
Stacked Bar Charts with Plotly Express
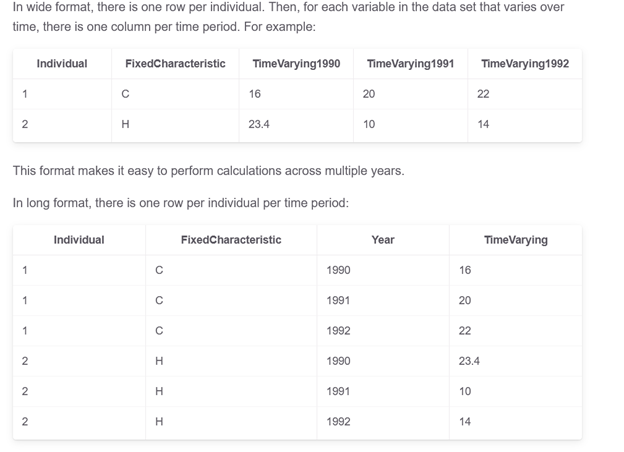
Long Format vs. Wide Format Data

Plotly Express
Plotly, a computing company headquartered in Montreal, Canada, developed plotly.py, an interactive, open-source visualization tool for Python. In 2019, the company released Plotly 4.0 which includes Plotly Express, a high-level wrapper fully compatible with the rest of the Plotly ecosystem.
Plotly Express (PE) is free and provides an object-oriented interface to figure creation. The tool can generate not only standard 2D plots (bars, lines, scatter, pies, etc.), but also complicated 3D scatter and surface charts. PE can take dataframes, lists, and dictionaries as input data for a quick plot generation. Particularly, “most plots are made with just one function call that accepts a tidy Pandas data frame” (1).
Long Format Data, Wide Format Data
Data comes in many varied formats. Related to tabular data (information presented in the form of a table with rows and columns), data can either be in long format (tidy, narrow, or stacked form) or can be in wide format (un-stacked or messy form).
Wide format data has one single column for each variable, while in the long format each row is a single variable-identifying combination. Long format is most convenient for filtering and performing some types of aggregations, while wide format is typical for data collected over time.
The Pandas library in Python has several methods to convert long format data to wide format: df.pivot().reset_index();df.pivot_table();df.groupby();pd.crosstab.
The process of converting from long form to the wide one is usually described as pivoting.
To convert from wide form to long form you can use: df.melt()or df.wide_to_long().
We are probably more familiar with the wide format since it is the format in which we are used to working in Excel spreadsheets. So, this format is intuitive and easier to understand. Tables with wide format are suitable for summarized information. Although long format data is seen less often, it is easy to store, allows quick transformations to other types, and is convenient for certain visualization tools like Seaborn. Tables with long format are suitable for consecutive data records.
The company released Plotly.py version 4.8 on May 26, 2020. Previous releases only supported long format Pandas dataframes. From now on, PE also operates with wide form tabular data. They also claim to work on mixed-form data, a hybrid between long-form and wide-form data. The following 2D-Cartesian functions can operate on wide-form and mixed-form data: px.scatter, px.line, px.area, px.bar, px.histogram, px.violin, px.box, px.strip, px.funnel, px.density_heatmap and px.density_contour.
Stacked Bar Charts
Stacked bar charts (SBC) show the quantitative relationship that exists between a main categorical variable and its subcategories. Each bar represents a principal category and it is divided into segments representing subcategories of a second categorical variable. The chart shows not only the quantitative relationship between the different subcategories with each other but also with the main category as a whole. They are also used to show how the composition of the subcategories changes over time.
Stacked Bar Charts should be used for Comparisons and Proportions but with emphasis on Composition. This composition analysis can be static -for a certain moment in time- or dynamic -for a determined period of time-.
SBC are represented through rectangular bars that can be oriented horizontally or vertically just like standard bar charts. They are two-dimensional with two axes: one axis shows categories, the other axis shows numerical values. Each principal category is divided into segments representing subcategories of a second categorical variable. The quantity of each subcategory is shown by the length or height of rectangular segments that are stacked end to end horizontally or vertically. The final height or length of each bar represents the total amount of each principal category (except in 100% stacked bar charts).
Equivalent subcategories must have the same color in each bar so as not to confuse the audience. Some space is usually left between principal bars to clearly indicate that they refer to discrete groups.
There are two different types of SBC:
1.- Simple Stacked Bars place the absolute value of each subcategory after or over the previous one. The numerical axis has a scale of numerical values. The graph shows the absolute value of each subcategory and the sum of these values indicates the total for the category. Usually, the principal bars have different final heights or lengths.
2.- 100% Stacked Bars place the percentage of each subcategory after or over the previous one. The numerical axis has a scale of percentage figures. The graph shows the percentage of each segment referred to the total of the category. All the principal bars have the same height.
Stacked Bar Charts with Plotly Express
We worked with a dataset downloaded from Kaggle [2]. The dataset consists of 10,000 bank customers mentioning their age, salary, education level, marital status, credit card limit, credit card category, and additional features. The bank manager is disturbed with customers leaving their credit card services (attrited customers vs. existing customers). So, we are going to determine if there is any relationship between some categorical variables (education level, marital status) and the attrition condition.
First, we imported Plotly Express as px, the Pandas library as pd and converted our csv file into a dataframe:
import pandas as pdimport plotly.express as pxpath = 'your path'df = pd.read_csv(path + 'CreditCardCustomersCols.csv', index_col =
False, header = 0, sep = ';', engine='python')Then, we selected Customer Condition as our main categorical variable and Education Level as the second categorical variable. In the Kaggle dataset, the customer condition is described by the Attrition_Flag column [2]. As the records in the dataset are in long form, we converted them to wide form using df.groupby(). We used the function size() to count the number of elements to plot in absolute values (Counts) or percentage values (Percentage).
df_stack=df.groupby(['Attrition_Flag','Education_Level']).
size().reset_index()df_stack['Percentage']=df.groupby(['Attrition_Flag',
'Education_Level']).size().groupby(level=0).apply(lambda
x:100 * x/float(x.sum())).valuesdf_stack.columns= ['Attrition_Flag', 'Education_Level', 'Counts',
'Percentage']df_stack['Percentage'] =
df_stack['Percentage'].map('{:,.2f}%'.format) For the stacked bars in this article, the Plotly Express function is px.bar and the corresponding parameters are: data_frame; x= a name of a column in data_frame representing the main categorical variable; y= a name of a column in data_frame representing the absolute or percentage values of each subcategory; color a name of a column in data_frame representing the subcategories of the second categorical variable; barmode determines how bars at the same location coordinate are displayed on the graph. With “stack”, the bars are stacked on top of one another. We can choose barmode = ‘overlay’ to plot the bars over one another for overlapped bar charts, or barmode = ‘group’ to place bars beside each other for clustered bar charts (https://towardsdatascience.com/clustered-overlapped-bar-charts-94f1db93778e).
We updated the chart with update.layout: set the title, the name of the x-axis, the name of the y-axis, and set the figure dimensions with width and height. Finally, we draw the chart using the default template (plotly, “Histograms with Plotly Express, Themes & Templates”, https://towardsdatascience.com/histograms-with-plotly-express-e9e134ae37ad).
fig = px.bar(df_stack, x = 'Attrition_Flag', y = 'Counts', color =
'Education_Level', barmode = 'stack')fig.update_layout(title = "Education Level Customers' Composition",
xaxis_title = 'Customer Condition', yaxis_title = 'Counts',
width = 1600, height = 1400)fig.show()
Figure 1 shows a simple stacked bar of the composition of the educational level of the bank’s customers. This graphical representation does not allow us to make a good comparison, so we decided to plot the same data with a 100% stacked bar (y=’Percentage’):
fig2=px.bar(df_stack, x='Attrition_Flag', y='Percentage',
color='Education_Level', barmode ='stack')fig2.update_layout(title = "Education Level Customers' Composition",
xaxis_title = 'Customer Condition', yaxis_title =
'Percentage', width = 1600, height = 1400)fig2.show()
Now we can make a visual comparison, but it would be better if we can include the numerical values:
fig3=px.bar(df_stack,x='Attrition_Flag',y='Percentage',color=
'Education_Level', barmode = 'stack',
text=df_stack['Percentage'])fig3.update_layout(title = "Education Level Customers' Composition",
template = 'simple_white', xaxis_title = 'Customer Condition',
yaxis_title = 'Percentage', width = 1600, height = 1400)fig3.show()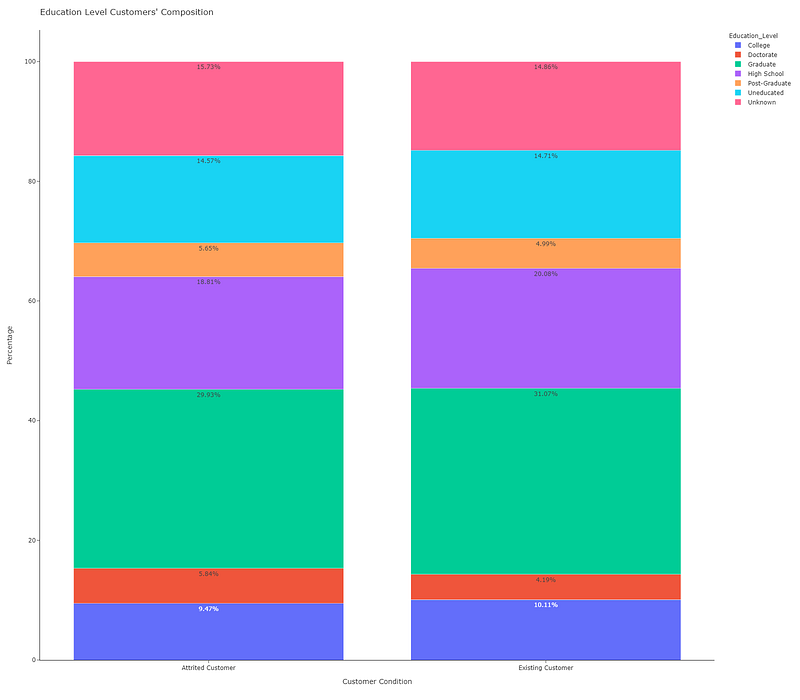
We used text=df_stack[‘Percentage’] for the annotations. We also changed the template to ‘simple_white’, a minimalist template for a clear chart. Now, we can make a proper comparison, as a result of which we can claim that there are no significant differences in the level of education between attrited customers and existing ones.
Finally, we want to know if the marital status has any relationship with the attrition condition (color = ‘Marital_Status’):
fig4= px.bar(df_stack2, x = 'Attrition_Flag', y = 'Percentage',
color = 'Marital_Status', barmode = 'stack',
text=df_stack2['Percentage'])fig4.update_layout(title = "Marital Status Customers' Composition ",
template = 'simple_white', xaxis_title = 'Customer Condition',
yaxis_title = 'Percentage', width = 1600, height = 1400)fig4.show()
Similarly, we can affirm that there are no significant differences in marital status between attrited customers and existing ones.
To sum up:
You can draw Simple Stacked Bars or 100% Percent Stacked Bars with a few lines of code;
It is usual to make a previous conversion of the dataset records from a long format to a wide format;
Be aware that although the long format is also called stacked, better storytelling is obtained with stacked bars with wide or unstacked data.
If you find this article of interest, please read my previous (https://medium.com/@dar.wtz):
“Scatter Plots with Plotly Express, Trendlines & Faceting”
“Histograms with Plotly Express, Themes & Templates”
References
[1]: https://readmedium.com/introducing-plotly-express-808df010143d
[2]: https://www.kaggle.com/sakshigoyal7/credit-card-customers