
Strange Case of Dr Cosine and Mr Relevance
The never-ending dilemma between similarity and relevance, Semantic Similarity Search and hard work in curating our datasets.

I did not misspell the well-known book by Robert Louis Stevenson. A recent paper is questioning the blind usage of Cosine Similarity: it looks like we cannot trust our semantic search anymore.
But honestly… I never trusted it to begin with. At least not blindly!
The underlined outcome seems to point to using huge, powerful (and proprietary) LLMs just for information extraction.
This is insane… and expensive.
So what are our options?
Prologue — Is Cosine-Similarity of Embeddings Really About Similarity?
This is the title of a research paper released less than one week ago by the guys at Netflix.
You can read it yourself, but in the meantime, here is a concise abstract going straight to the points:
Cosine-similarity is the cosine of the angle between two vectors, or equivalently the dot product between their normalizations… This can work better but sometimes also worse than the unnormalized dot-product between embedded vectors in practice… Based on these insights, we caution against blindly using cosine-similarity and outline alternatives.
The main focus here is on the reliability of the cosine-similarity metric; this may become an issue for all of us since the introduction of neural-searches (based on neural networks).
How did we come to this point?
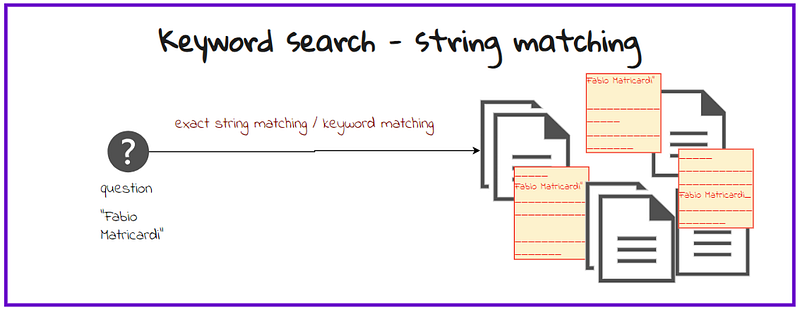
From keyword search to Semantic Search
A few years ago, the only way to solve your questions was to start searching through a giant library card catalog in a library. Each card had details about a book written on it.
In the old days, searching this catalog involved looking for cards with exact matches to your search term. This is like string matching. You simply typed or wrote your search term, and the system would only return cards with that exact phrase on them.
This method is still used in many places today, like:
- Libraries: You can search the library catalog for books by title, author, or specific keywords.
- Newspaper archives: Many archives allow you to search for articles containing certain terms.
While simple and effective for basic searches, string matching doesn’t account for synonyms, different phrasings, or related terms. This is where newer search methods like neural search come in.

The test ground
I decided to test them all—not the RAG, though—because there really is a lot of literature about it, and here on Medium you can find plenty of it.
I took a website FAQ section for my test. Why?
Because it is the best example of a curated dataset! You can easily match a question with its answer, the user intent with the ground truth. I put the data into a dictionary.
listato = [
{'q': 'What is WireGuard?' , 'a': 'WireGuard is a connection protocol used in the Windscribe desktop and mobile applications. It is typically faster than OpenVPN (called UDP and TCP in the apps) and more flexible than IKEv2, making it a great option for securing your online activity.' },
{'q': 'What kind of encryption does Windscribe use?', 'a' : "Windscribe's encryption varies based on the protocol selected, as well as the format of our app you are using: OpenVPN: Our OpenVPN implementation uses the AES-256-GCM cipher with SHA512 auth and a 4096-bit RSA key. Perfect forward secrecy is also supported. IKEv2: Our in-app IKEv2 implementation utilizes AES-256-GCM for encryption, SHA-256 for integrity checks. Desktop and Android apps use ECP384 for Diffie-Hellman key negotiation (DH group 20), and iOS uses ECP521 for Diffie-Hellman key negotiation (DH group 21). WireGuard: WireGuard is an opinionated protocol that uses ChaCha20 for symmetric encryption, authenticated with Poly1305; Curve25519 for ECDH; BLAKE2s for hashing and keyed hashing; SipHash24 for hashtable keys; and HKDF for key derivation."},
{'q': 'What is OpenVPN?', 'a' : 'Our OpenVPN implementation uses the AES-256-GCM cipher with SHA512 auth and a 4096-bit RSA key. Perfect forward secrecy is also supported.'},
{'q': 'What is IKEv2?', 'a' : 'Our in-app IKEv2 implementation utilizes AES-256-GCM for encryption, SHA-256 for integrity checks. Desktop and Android apps use ECP384 for Diffie-Hellman key negotiation (DH group 20), and iOS uses ECP521 for Diffie-Hellman key negotiation (DH group 21).'},
{'q': 'What is WireGuard?', 'a' : 'WireGuard is an opinionated protocol that uses ChaCha20 for symmetric encryption, authenticated with Poly1305; Curve25519 for ECDH; BLAKE2s for hashing and keyed hashing; SipHash24 for hashtable keys; and HKDF for key derivation.'},
{'q': 'Can I use Windscribe without an internet connection?', 'a' : 'In order to use Windscribe, you must have an existing internet connection, such as mobile data, home internet or public WiFi. Windscribe does not provide an internet connection, we simply encrypt and reroute your existing internet connection through our secure VPN servers. This means that the bandwidth you use with the VPN is also being used with your Internet Service Provider (ISP).'},
{'q': 'Where is Windscribe located?', 'a' : 'The actual Windscribe headquarters is based in Toronto, Ontario, Canada. However, we are a diverse company with employees working on three continents, in over 7 countries.'},
]We will use it for the different QA strategies
Keyword matching is like trying to find specific words you’re looking for in that pile. Techniques like tf-idf or BM25 give more weight (importance) to words that appear more often in the document compared to the entire collection of documents (corpus). This helps narrow down the search and is quite fast.
Think of it like sifting through a bag of random items. You can quickly find what you’re looking for if it’s a specific object, but you might miss other relevant things because they’re hidden or not right next to your target item.
Here’s the limitation: keyword matching doesn’t care about the order of the words. Just like jumbling up the items in your bag doesn’t change what’s inside, keyword matching doesn’t consider how the words are arranged. But order matters! “I went to the store” has a different meaning than “Store, to the I went.”
Let’s try BM25's search capabilities. After the imports, we define the function looking for word frequency.
# We also compare the results to lexical search (keyword search). Here, we use
# the BM25 algorithm which is implemented in the rank_bm25 package.
from rank_bm25 import BM25Okapi
from sklearn.feature_extraction import _stop_words
import string
from tqdm.autonotebook import tqdm
import numpy as np
# We lower case our text and remove stop-words from indexing
def bm25_tokenizer(text):
tokenized_doc = []
for token in text.lower().split():
token = token.strip(string.punctuation)
if len(token) > 0 and token not in _stop_words.ENGLISH_STOP_WORDS:
tokenized_doc.append(token)
return tokenized_doc
tokenized_corpus = []
for passage in tqdm(corpus):
tokenized_corpus.append(bm25_tokenizer(passage))
bm25 = BM25Okapi(tokenized_corpus)
tokenized_corpusq = []
for passage in tqdm(corpusq):
tokenized_corpusq.append(bm25_tokenizer(passage))
bm25 = BM25Okapi(tokenized_corpus)
bm25q = BM25Okapi(tokenized_corpusq)So far, it is only preparation. There are 2 sets, as you may notice: one is the list of all the questions (corpusq) and the other is only for the answers (corpus). If a dataset is really well done, you can get amazing results matching your query directly with the questions. But for evaluation purposes, I did it with the answers.
##### BM25 search (lexical search) #####
bm25_scores = bm25.get_scores(bm25_tokenizer(query))
top_n = np.argpartition(bm25_scores, -5)[-5:]
bm25_hits = [{'corpus_id': idx, 'score': bm25_scores[idx]} for idx in top_n]
bm25_hits = sorted(bm25_hits, key=lambda x: x['score'], reverse=True)
print(f"Top-{top_k} lexical search (BM25) hits")
for hit in bm25_hits[0:top_k]:
print("\t{:.3f}\t{}".format(hit['score'], corpus[hit['corpus_id']].replace("\n", " ")))
lscore = f"{hit['score']:.2f}"
ltext = corpus[hit['corpus_id']].replace("\n", " ")Then we pass the query to the bm25 tokenizer, and we retrieve the top 4 hits, re-ordering them by ranking.
So to the question, “Where is Windscribe located?” this is the result:
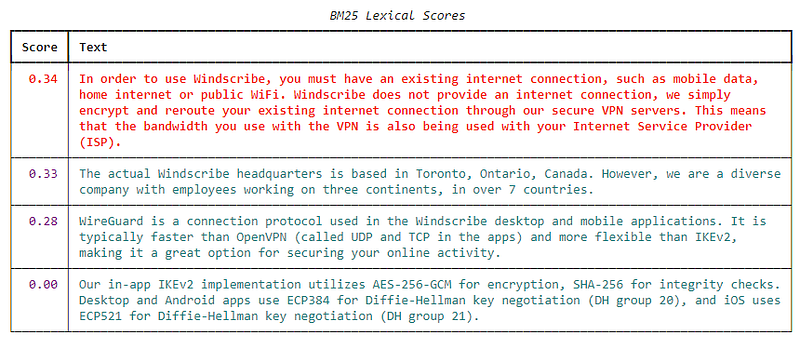
The top one is clearly not the correct one, if we compare the user query to the answers. But if our lexical search was to be compared with the FAQ question…
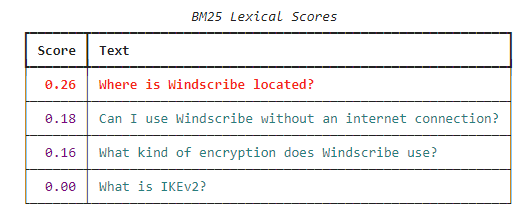
We got it right!

Semantic Search, Dr.Cosine and Mr.Relevance
Neural search steps in here. Instead of directly comparing your search term to the document, it takes a different approach. Imagine the search term and the document being transformed into special codes like unique fingerprints.
Neural search uses a powerful system called a neural network that’s been trained on massive amounts of information. This network can analyze these “fingerprints” and understand the deeper meaning behind the words, even if the order is different.
Neural search can be used on a variety of file types, including images:
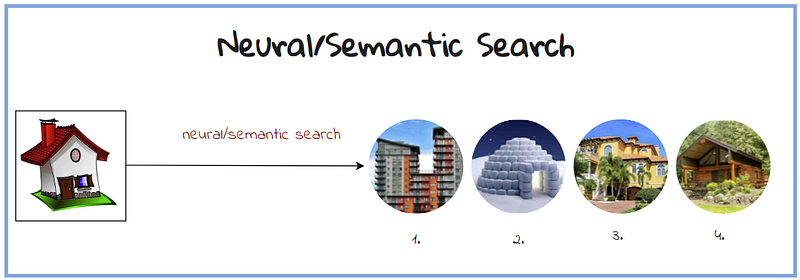
Usually, we refer to Semantic Search mainly in relation to Natural Language, also called NLP.
After the main introduction of Semantic Search algorithms into Web Search Engines (like Google, Bing and so on…) NLP has become a common topic in relation to Retrieval Augmented Generation.
Retrieval-augmented generation (RAG) is an AI framework that combines pre-trained language models, like GPT-4, with a retrieval mechanism. A retrieval mechanism acts as a bridge between the language model and a vast reservoir of information, allowing RAG to retrieve specific data or context from sources like the internet, documents, or databases. This integration enables RAG to generate contextually relevant and precise responses by extracting information from extensive knowledge sources or structured databases. This approach is highly effective for tasks requiring access to up-to-date information.
RAG is only one of many applications of Semantic Search and honestly you don’t need RAG to Generate the Answers!

Here are the options we already have!
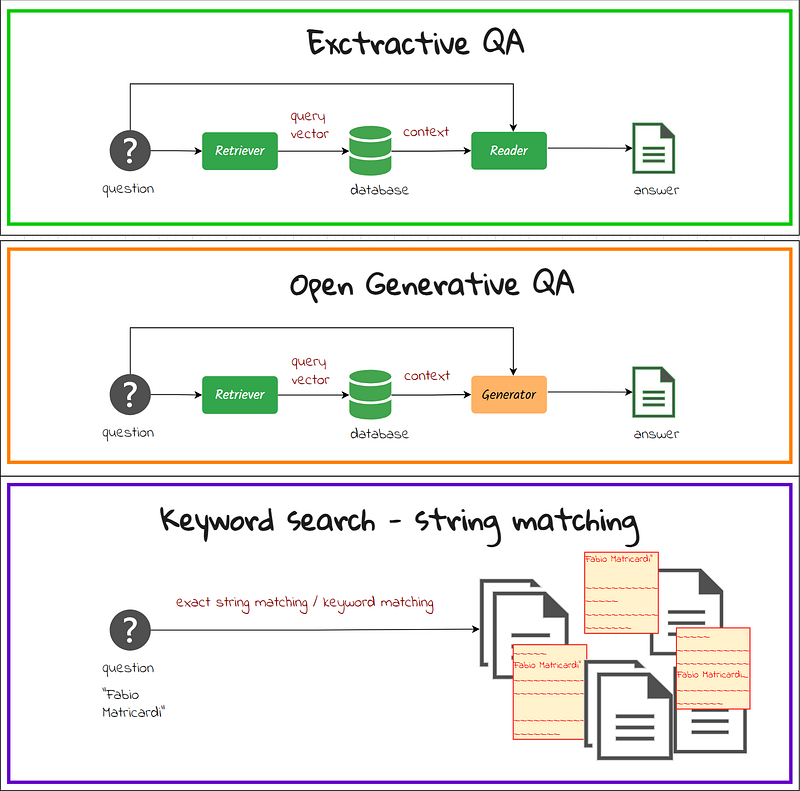
Question Answering variants
QA systems differ in the way answers are created.
- Extractive QA: The model extracts the answer from a context and provides it directly to the user. It is usually solved with BERT-like models.
- Generative QA: The model generates free text directly based on the context. It leverages Text Generation models. This is the classic RAG
Extractive Question Answering
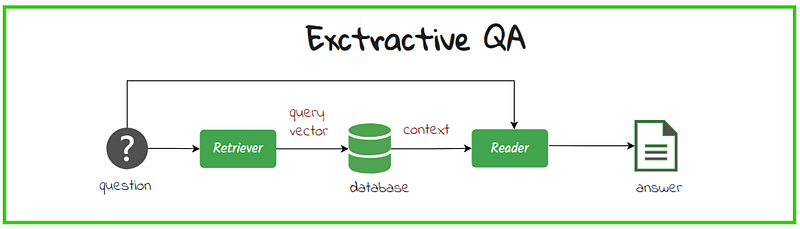
It’s really all in the name.
Focus on the answer: As the name suggests, a question answering (QA) system takes a question and delivers the answer directly, not just a whole document. “Extractive QA” reflects this approach, where the system extracts relevant snippets (from one or more sources) as the answer. In contrast, “generative QA” creates the answer itself, drawing upon a textual knowledge base.
Training on examples: The gold standard for English extractive QA is SQuAD, a dataset of documents paired with corresponding questions and their answer passages. SQuAD serves as the training ground for these systems. Imagine a system like BERT, a powerful language model based on transformers, being fine-tuned on SQuAD to learn the art of question answering.
The dataset that is used the most as an academic benchmark for extractive question answering is SQuAD (The Stanford Question Answering Dataset). SQuAD is a reading comprehension dataset, consisting of questions posed by crowd-workers on a set of Wikipedia articles, where the answer to every question is a segment of text from the corresponding reading passage. It contains 100,000+ question-answer pairs on 500+ articles.
The mechanism that retrieves the context from the database is ours, Dr.Cosine. Usually, dot product and Cosine similarity are the functions used in the vector space to give us the best matches to our query.
Are all the retrieved passages related to Mr.Relevance? I mean, we can get a lot of good retrieved matches, but certainly not all of them will be relevant to the query, right?
There is a way to fix this… and we will see it after the Open Generative QA.
Let’s apply our test using a Bi-Encoder model. The Cross Encoder models are better suited for re-ranking.
from sentence_transformers import SentenceTransformer, CrossEncoder, util
#We use the Bi-Encoder to encode all passages, so that we can use it with semantic search
bi_encoder = SentenceTransformer('multi-qa-MiniLM-L6-cos-v1')
corpus_embeddings = bi_encoder.encode(corpus, convert_to_tensor=True, show_progress_bar=True)
corpus_embeddingsq = bi_encoder.encode(corpusq, convert_to_tensor=True, show_progress_bar=True)We pass the 2 different dataset (all the questions from the FAQ, and another one with all the answers) through the bi-encoder, creating their embeddings.
##### Semantic Search #####
# Encode the query using the bi-encoder and find potentially relevant passages
question_embedding = bi_encoder.encode(query, convert_to_tensor=True)
hits = util.semantic_search(question_embedding, corpus_embeddings, top_k=top_k)
hits = hits[0] # Get the hits for the first query
bihits = sorted(hits, key=lambda x: x['score'], reverse=True)
for hit in bihits[0:top_k]:
bscore = f"{hit['score']:.2f}"
btext = corpus[hit['corpus_id']].replace("\n", " ")
bdb.append({'score' : bscore, 'text' : btext})Then we pass the query to the bi-encoder similarity search, and we retrieve the top 4 hits, re-ordering them by ranking.
So to the question, “Where is Windscribe located?” this is the result:

We got it quite right! The good thing in this is that you can do some experiments and then set a threshold: whatever is below, for example, 0.65 must be considered not a perfect match. You can have the chat-bot reply that “I am not sure…” and then you can give 3 suggested questions for all the matches below the threshold.
So far we simply returned the best text match to our query, without any kind of direct reply to the user question.
In Hugging Face transformers there is a dedicated pipeline for question-answering. It uses specialized models trained on the SQuAD dataset. Let’s see what they do and how to use them.
Extractive LLM
I picked up a small BERT based model trained for QA, called deepset/tinyroberta-squad2. It is one of the smallest specialized models you can find, and it has a Creative Common license CC-by-4.0, so you can even use it in commercial applications.
This model can give answers with 1 line of code.
from transformers import pipeline
tinyroberta = pipeline('question-answering',
model="deepset/tinyroberta-squad2")
question = 'Where is Windscribe located?'
context = 'The actual Windscribe headquarters is based in Toronto, Ontario, Canada. However, we are a diverse company with employees working on three continents, in over 7 countries.'
console.print(tinyroberta(question = question, context = context))As a reply, you get a python dictionary with the reply and few more statistics;
{'score': 0.7020686864852905,
'start': 47,
'end': 71,
'answer': 'Toronto, Ontario, Canada'}As you can see, the pipeline is also giving you a confidence score: This is possible because the QA models are mainly encoders-only or encoder-decoders models. They behave like powerful embeddings, too.

REMARKS: In an amazing paper titled “Choose Your QA Model Wisely: A Systematic Study of Generative and Extractive Readers for Question Answering” the authors conclude that.
it is important to highlight that (1) the generative readers perform better in long context QA, (2) the extractive readers perform better in short context while also showing better out-of-domain generalization, and (3) the encoder of encoder-decoder PrLMs (e.g., T5) turns out to be a strong extractive reader and outperforms the standard choice of encoder-only PrLMs (e.g., RoBERTa).
So for short passages, extractive readers are the best, and encoder-decoder models like T5 family turn out to be good extractive readers.
Open Generative QA
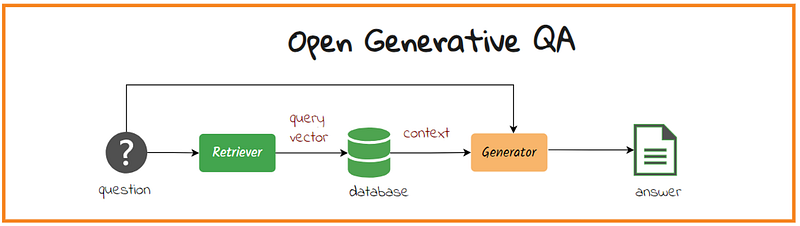
We also have this option… basically, this is the RAG structure. I am presenting it here for the purpose of completeness.

Data laziness is the problem
The Cosine similarity is not the problem. The real issue here is believing that you can plug-and-play whatever data into your LLM and expect that the AI is creating 🪙from 💩.
Garbage in, garbage out
There is no way out of it! We need to invest time to prepare our data and clean it. A good ML engineer knows this lesson very well.
Possible strategy? FAQ-style Question Answering
Frequently Asked Questions (FAQs) serve as curated repositories of question-and-answer pairs designed to address common issues encountered by users.
When someone maintains a well-structured FAQ section, it can significantly alleviate the burden on their customer service team. But imagine the great benefit of a FAQ based Chatbot!??
We can use a 326 Mb model giving our chat-bot the ability to understand the intent of the user (semantic search)… and all of this can run on kind of hardware with bare minimum RAM footprint.
Recent advancements in neural search techniques have further improved the efficiency of FAQ retrieval. One such approach involves augmenting the FAQ dataset with semantic document search capabilities. Unlike traditional keyword-based searches, this method allows users to find relevant answers even when their query wording differs from the original question-answer pair.
In the context of FAQ-style question answering, a Transformer-based sentence encoder plays a pivotal role. It compares the high-dimensional representation of a user’s query to the encoded questions stored in the database. The system then identifies the question with the highest similarity to the query and promptly returns the corresponding answer.
Conclusions
Too often, we expect to set up a huge mechanism to perform a simple job. Simplification is always possible, as long as we know what we need.
Semantic search can be used by itself, even as a chatbot; can you imagine that? And does not require any kind of generative capability.
less is more
I hope you enjoyed the article. If this story provided value and you wish to show a little support, you could:
- Clap a lot of times for this story
- Highlight the parts more relevant to be remembered (it will be easier for you to find it later, and for me to write better articles)
- Learn how to start to Build Your Own AI, download This Free eBook
- Sign up for a Medium membership using my link — ($5/month to read unlimited Medium stories)
- Follow me on Medium
- Read my latest articles https://medium.com/@fabio.matricardi
If you want to read more on the topic here some resources:
Other sources and references

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together!





