
Supervised vs Unsupervised vs Reinforcement Machine Learning
Types of Machine Learning Explained
Machine learning is a type of artificial intelligence that allows a system to learn and improve its performance over time without being explicitly programmed. It involves training a model on a dataset, allowing the model to make predictions or decisions based on the patterns it learned from the data.
As machine learning is used in a variety of fields, including natural language processing, image and speech recognition, and predictive modeling. It becomes important for us to understand at least the most widely used types of machine learning. These include,
TLDR; Don’t have time to read? Here’s a video to help you understand the difference between supervised vs unsupervised vs reinforcement learning in detail.
Supervised learning or Supervised ML
Supervised machine learning is a type of machine learning where a model is trained on labeled data, meaning that the data includes both input features and the corresponding correct output labels. Here, the goal is to build a model to predict about new, unseen data based on the patterns it learned from the previous training data.
In supervised learning, the model is given a set of input-output pairs and a loss function, and the goal is to find the set of parameters that minimize the loss on the training data. This is typically performed using an optimization algorithm. One such algorithm is stochastic gradient descent.
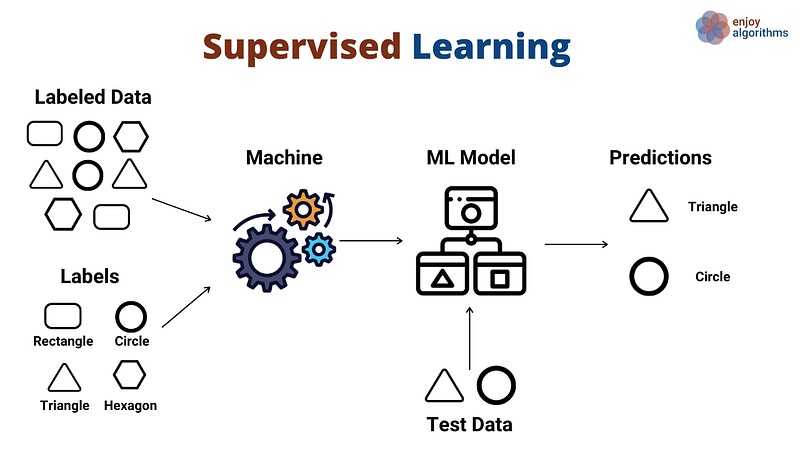
There are many different types of supervised learning algorithms, including linear regression, logistic regression, support vector machines (SVMs), decision trees, and random forests. These algorithms can be used to solve a wide range of problems, including classification tasks (e.g. determining whether an email is spam or not), regression tasks (e.g. predicting the price of a house based on its characteristics), and structured prediction tasks (e.g. predicting how the sequence of words will occur in a given sentence).
One of the main advantages of supervised learning is that it requires relatively little data to be effective. In many cases, a small labeled dataset can be used to train a model with good performance. However, the quality of the model is heavily dependent on the quality of the training data, and the model may not generalize well to new, unseen data if the training data is not representative of the overall distribution of the data.
In addition, supervised learning requires that the correct output labels be known for the training data, which can be time-consuming and costly to obtain. This can be a significant barrier to the use of supervised learning in some applications.
Overall, supervised learning is a powerful and widely-used tool for a variety of tasks, but it is important to carefully consider its limitations and the quality of the training data when using it to solve a problem.
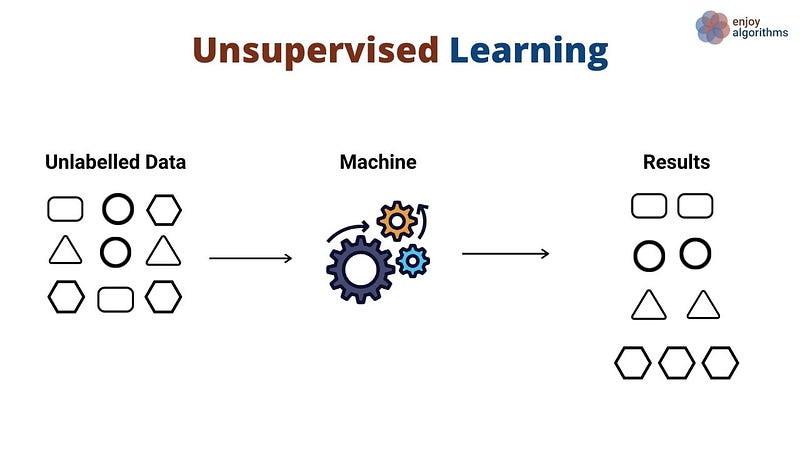
Unsupervised learning or Unsupervised ML
Unsupervised machine learning is a type of machine learning where the model is not given any labeled training data, and the goal is to find patterns or relationships in the data. This is done by clustering the data into groups based on some shared characteristics or by identifying relationships between the data points.
Unsupervised learning can be used for tasks such as anomaly detection, data compression, and density estimation. Some common unsupervised learning algorithms include k-means clustering, principal component analysis (PCA), and autoencoders.
One of the main advantages of unsupervised learning is that it does not require labeled training data, which can be time-consuming and costly to obtain. This makes it well-suited for tasks where it is difficult or impossible to obtain labeled data, or where the cost of labeling the data would be prohibitive.
However, unsupervised learning also has some limitations. One of the main challenges of unsupervised learning is that it can be difficult to evaluate the quality of the results, since there are no ground truth labels to compare against. In addition, unsupervised learning can be less effective than supervised learning in tasks where a large amount of labeled data is available, since the model is not given any guidance on what patterns to look for in the data.
Overall, unsupervised learning is a useful tool for tasks where labeled data is not available or is difficult to obtain, and can be used to identify patterns and relationships in the data. However, it is important to carefully consider the limitations of unsupervised learning and the potential quality of the results when using it to solve a problem.
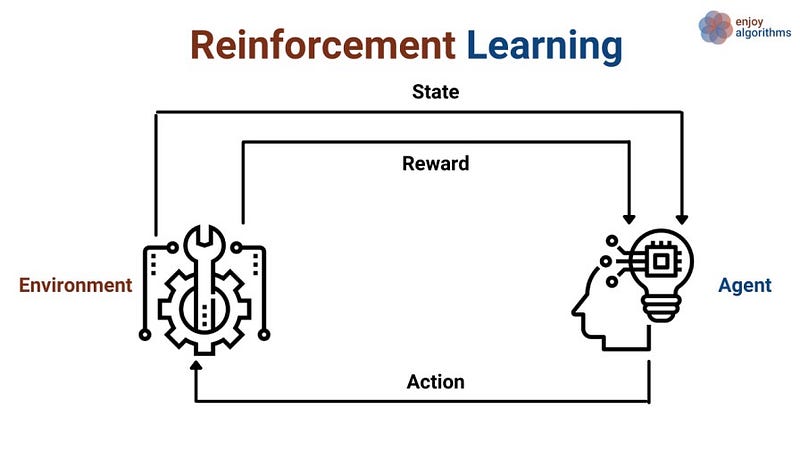
Reinforcement learning or Reinforcement ML
Reinforcement machine learning is a type of machine learning where an agent learns to interact with its environment in order to maximize a reward. In reinforcement learning, the agent receives feedback in the form of rewards or punishments for its actions, and it adjusts its behavior accordingly.
The agent learns by trial and error, continually adjusting its actions based on the rewards it receives. Reinforcement learning has been used to solve a wide range of problems, including control tasks, games, and natural language processing.
One of the main advantages of reinforcement learning is that it can be used to solve complex tasks that require sequential decision-making, such as playing a game or controlling a robot. In these cases, the agent can learn to make decisions that lead to the highest reward over time.
However, reinforcement learning also has some limitations. One of the main challenges of reinforcement learning is that it can be difficult to define the rewards and punishments that the agent should receive. In addition, reinforcement learning can require a large number of interactions with the environment in order to learn an effective policy, which can be time-consuming and computationally expensive.
Overall, reinforcement learning is a powerful tool for tasks that involve sequential decision-making and can be used to learn complex behaviors. However, it is important to carefully consider the challenges of defining the reward function and the potential cost of learning when using reinforcement learning to solve a problem.
Conclusion
In conclusion, we should note that in machine learning, a model is trained on a dataset that includes input features and corresponding output labels. The model makes predictions about new, unseen data based on the patterns it learned from the training data. The model’s predictions are then compared to the true output labels, and the model is adjusted based on the error between its predictions and the true labels. This process is repeated until the model reaches a satisfactory level of accuracy.
In essence, we can say that,
supervised learning involves training a model on labeled data to make predictions about new, unseen data, unsupervised learning involves finding patterns in data without any labels, and reinforcement learning involves an agent learning through trial and error to maximize a reward
You may also like,




