
Stable Diffusion 3 vs. DALL·E 3: Which is better?

Recently, the preview version of Stable Diffusion 3 has made its debut!
Although this AI painting model has not been fully launched yet, the official preview application channel has been opened.
And the good news is, an open-source version will be released later!
This model suite is really powerful, with parameter ranges from 800M to 8B, offering a wide variety of choices to meet whatever creative needs you may have.
Stability AI shared the two core technologies behind the development of Stable Diffusion 3: Diffusion Transformer and Flow Matching.
What’s the magic behind these two technologies?
And what are the differences in principle between Stable Diffusion 3 and DALL·E 3?
Let’s delve into this analysis together.
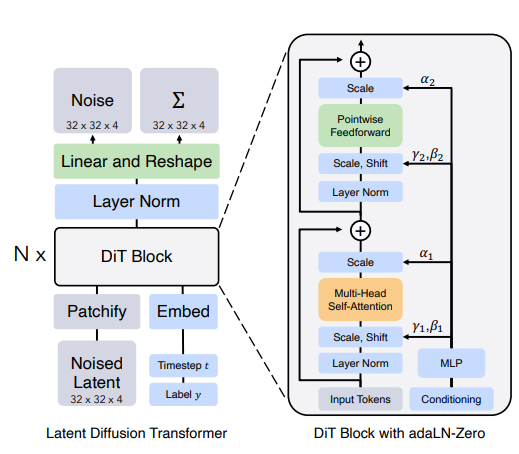
Stable Diffusion 3’s Diffusion Transformer
Due to limited space, I’ll briefly review the U-Net architecture.
On the basis of the original U-Net, a cross-attention module is inserted, ingeniously introducing the prompt text description we input, thus helping us freely control the content of AI painting.
U-Net is used in diffusion models to predict noise.
The U-Net used in AI painting is actually an enhanced version of U-Net model that incorporates the idea of Transformer.
Latent Diffusion Transformer (DiTs) replaces the U-Net structure in diffusion models.
Using a purely Transformer structure.
The input and output “resolution” of the Transformer structure can be the same, and it naturally comes with a cross-attention mechanism.
The diffusion prior based on Transformer does not predict the noise value at each step, but directly predicts the denoised image representation at each step.
This method improves raw image performance and efficiency!

A similar architecture has already been used in DALL-E 2 version.
Stable Diffusion 3’s Flow Matching
Flow Matching is a new generative model framework that simplifies the training of Continuous Normalizing Flows (CNF).
This framework does not rely on complex simulations or log-likelihood estimates but directly deals with the vector field that generates the target probability path.
In simple terms, Flow Matching provides us with a map (vector field) and a route (probability path), allowing us to understand more clearly how data is generated.
With this map and route, we can train generative models more easily, teaching them to generate the data we want from noise.
Flow Matching also introduces a loss function called Conditional Flow Matching (CFM), which makes model training easier.
At the same time, it supports various probability paths, including diffusion paths and OT paths, giving us more options when training models.
Technical Principle Comparison
DALL-E 3 has made numerous innovations and improvements in its methods.
It abandoned the unCLIP model design philosophy and instead drew from the essence of AI models like Imagen and Stable Diffusion to create a new generation “technology fusion body.”
DALL-E 3 uses Dataset Recaptioning technology to regenerate image titles, all of which are generated by GPT-4 Vision.
Simply put, using ChatGPT to expand on the prompts provided by users is also to make the input prompts of DALL-E 3 closer to the training data paradigm, avoiding the model “crashing.”
Stable Diffusion 3 uses Flow Matching to improve generation efficiency.
a painting of an astronaut riding a pig wearing a tutu holding a pink umbrella, on the ground next to the pig is a robin bird wearing a top hat, in the corner are the words “stable diffusion”


Interestingly, DALL-E 3 no longer follows the previous generation’s unCLIP scheme but instead introduces new tricks, incorporating a VAE structure, playing a set similar to Stable Diffusion.
Moreover, DALL-E 3 specially added a diffusion model decoder, placed between the latent representation post U-Net denoising and the VAE decoder.
However, Stable Diffusion 3, on the other hand, is doing the opposite, actually planning to remove the U-Net structure.
Conclusion
Through comparison, we find that AI models are a process of learning from each other.
The quality of AI models mainly depends on three key elements:
1. An excellent foundational large language model. 2. High-quality training materials. 3. Suitable algorithms matched to the task and hyperparameters that have been repeatedly tuned.
This article is my experience sharing. Once the comprehensive review of Stable Diffusion 3 is out, I will update with another article, and comments are welcome!
If you enjoyed this story, feel free to subscribe to Medium, and you will get notifications when my new articles will be published, as well as full access to thousands of stories from other authors.
I am Li Meng, an independent open-source software developer, author of SolidUI, highly interested in new technologies, and focused on the AI and data fields. If you find my content interesting, please follow, like, and share. Thank you!

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together!
