Structured Data Analysis using Knowledge Graph + LLM
The post-2020 era is referred to as the digital era. Most companies are re-inventing their working model by digitalizing and automating most parts of their operations that before 2020 were mostly human-centric and time-consuming. This has led to the vast expansion of technological fields like data science and AI. Data scientists are constantly looking for problem statements that can be solved through novel algorithms. Heavy models with millions of parameters are getting trained which takes multiple days to train. The complete development process takes more than a month and a large part of the development process is spent on the annotation of data.
Now, what if we say, that we don’t require the training of models all the time. what if we just use some pre-trained models and focus more on data preparation. This will cut the data annotation and model training time from the complete development process and helps build a solution in a much quicker time span and improve the efficiency of the delivery of the solutions.
Since the release of ChatGPT by OpenAI in 2022, there has been a boom of LLM models in the market which can be directly utilised by calling an API or deploying an open-source LLM model in cloud based environment. These LLM models are trained on millions of data samples which makes it robust to generate new contents.
Querying on large documents using LLM is easier with support of vector database which stores embedding of text and helps retrieve relevant chunks based on the provided query but applying the same process on structured tabular data is bit difficult due to loss of contextual meaning and inter-column correlation. This led to the rise of use of knowledge graph database which can easily capture relationship between columns and retains semantic understanding to help respond to queries in a better way.

To directly check the implementation of code for using Knowledge Graph along with LLM for structured tabular data, please skip to Code Implementation section
Basic Concept
What is Knowledge Graph?
A knowledge graph also known as semantic network is a collection of entities which consists of nodes, edges and labels that helps represents relationship between various objects, facts or categories using a concise graph structure. Any object, entities, person or place can be a node and the edges represents the relationship between each nodes. For e.g., New Delhi and India can be nodes and capital will be the edge label to explain relationship between New Delhi and India. These knowledge graphs are usually stored in the graph database to be used to query or infer factual informations about different concepts based on their nodes and edge attributes
What is Vector Database?
A vector database is a type of database which stores a collection of high-dimensional vectors which are usually mathematical representation of features or attributes used to define semantic meaning or relationship. These high-dimensional vectors has a fixed dimension ranging from tens to thousands depending on data complexity. These vectors can be used to measure similarity between different entities or concepts based on their vector representations. For e.g., “Dog” and “Cat” are more related in the vector space compared to “Dog” and “Car” based on their vector distances
What is Large Language Model (LLM)?
Large Language Models are advanced neural network algorithm which are capable in generating new contents based on their learning over millions of data points. These LLM models are capable of recognizing, summarizing and extracting information from any data samples based on the prompt/query provided to generate content
Comparison between Graph Database & Vector Database
knowledge graph database and vector database are both great in assisting large language models in retrieving/generating information for complex queries. Few factors to consider while choosing between graph database and vector database are:
- Complex Questions: Both knowledge graph and vector database can return response to simple queries like “who is the president of United States?” but knowledge graph outpaces vector databases when it comes to complex queries like “which united state president in past 20 years had least number of criminal charges?”. A knowledge graph looks for and returns precise information based on traversing a graph that is connected by relationships.
- Complete Response: Vector database are likely to return incomplete response as it depends on similarity index and a predefined chunk limit whereas knowledge graph are directly connected by relationship and no. of relationship differ for every entity which helps it to return complete response
- Hallucinations: Knowledge graph have a human-readable representation of data which helps identify misinformation in data, trace back the pathway of the query, and make corrections to it, which can help improve LLM accuracy whereas vector db acts as a black box which provides little to no transparency and no ability to make specific corrections.
Code Implementation
In this section, we will cover the basic implementation of knowledge graph using Large Language Model on structured data with the help of LlamaIndex to create a conversational bot to respond to all our queries related to tabular data
Load Data
import pandas as pd
df = pd.read_csv("GroceryDataset.csv")
df.dropna(axis=1, how='all', inplace=True)
df.dropna(axis=0, inplace=True)
df.reset_index(drop=True, inplace=True)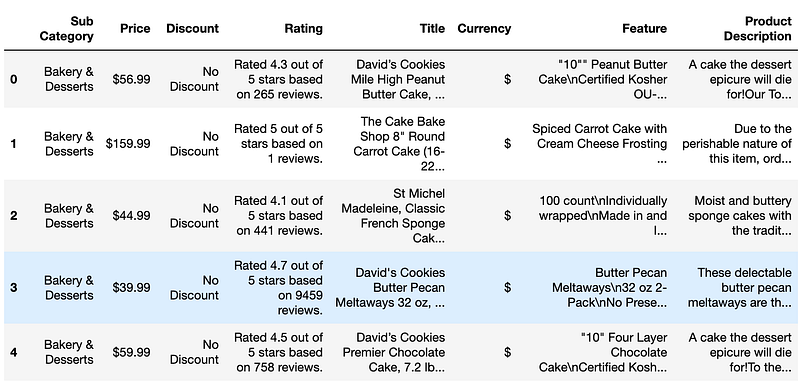
Create LlamaIndex Document object using json
import requests
from llama_index import download_loader
JsonDataReader = download_loader("JsonDataReader")
loader = JsonDataReader()
data = df.to_dict("record")
documents = loader.load_data(data)
len(documents)Load LLM Model
import os
from llama_index.llms import AzureOpenAI
P
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_VERSION"] = "2023-09-01-preview"
os.environ["OPENAI_API_BASE"] = "XXXXXXXXXXX"
os.environ["OPENAI_API_KEY"] = "XXXXXXXXXXX"
llm = AzureOpenAI(
temperature=0,
model="text-davinci-003",
deployment_name="DEPLOYMENT_NAME",
api_key="XXXXXXXXXXX",
azure_endpoint="XXXXXXXXXXX",
api_version="2023-09-01-preview",
)Load Embedding Model
from transformers import AutoModel, AutoTokenizer
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
model_name = "sentence-transformers/all-MiniLM-L6-v2"
tokenizer_name = model_name # usually the same as model_name
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
embedding = HuggingFaceEmbedding(
model_name=model_name,
tokenizer_name=tokenizer_name,
model=model,
tokenizer=tokenizer,
)Setup LlamaIndex Knowledge Graph Index Object
from llama_index import ServiceContext, KnowledgeGraphIndex
from llama_index.graph_stores import SimpleGraphStore
from llama_index.storage.storage_context import StorageContext
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embedding,
chunk_size=512,
chunk_overlap=128
)
graph_store = SimpleGraphStore()
storage_context = StorageContext.from_defaults(graph_store=graph_store)
index = KnowledgeGraphIndex.from_documents(
documents,
max_triplets_per_chunk=int(df.shape[1]),
storage_context=storage_context,
service_context=service_context,
show_progress=True,
include_embeddings=True
)Visualize the created knowledge graph
from pyvis.network import Network
g = index.get_networkx_graph()
net = Network(
notebook=True,
cdn_resources="in_line",
directed=True,
bgcolor="#222222",
font_color="white"
)
net.from_nx(g)
net.show_buttons(filter_=['nodes'])
net.show("example.html")
Now that we have the knowledge graph index setup, we can use this object to analyse our data by providing relevant questions
Setup Knowledge Graph Engine
query_engine = index.as_query_engine(
include_text=True,
response_mode="tree_summarize",
embedding_mode="hybrid",
similarity_top_k=5,
)Let’s provide few queries and see if the knowledge graph engine is able to return correct response
Summarize Data
Query = "Please provide the detail summarization"
response = query_engine.query(
Query,
)
response.responseResponse: ‘\nThe products range in price from $52.99 to $349.99 and include items such as D\’Artagnan Extreme American Wagyu Burger Lovers Bundle, Kirkland Signature Nature\’s Domain Salmon & Sweet Potato Formula Dog Food, Quality Ethnic Foods Halal Chicken Variety Pack, Premium Seafood Variety Pack, Inspire Floral Arrangement, Chicago Steak USDA Prime Beef Wet Aged Boneless Strips & Gourmet Burgers, Alaska Home Pack Frozen Sea Cucumber, Coastal Seafood Frozen Lobster Tails, Sesame Crusted Ahi Tuna Steaks, and Tsar Nicoulai Baerii Caviar 2 oz. Gift Set. Tsar Nicoulai Baerii Caviar 2 oz. Gift Set is a gift basket priced at $99.99 after a $30 discount, rated 4.4 out of 5 stars based on 89 reviews. It includes vacuum sealed caviar jar, 2 oz. jar, farmed Baerii Caviar, 16 piece Blini, 5 oz. Creme Fraiche, and Birthday Full of Happiness Floral Arrangement is a floral priced at $46.99 with no discount, rated 4.3 out of 5 stars based on 5936 reviews. It includes farm fresh flowers, vase and “Happy Birthday” pick, and stems such as stock, roses, spray roses, green balls, mums, gerbera daisies, dianthus, lily grass, cocculos, robelini, and cushion poms. Dry ice should be handled with care and protective cloth or leather gloves should be used when touching it. It is Kosher Star-K and Gluten Free. Tray dimensions are 14" x 10" x 2".’
Query Data
Query = "what is the average price of bakery & desserts?"
response = query_engine.query(
Query,
)
response.responseResponse: ‘ The average price of Bakery & Desserts is approximately $86.24.’
Conclusion
This article was focused on providing a brief introduction to knowledge graph using large language models and the pros and cons of using knowledge graph compared to vector database. The knowledge graph approach can be utilised in various sectors where inter entity relationship becomes important in delivering solution to various stakeholders
Stay tuned to learn more about different approaches we use in day-to-day work life. Follow me on LinkedIn to interact and share ideas: https://www.linkedin.com/in/mdsharique0107/




