Sum of Exponential Random Variables
Deriving the PDF of Erlang distribution
X1 and X2 are independent exponential random variables with the rate λ.
X1~EXP(λ) X2~EXP(λ)
Let Y=X1+X2.
Question : What is the PDF of Y? Where do we use the distribution of Y?
To find a PDF of any distribution, what technique do we use?
👉 We find the CDF and differentiate it. (We have already used this technique many times in previous posts.)
Ok, then let’s find the CDF of (X1 + X2).
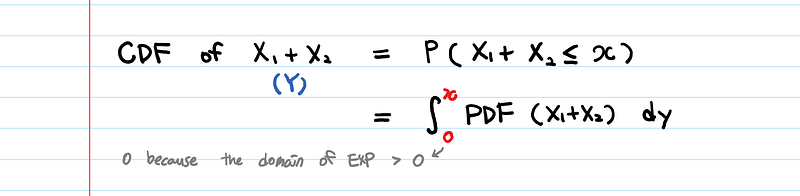
But we don’t know the PDF of (X1+X2). In fact, that’s the very thing we want to calculate.
Ummm… can we say…
∫ PDF(X1+ X2) = ∫ PDF(X1) + ∫ PDF(X2) ???!?!?No, of course not.
If you do that, the PDF of (X1+X2) will sum to 2. (The integral of any PDF should always sum to 1.)
How do I find a CDF of any distribution, without knowing the PDF?
Techniques that we can use for probability calculations: Marginalisation & Independence.

There are two main tricks used in the above CDF derivation. One is marginalizing X1 out (so that we can integrate it over 𝒙1) and the other is utilizing the definition of independence, which is P(𝐗1+𝐗2 ≤ 𝒙|𝐗1) = P(𝐗1+𝐗2 ≤ 𝒙). These tricks simplify the derivation and reach the result in terms of 𝒙.
What’s the difference between 𝐗 and 𝒙?
These are mathematical conventions. 𝐗 is stochastic and 𝒙 is deterministic. For example, let’s say 𝐗 is the number we get from a die roll. So 𝐗 can take any number in {1,2,3,4,5,6}. But once we roll the die, the value of 𝐗 is determined. The notation 𝐗 = 𝒙 means that the random variable 𝐗 takes the particular value 𝒙.
- 𝐗 is a random variable and capital letters are used.
- 𝒙 is a certain (fixed) value that the random variable can take. For example, 𝒙1, 𝒙2, …, 𝒙n could be a sample corresponding to the random variable X.
- Therefore, a cumulative probability P(𝐗 ≤ 𝒙) means the probability that the range of the function 𝐗 is less than a certain value 𝒙. 𝒙 can be any scalar, e.g., 𝐗 ≤ 1, 𝐗 ≤ 2.5, 𝐗 ≤ 888, etc.
- A tilde (~) means “has the probability distribution of,” e.g., X1~EXP(λ).
Now, let’s differentiate the CDF to get the PDF.
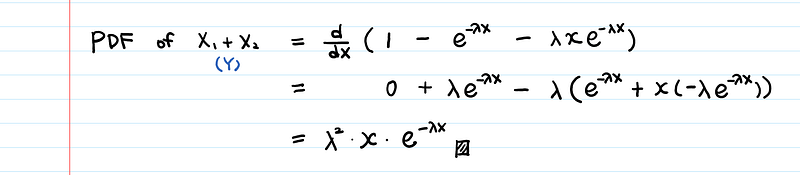
This is an Erlang (2, λ) distribution.
Where is the Erlang distribution used?
In the Poisson Process with rate λ, X1+X2 would represent the time at which the 2nd event happens.
In our blog clapping 👏 example, if you get claps at a rate of λ per unit time, the time you wait until you see your first clapping fan is distributed exponentially with the rate λ.
If you wait for other fans to clap for many more units of time, then you could see 0, 1, 2, … fans.
An Erlang distribution is then used to answer the question:
“How long do I have to wait before I see n fans applauding for me?”
The answer is a sum of independent exponentially distributed random variables, which is an Erlang(n, λ) distribution. The Erlang distribution is a special case of the Gamma distribution. The difference between Erlang and Gamma is that in a Gamma distribution, n can be a non-integer.
Exercise 🔥
a) What distribution is equivalent to Erlang(1, λ)?
Easy. Exponential.
b) [Queuing Theory] You went to Chipotle and joined a line with two people ahead of you. One is being served and the other is waiting. Their service times S1 and S2 are independent, exponential random variables with mean of 2 minutes. (Thus the mean service rate is .5/minute. If this “rate vs. time” concept confuses you, read this to clarify.)
Your conditional time in the queue is T = S1 + S2, given the system state N = 2. T is Erlang distributed.
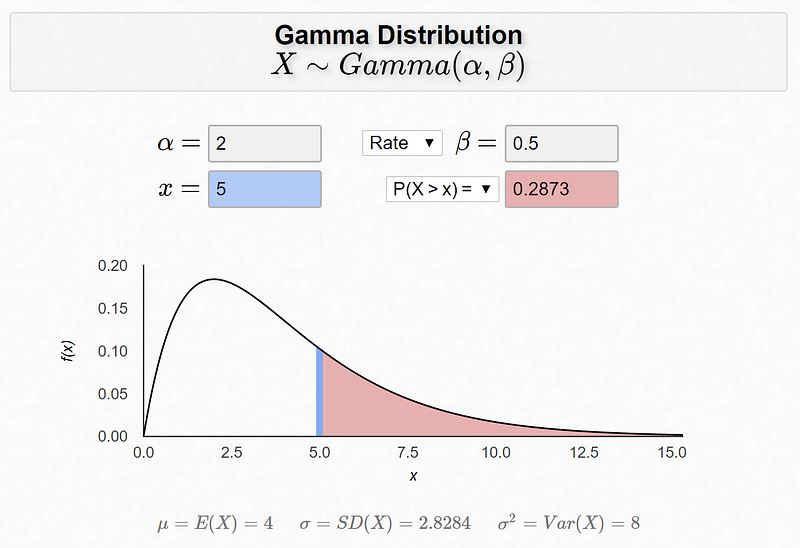
What is the probability that you wait more than 5 minutes in the queue?
Let’s plug λ = 0.5 into the CDF that we have already derived.
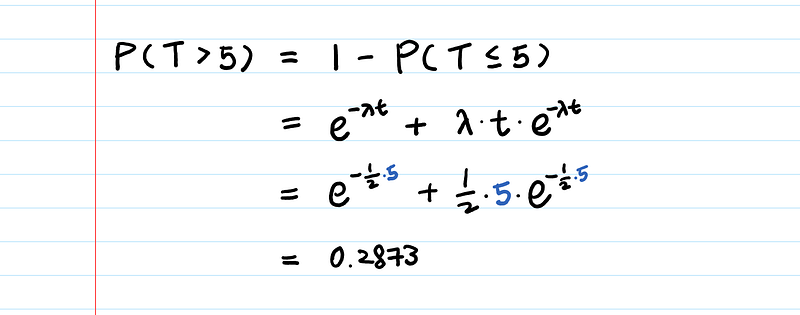
A less-than-30% chance that I’ll wait for more than 5 minutes at Chipotle sounds good to me!
Dr. Bognar at the University of Iowa built this Erlang (Gamma) distribution calculator, which I found useful and beautiful: