
Strategies for Decaying Epsilon in Epsilon-Greedy

The exploration-exploitation dilemma is fundamental to Reinforcement Learning (RL) problems. Early on in training an agent has not learned anything meaningful in terms of associating higher Q-values to certain controls in different states mainly because it hasn’t collected enough experience yet. Later on, after “enough” experience has been collected, it should begin exploiting its knowledge through the Q-values to act optimally in the environment.
How to Decay Epsilon During Training?
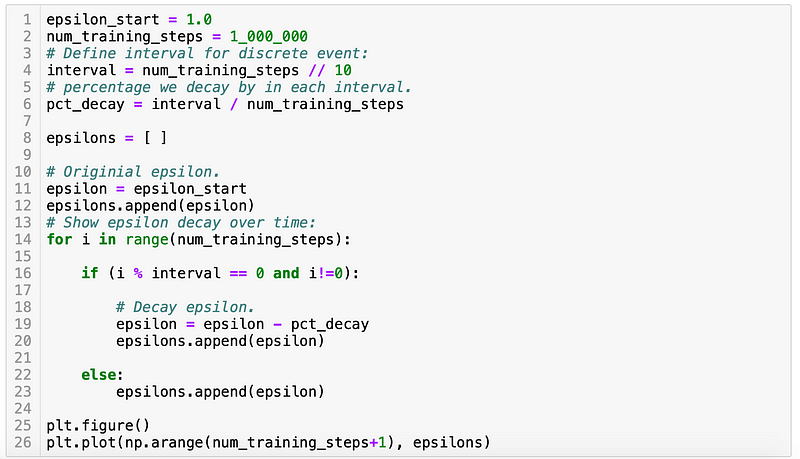
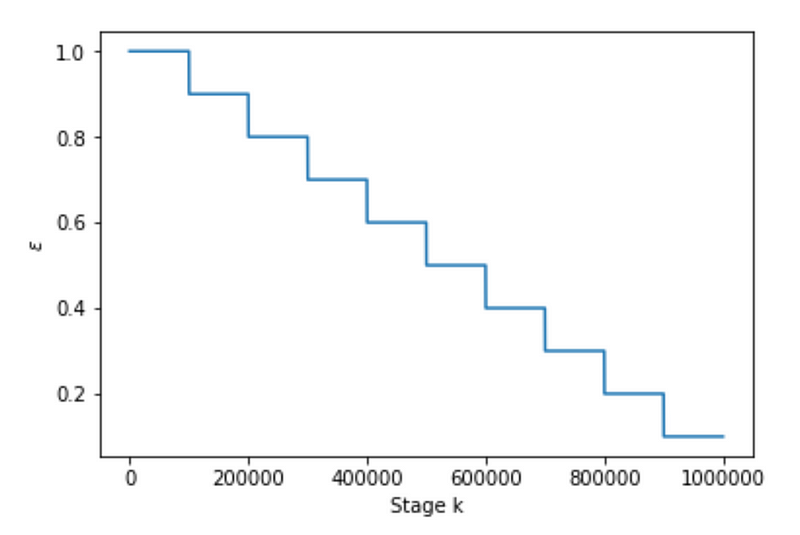
There are a few basic things that must be stated about decaying epsilon for the epsilon-greedy training strategy. In epsilon-greedy the parameter epsilon is our probability of selecting a random control. At the beginning of a training simulation epsilon starts at 1.0 and near the end it should be a very small value, e.g. 0.001 for reasons already discussed.
The reason epsilon should be probability one for selecting a random control starting out training is that we want the agent to explore many different controls across the state space (exploration). The reason we want epsilon small near the end of the training horizon is that we want the agent to exploit what it has learned.
In this article, I present three ways of decaying epsilon effectively and provide the necessary Python code you can add to your training simulation code. I also assume one million training steps, and fixed ending epsilon values, but these values an be played with in your own experiments. The three methods I present for decaying epsilon are:
- Linear Decay
- Exponential Decay
- Discrete Interval Decay

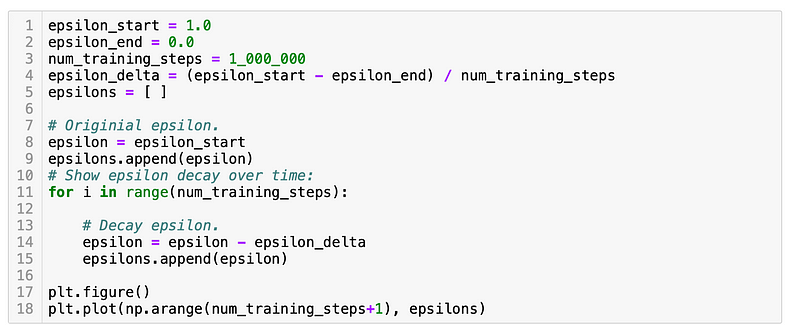
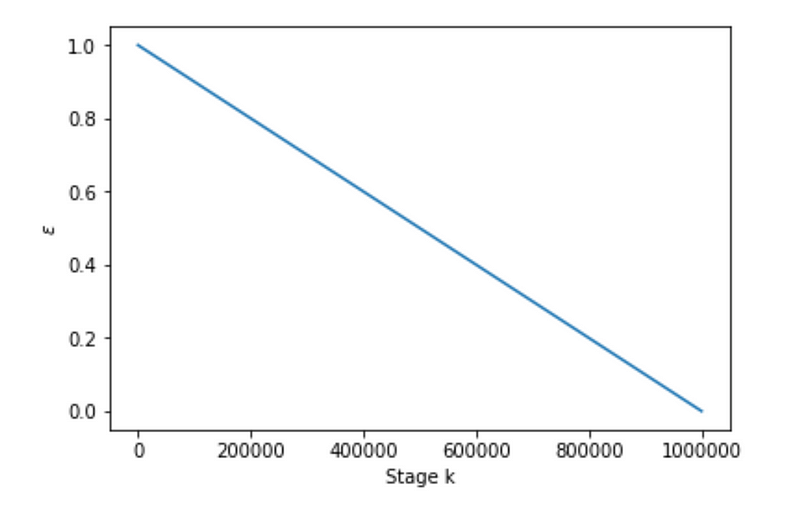
Linear Decay
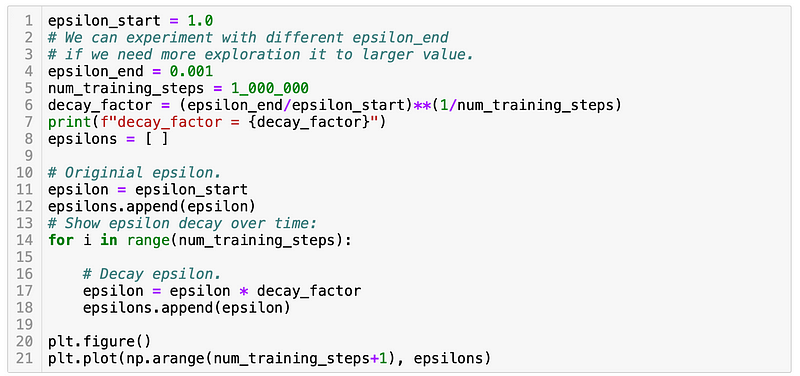
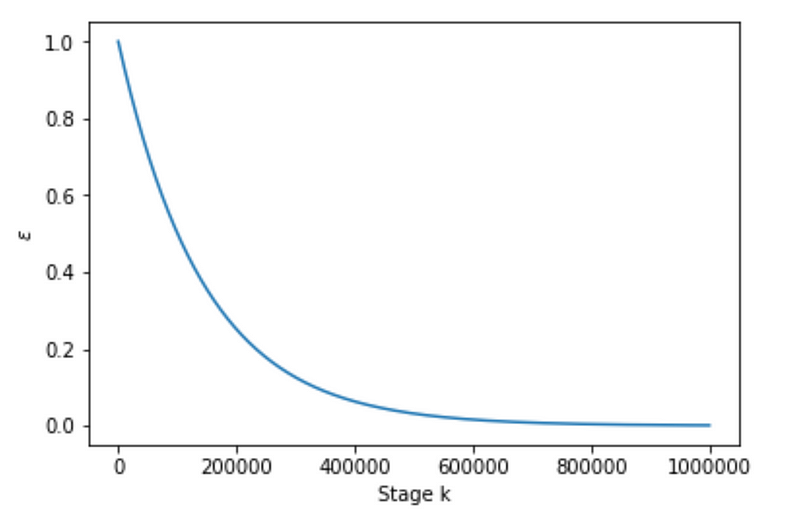
Exponential Decay
Discrete Interval Decay
That’s it for this story. Start learning about RL, Python, and other high-value topics today by firstly following this blog; if you want to stay in the loop and never miss a story of mine then subscribe to my email list. Consider becoming a Medium member to gain unlimited access to my writing and the writing of other authors:
Also, if you’re interested in learning specifically more about Reinforcement Learning (RL), then take a look at this list of stories I have curated:
Until next time,
Caleb





