
Survival analysis using lifelines in Python
Checkout the video version here:
Survival analysis is used for modeling and analyzing survival rate (likely to survive) and hazard rate (likely to die).
Let’s start with an example:
Here we load a dataset from the lifelines package. I am only looking at 21 observations in my example. The survival analysis dataset contains two columns: T representing durations, and E representing censoring, whether the death has observed or not. Censoring is what makes survival analysis special. There are events you haven’t observed yet but you can’t drop them from your dataset.
For example, in our dataset, for the first individual (index 34), he/she has survived until time 33, and the death was observed. But for the individual in index 39, he/she has survived at 61, but the death was not observed.
from lifelines.datasets import load_waltons
df = load_waltons()
df1 = df.iloc[34:55][['T','E']]
df1
Kaplan-Meiser Estimate
The easiest way to estimate the survival function is through the Kaplan-Meiser Estimator. Equation is shown below .It’s basically counting how many people has died/survived at each time point. d_i represents number of deaths events at time t_i, n_i represents number of people at risk of death at time t_i.
Again, use our example of 21 data points, at time 33, one person our of 21 people died. Thus, the survival rate at time 33 is calculated as 1–1/21. At time 54, among the remaining 20 people 2 has died. At time 61, among the remaining 18, 9 has dies. At time 67, we only have 7 people remained and 6 has died. We can see that Kaplan-Meiser Estimator is very easy to understand and easy to compute even by hand.

Here we get the same results if we use the KaplanMeierFitter in lifeline. In addition to the functions below, we can get the event table from kmf.event_table , median survival time (time when 50% of the population has died) from kmf.median_survival_times , and confidence interval of the survival estimates from kmf.confidence_interval_ .
T = df1['T']
E = df1['E']
from lifelines import KaplanMeierFitter
kmf = KaplanMeierFitter()
kmf.fit(T, event_observed=E)
kmf.survival_function_
kmf.plot_survival_function()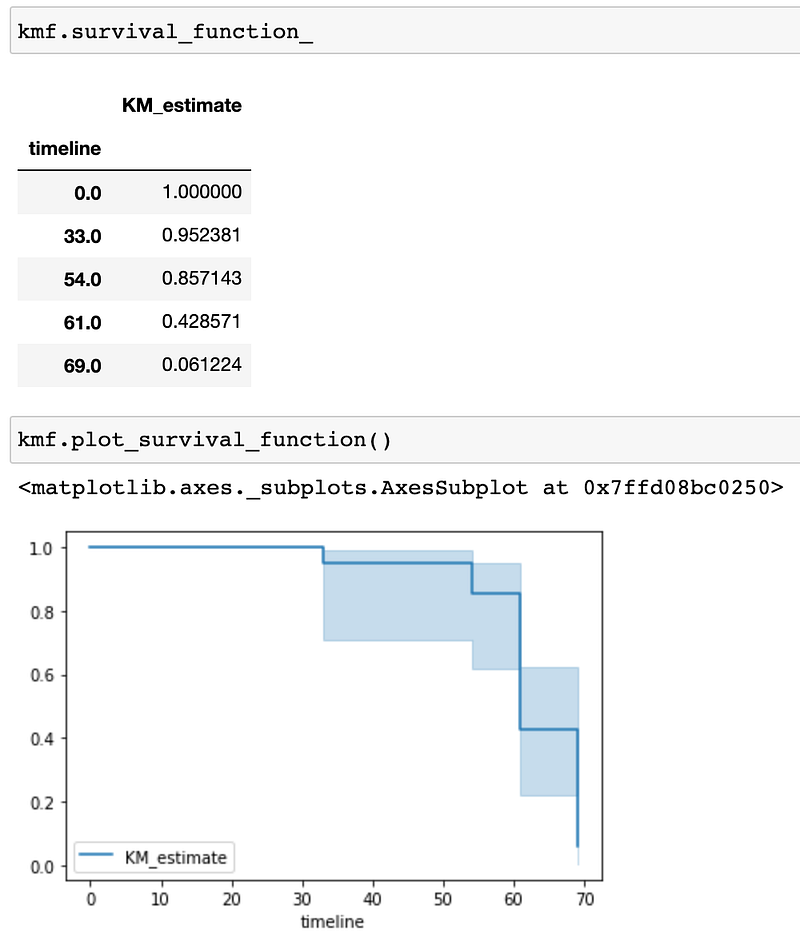
Nelson Aalen Estimate
Nelson Aalen estimator estimates hazard rate first with the following equations. d_i represents number of deaths events at time t_i, n_i represents number of people at risk of death at time t_i. We can get all the harzard rate through simple calculations shown below.

Again, we can easily use lifeline to get the same results.
from lifelines import NelsonAalenFitter
naf = NelsonAalenFitter(nelson_aalen_smoothing=False)
naf.fit(T, event_observed=E)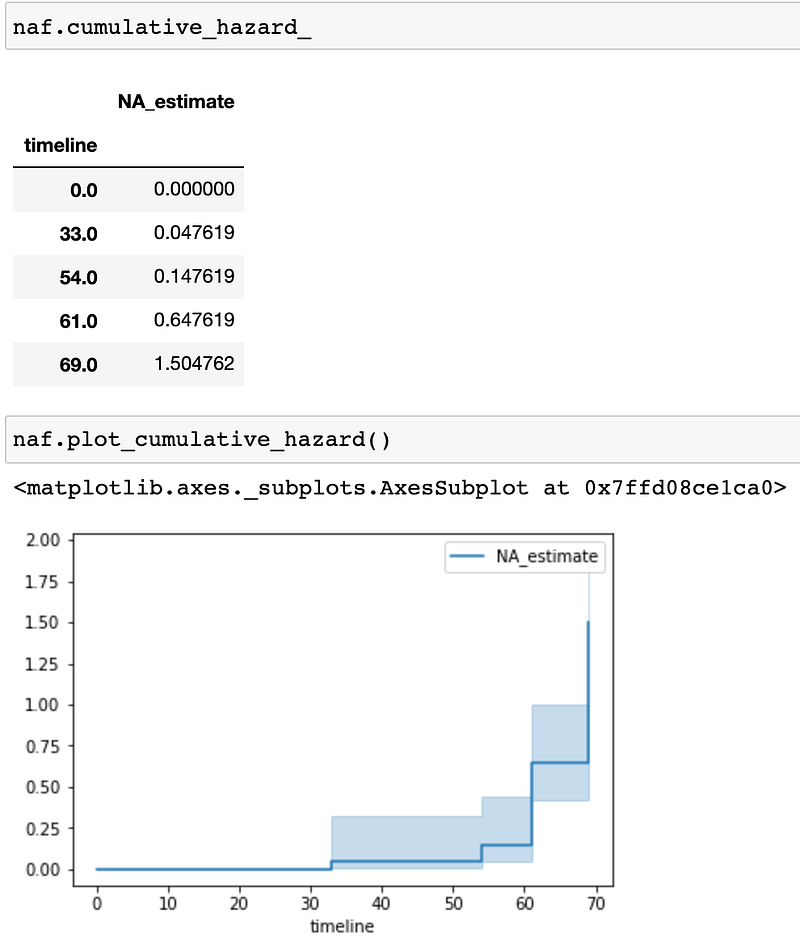
Kaplan-Meier and Nelson-Aalen models are non-parametic. They are simple to interpret, but no functional form, so that we can’t model a distribution function with it. This is where the exponential model comes handy.
Exponential model
Exponential distribution is based on the poisson process, where the event occur continuously and independently with a constant event rate 𝜆. Exponential distribution models how much time needed until an event occurs with the pdf 𝑓(𝑡)=𝜆𝑒xp(−𝜆𝑡) and cdf 𝐹(𝑡)=𝑝(𝑇≤𝑡)=1−𝑒xp(−𝜆𝑡). The cdf of the exponential model indicates the probability not surviving pass time t, but the survival function is the opposite. Thus, for survival function:
- 𝑠(𝑡)=1−𝐹(𝑡)=exp(−𝜆𝑡)
- ℎ(𝑡)=𝜆
- 𝐻(𝑡)=𝜆𝑡
Note that lifelines use the reciprocal of 𝜆, which doesn’t really matter. We can see that the exponential model smoothes out the survival function.

Weibull model
Exponential distribution is a special case of the Weibull distribution: x~exp(𝜆)~ Weibull (1/𝜆,1).
The cdf of the Weibull distribution is 𝐹(𝑡)=1−exp(−(𝑡/𝜆)𝜌)
- 𝜌 < 1: failture rate decreases over time
- 𝜌 = 1: failture rate is constant (exponential distribution)
- 𝜌 >1: failture rate increases over time
Again, we can write the survival function as 1-F(t):
- 𝑠(𝑡)=exp(−(𝑡/𝜆)𝜌)
- ℎ(𝑡)=𝜌/𝜆(𝑡/𝜆)^(𝜌−1)
- 𝐻(𝑡)=(𝑡/𝜆)𝜌

Model selection
We talked about four types of univariate models: Kaplan-Meier and Nelson-Aalen models are non-parametric models, Exponential and Weibull models are parametric models. There are a lot more other types of parametric models. Which model do we select largely depends on the context and your assumptions. Statistically, we can use QQ plots and AIC to see which model fits the data better. More info see https://lifelines.readthedocs.io/en/latest/Examples.html#selecting-a-parametric-model-using-qq-plots.
Survival regression
The general function of survival regression can be written as:
hazard = exp(𝑏0+𝑏1𝑥1+𝑏2𝑥2…𝑏𝑘𝑥𝑘),
which represents that hazard is a function of Xs.
Exponential model
Exponential survival regression is when 𝑏0 is constant.
Cox’s proportional hazard model
Cox’s proportional hazard model is when 𝑏0 becomes 𝑙𝑛(𝑏0(𝑡)), which means the baseline hazard is a function of time.
ℎ(𝑡|𝑥)=𝑏0(𝑡)𝑒𝑥𝑝(∑𝑏𝑖𝑥𝑖)
- ℎ(𝑡|𝑥) hazard
- 𝑏0(𝑡) baseline hazard, time-varying
- 𝑒𝑥𝑝(∑𝑏𝑖𝑥𝑖) partial hazard, time-invariant
- xi is often centered to the mean
Pro
- can fit survival models without knowing the distribution
- with censored data, inspecting distributional assumptions can be difficult
- no need to specify the underlying hazard function, great for estimating covariate effects and hazard ratios.
Con
- estimate 𝑏0,…𝑏𝑘 without having to specify 𝑏0(𝑡)
- can not estimate s(t) and h(t)
Assumptions
- Non-informative censoring
check: predicting censor by Xs
2. survival times (t) are independent
3. ln(hazard) is linear function of numeric Xs.
- check: residual plots
- fix: transformations
4. Values of Xs don’t change over time.
- fix: add time-varying covariates
5. Harzards are proportional. Hazard ratio between two subjects is constant.
- check: Schoenfeld residuals, proportional hazard test
- fix: add non-linear term, binning the variable, add an interaction term with time, stratification (run model on subgroup), add time-varying covariates.
The most important assumption of Cox’s proportional hazard model is the proportional hazard assumption. But we may not need to care about the proportional hazard assumption. As mentioned in Stensrud (2020), “There are legitimate reasons to assume that all datasets will violate the proportional hazards assumption”.
Here is an example of the Cox’s proportional hazard model directly from the lifelines webpage (https://lifelines.readthedocs.io/en/latest/Survival%20Regression.html). One thing to note is the exp(coef) , which is called the hazard ratio. The exp(coef) of marriage is 0.65, which means that for at any given time, married subjects are 0.65 times as likely to dies as unmarried subjects.

Finally, if the features vary over time, we need to use time varying models, which are more computational taxing but easy to implement in lifelines.
Aalen’s additive model
ℎ(𝑡|𝑥)=𝑏0(𝑡)+𝑏1(𝑡)𝑥1+…𝑏𝑁(𝑡)𝑥𝑁
Cox’s time varying proportional hazard model
ℎ(𝑡|𝑥)=𝑏0(𝑡)𝑒𝑥𝑝(∑𝛽𝑖(𝑥𝑖(𝑡)))
Model selection
Survival probability calibration plot
The survival probability calibration plot compares simulated data based on your model and the observed data. It provides a straightforward view on how your model fit and deviate from the real data. This is implemented in lifelines lifelines.survival_probability_calibration function.
Compare model fit statistics
We can run multiple models and compare the model fit statistics (i.e., AIC, log-likelihood, and concordance). Model with a smaller AIC score, a larger log-likelihood, and larger concordance index is the better model.
Out-of-sample validation
We can also evaluate model fit with the out-of-sample data. Here we can investigate the out-of-sample log-likelihood values. This is especially useful when we tune the parameters of a certain model.
Within-sample validation
AIC is used when we evaluate model fit with the within-sample validation. Again smaller AIC value is better.
Cross validation
K-folds cross validation is also great at evaluating model fit. This is implemented in lifelines lifelines.utils.k_fold_cross_validation function.
Ref:
https://www.youtube.com/watch?v=vX3l36ptrTU https://lifelines.readthedocs.io/ https://stats.stackexchange.com/questions/64739/in-survival-analysis-why-do-we-use-semi-parametric-models-cox-proportional-haz https://stats.stackexchange.com/questions/399544/in-survival-analysis-when-should-we-use-fully-parametric-models-over-semi-param https://jamanetwork.com/journals/jama/article-abstract/2763185 Stensrud MJ, Hernán MA. Why Test for Proportional Hazards? JAMA. Published online March 13, 2020. doi:10.1001/jama.2020.1267




