去擁抱未知的東西,一起加油!
一樣,有問題的話都可以寄信給我,我的信箱是[email protected]





