
Stable Diffusion: New And FREE Text-To-Image AI Tool

In the world of text-to-image AI generator models, OpenAI’s Dall-E2 is an obvious pick for the best tool that’s currently available.
It does, however, have a significant artificial limitation: it is unable to produce images of well-known individuals, including politicians and celebrities. Additionally, using the service has a price tag attached to it.
There is now a completely free competitor that functions practically identically to Dall-E2 but without as many filters — Stable Diffusion.
Let’s discuss a few topics.
- What is Stable Diffusion?
- How does it work?
- How to get early access?
- My first generated images
What Is Stable Diffusion?
On Stability AI’s website, Stable Diffusion is described as a text-to-image model that will enable billions of people to produce beautiful art in a matter of seconds.

This model employs a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts, much like Google’s Imagen does. The model uses a GPU with at least 10GB VRAM and is relatively lightweight with an 860M UNet and 123M text encoder.
How Does It Work?
Stable Diffusion separates the image generating process into a “diffusion” process at runtime. Starting with only noise, it gradually improves an image until there is no noise left at all, bringing it more and closer to a provided text description.

Over the course of a month, Stability AI trained Stable Diffusion on a cluster of 4,000 Nvidia A100 GPUs operating in Amazon Web Services. Ludwig Maximilian University of Munich’s CompVis machine vision and learning research group directed the training, and Stability AI provided the computing resources.
Through its Discord server, Stability AI has made the Stable Diffusion model accessible to a select group of users.
How To Get Early Access
Navigate to the beta sign-up portion of the official Stability.ai website.

Complete the sign-up process and wait for the confirmation email.
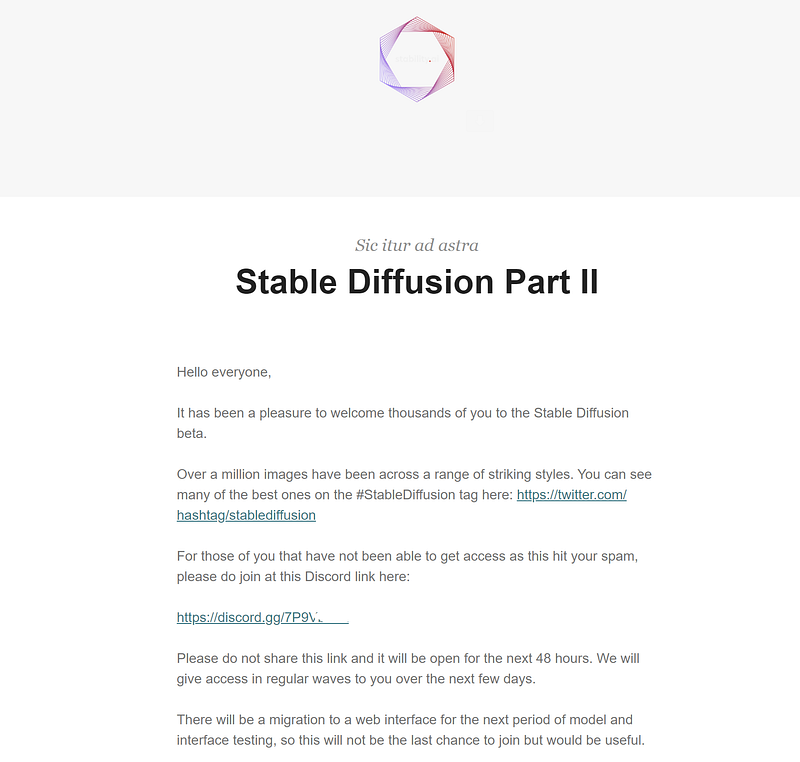
Check your spam folder occasionally since mine went right there.
The email will contain a link that will take you to the Discord dashboard. Read the terms of service in the dashboard and follow the instructions to gain access to the Dream channels.
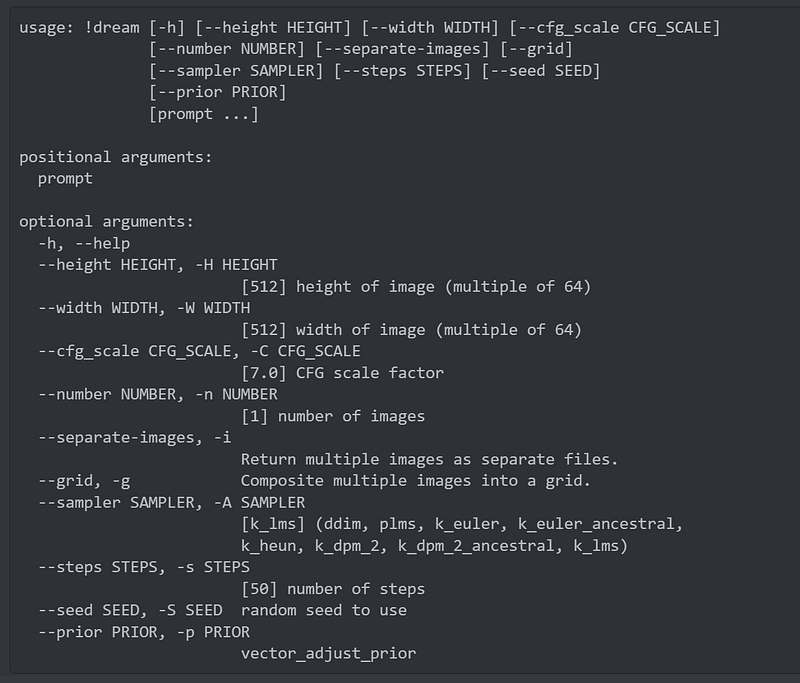
Once you get access to the Dream channels, input your descriptive text in the chat box. The prompt should be in this format:
My First Generated Images
I’m fortunate that I was approved in a short time to use the AI tool for myself. Here are a couple of the pictures I generated.
Prompt: !dream “Old viking woman with braids in gray hair wearing fur and jewelry :: very detailed, symmetric, unreal engine, rim-light” -i -S 474323078
I was quite aback by how rapidly the bot produced this 512x512 image. It took just five seconds.
Additionally, in comparison to other text-to-image AI generator models like Disco Diffusion or MidJourney, Stable Diffusion can create portraits pretty well. The details are spot-on, and the facial characteristics are symmetrical.
Prompt: !dream “HQ photo face picture of Shia Labeouf sitting on a throne wearing a golden crown”
Stable Diffusion does a pretty good job with celebrity faces too. It can even mix the faces of famous people.
Prompt: !dream “jean-claude van damme as tyrion lannister”
I feel like the meme game is about to undergo a revolution with this AI power.
How about animals?
Prompt: !dream “a photo of a dog studying for an exam”
No problem. Here are more examples.


Okay, that’s all I have for today.
Go ahead and sign-up to get access and try the tool yourself. Your imagination is the only constraint on the unlimited possibilities.
Final Thoughts
I personally have mixed thoughts about Stable Diffusion.
Although the tool produces some of the most impressive images, it appears to be more permissive than its competitors.
Stability AI doesn’t have a clear policy prohibiting pictures of famous people. That might make it simple for bad actors to execute deep fakes.
The lack of strong countermeasures also allows some users to generate offensive or lude images.
I hope the engineers behind this technology are already working on taking significant safety measures by formulating innovative tools to help mitigate potential harms before the service gets released to the public.




