
Super Quick Visual Conversations: Unleashing LLaVA 1.5
Disclaimer: This one needs 8GB GPU

USER: Describe the Image.
ASSISTANT: The image features a group of horses running together in a field. The horses appear to be enjoying their time together, possibly galloping or running freely in the open space.
USER: How many horses are there?
ASSISTANT: There are four horses in the image.
Four? This is where I had to sit up and take note. First I thought the model was hallucinating (literally). Then I looked closely at the image.

This is when I realized the power of the model. So here goes, a super quick tutorial to set up the model and run it on the terminal.
Hat tip to the team behind LLaVA: Large Language and Vision Assistant for open sourcing this model. It competes with GPT4 in image understanding!
Software Specs
Operating System: Ubuntu preferably
Python: version 3.10 and above
Hardware
GPU: For me it was NVIDIA GeForce GTX 1070
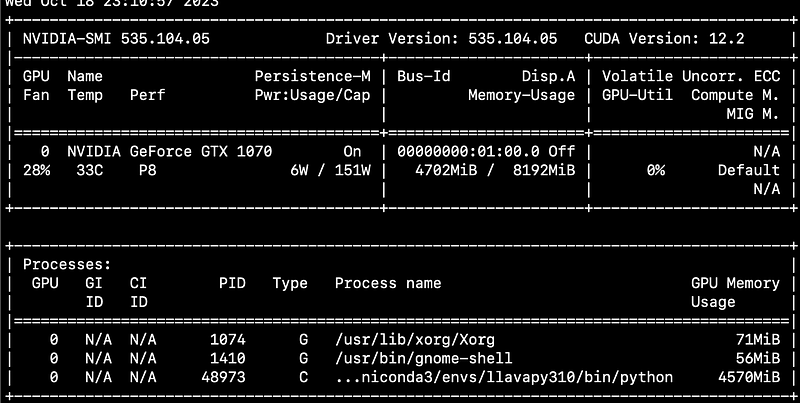
Make sure that the command nvidia-smi shows something like above.
Installation
I have installed pytorch separately with cuda enabled.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Head over to https://pytorch.org/get-started/locally/ to get your installation command.
Following this, I have played by the book. I have downloaded the github repository of LLaVA, moved into the folder and installed the necessary libraries with the below commands.
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA/
pip install -e .Test
Now, inside the LLaVA folder. create a file model_run.py and add the following code.
import argparse
import torch
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
from llava.conversation import conv_templates, SeparatorStyle
from llava.model.builder import load_pretrained_model
from llava.utils import disable_torch_init
from llava.mm_utils import process_images, tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
from PIL import Image
import requests
from PIL import Image
from io import BytesIO
from transformers import TextStreamer
def load_image(image_file):
if image_file.startswith('http://') or image_file.startswith('https://'):
response = requests.get(image_file)
image = Image.open(BytesIO(response.content)).convert('RGB')
else:
image = Image.open(image_file).convert('RGB')
return image
def just_run(args):
# Model
disable_torch_init()
model_name = get_model_name_from_path(args.model_path)
tokenizer, model, image_processor, context_len = load_pretrained_model(args.model_path, args.model_base, model_name, args.load_8bit, args.load_4bit, device=args.device)
if 'llama-2' in model_name.lower():
conv_mode = "llava_llama_2"
elif "v1" in model_name.lower():
conv_mode = "llava_v1"
elif "mpt" in model_name.lower():
conv_mode = "mpt"
else:
conv_mode = "llava_v0"
if args.conv_mode is not None and conv_mode != args.conv_mode:
print('[WARNING] the auto inferred conversation mode is {}, while `--conv-mode` is {}, using {}'.format(conv_mode, args.conv_mode, args.conv_mode))
else:
args.conv_mode = conv_mode
conv = conv_templates[args.conv_mode].copy()
if "mpt" in model_name.lower():
roles = ('user', 'assistant')
else:
roles = conv.roles
image = load_image(args.image_file)
# Similar operation in model_worker.py
image_tensor = process_images([image], image_processor, args)
if type(image_tensor) is list:
image_tensor = [image.to(model.device, dtype=torch.float16) for image in image_tensor]
else:
image_tensor = image_tensor.to(model.device, dtype=torch.float16)
while True:
try:
inp = input(f"{roles[0]}: ")
print("USer said",inp)
except EOFError:
inp = ""
if not inp:
print("exit...")
break
print(f"{roles[1]}: ", end="")
if image is not None:
# first message
if model.config.mm_use_im_start_end:
inp = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + inp
else:
inp = DEFAULT_IMAGE_TOKEN + '\n' + inp
conv.append_message(conv.roles[0], inp)
image = None
else:
# later messages
conv.append_message(conv.roles[0], inp)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
do_sample=True,
temperature=args.temperature,
max_new_tokens=args.max_new_tokens,
streamer=streamer,
use_cache=True,
stopping_criteria=[stopping_criteria])
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:]).strip()
conv.messages[-1][-1] = outputs
if args.debug:
print("\n", {"prompt": prompt, "outputs": outputs}, "\n")
class Args:
def __init__(self,model_path="facebook/opt-350m",model_base=None,image_file=None,device="cuda",conv_mode=None,
temperature=0.2,max_new_tokens=512,load_8bit=False, load_4bit=False,debug=False,image_aspect_ratio="pad"):
self.model_path=model_path
self.model_base=model_base
self.image_file=image_file
self.device=device
self.conv_mode=conv_mode
self.temperature=temperature
self.max_new_tokens=max_new_tokens
self.load_8bit=load_8bit
self.load_4bit=load_4bit
self.debug=debug
self.image_aspect_ratio=image_aspect_ratio
args=Args(model_path="liuhaotian/llava-v1.5-7b",
image_file="https://st.depositphotos.com/1000911/1371/i/450/depositphotos_13712714-stock-photo-horses-run.jpg",
load_4bit=True)
just_run(args)Note the image_file parameter towards the end of the code — you can change that to run the model on the image of your choice. Also at the first turn, it might take a while to download the model.

We try on another image, namely this. Note that this was generated using AI (midjourney):

Let us ask the model if it finds the image weird?
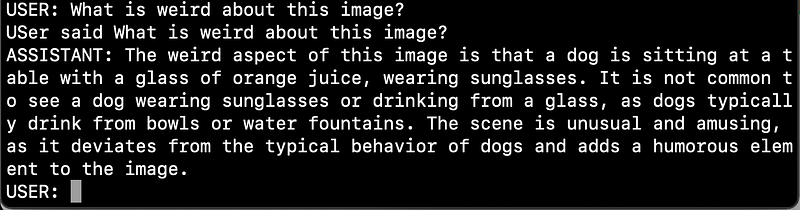
Pretty good.
So there you have it. AI breaking boundaries…
Let’s explore exciting experiments and practical uses for this model, and maybe work together to create something amazing. Take care.
Following are my other llm related articles:
Open Source LLM:
PDF Related
Chatbot Document Retrieval: Asking Non-Trivial Questions
Super Quick: Retrieval Augmented Generation (RAG) with Llama 2.0 on Company Information using CPU
Super Quick: Fine-tuning LLAMA 2.0 on CPU with personal data
Database Related
Super Quick: LLAMA2 on CPU Machine to Generate SQL Queries from Schema
Close Source LLM (OpenAI):
PDF Related
Super Quick PDF-based ChatGPT Tutorial in Python
Chatbot Document Retrieval: Asking Non-Trivial Questions
Database Related
Super Quick: Connecting ChatGPT to a PostgreSQL database

In Plain English
Thank you for being a part of our community! Before you go:
- Be sure to clap and follow the writer! 👏
- You can find even more content at PlainEnglish.io 🚀
- Sign up for our free weekly newsletter. 🗞️
- Follow us on Twitter(X), LinkedIn, YouTube, and Discord.






{kind=link}