
Stable Diffusion 2.0 Released — This Is Massive

Stability AI dropped the second version of its widely popular and open-source image generator, Stable Diffusion. Compared to the first model, version 2.0 has a lot of big improvements and new features.
What’s New?
- Brand new text encoder (OpenCLIP), developed by LAION
- Upscaler Diffusion model that enhances the resolution of images by a factor of 4
- Brand new depth-guided stable diffusion model
- Brand new text-guided inpainting model
Let’s dive in and take a look at each one of them.
New Text Encoder
The new diffusion model is trained from scratch with 5.85 billion CLIP-filtered image-text pairs.
The result is a stunning high-definition image like this.

Stable Diffusion 2.0-v is a so-called v-prediction model. Further filtration is performed to remove adult content using LAION’s NSFW filter.
New Upscaler
Stable Diffusion 2.0 can now generate results with resolutions of 2048x2048 or more.

You can download the upscaler from here and run it on the Gradio or Streamlit demos.
Depth Recognition
This feature is what I am most curious about.
SD 2.0 can now make depth estimates for the image-to-image feature using MiDaS (Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-Dataset Transfer).
Take a look at this example:

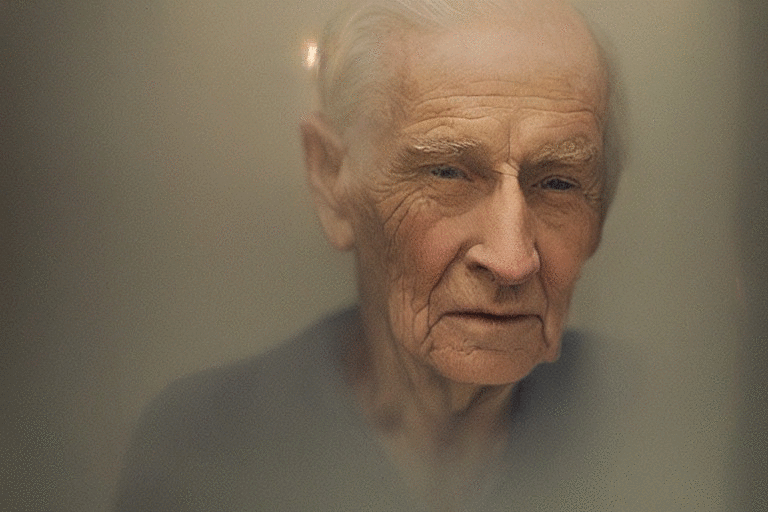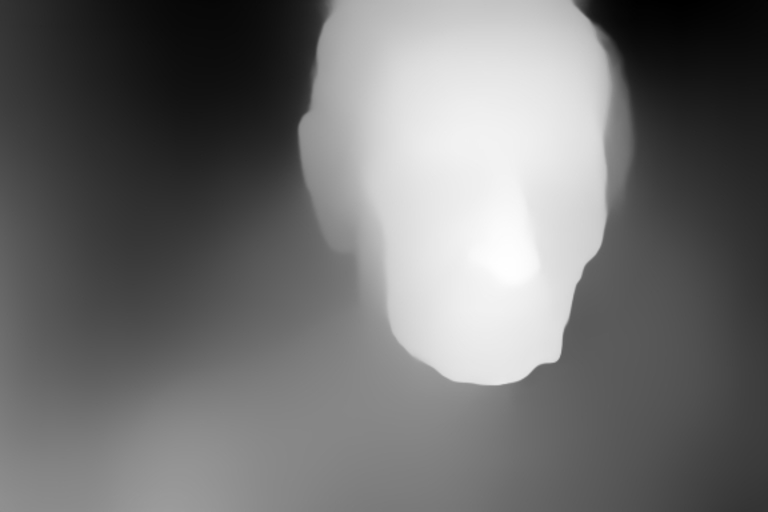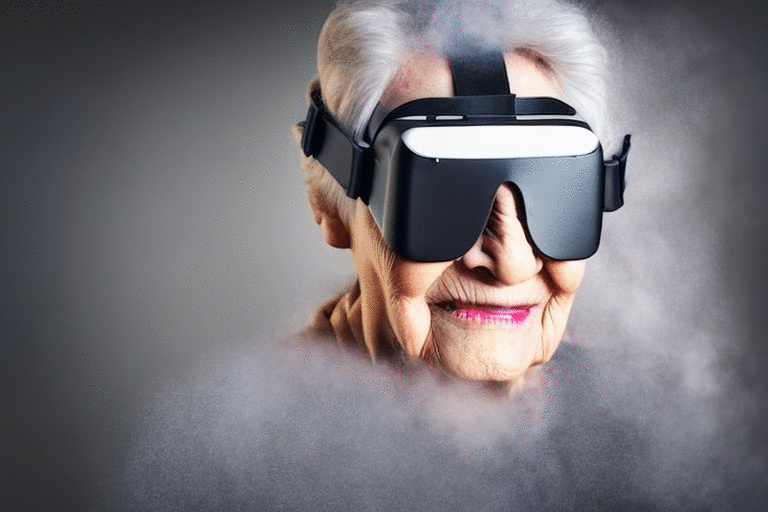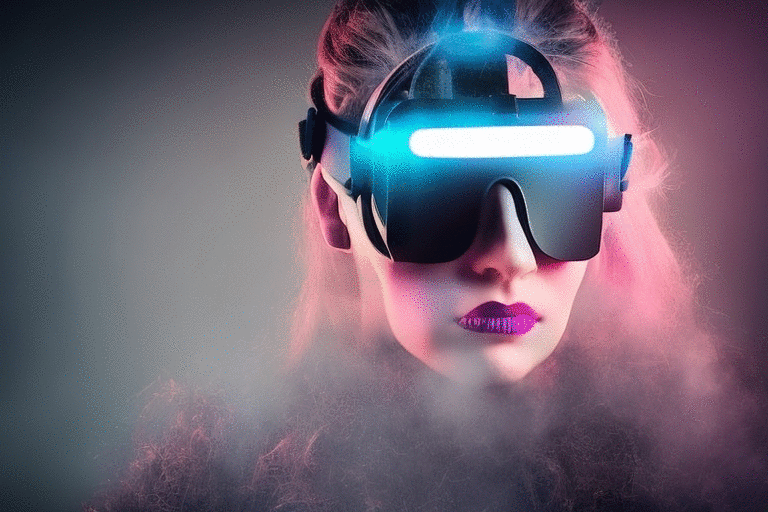
This is absolutely incredible.
Text Guided Inpainting Model
SD 2.0 now supports text-guided inpainting. It means you can simply describe in natural language what parts of the image you want to modify.

The project is still open source. You can download or fork the project from GitHub.
Try It Yourself
The demo application is accessible via the HuggingFace app => https://huggingface.co/spaces/stabilityai/stable-diffusion
Unfortunately, there are way too many users using the app right now, so I cannot provide sample images. I’ll update this article once the web app becomes accessible.
The new version will also be available in DreamStudio in the coming days.
If you’re interested in accessing the service via API, you can check out the documentation here.
Overall, I am in awe of the people behind this technology. Many thought we were going closed-source, but here we are. Let me end with this quote from Stability AI.
This is the power of open source: tapping the vast potential of millions of talented people who might not have the resources to train a state-of-the-art model, but who have the ability to do something incredible with one.
Read the full announcement here => https://stability.ai/blog/stable-diffusion-v2-release




