
Stable Diffusion 2: The Good, The Bad and The Ugly
One step forward, one step back

On 24 Nov 2022, Stability.AI announced the public release of Stable Diffusion 2.0, a big update to the previous version with breaking changes. At the time of this writing, it has received mixed reactions from the community. The new architecture was praised for its state-of-the-art features, but at the same time, it was criticized for the direction of the StabilityAI.
StabilityAI released the following checkpoints for version 2:
512-base-ema.ckpt— Version 2 checkpoint to generate 512x512 images.768-v-ema.ckpt— Checkpoint based on512-base-ema.ckpt. It was further fine-tuned using a v-objective on the same datasets. Able to generate 768x768 images natively.512-depth-ema.ckpt—Checkpoint based on512-base-ema.ckptwith an extra input channel to process the (relative) depth prediction produced by MiDaS. It is a depth-guided diffusion model. Good for image to image generation.512-inpainting-ema.ckpt— Version 2 checkpoint of the inpainting model to inpaint images in 512x512 resolution.x4-upscaling-ema.ckpt— Super resolution upscaler diffusion model to generate images with resolution of 2048x2048 or higher.
This article covers some of the facts of Stable Diffusion 2.0 and my personal opinions.
Training Data
Generally, Stable Diffusion 1 is trained on LAION-2B (en), subsets of laion-high-resolution and laion-improved-aesthetics.
laion-improved-aesthetics is a subset of laion2B-en, filtered to images with an original size
>= 512x512, estimated aesthetics score> 5.0, and an estimated watermark probability< 0.5.
On the other hand, Stable Diffusion 2 is based on a subset of LAION-5B:
- laion2B-en 2.32 billion images with texts in the English language
- laion2B-multi 2.26 billion images with texts from 100+ other languages
- laion1B-nolang 1.27 billion images with unknown languages texts (could not be clearly detected)
The datasets is then filtered for explicit pornographic material, using the LAION-NSFW classifier with punsafe=0.1 and an aesthetic score >= 4.5.
In other words, Stable Diffusion 2 used a larger, NSFW-filtered datasets for training. Also, the second phase of training is based on images with resolution higher or equal to 512x512.
The Good
The new release ensures that StabilityAI resolves the long-standing legal problems related to child pornography and deep fakes. Also, the new model generates better images in certain areas. From the test conducted by the community, it seems to do well for realistic photography (non-human), lighting in photo-realistic scenes, 3D renders and designs.
Here is an example of birds generated using Stable Diffusion 2.0.
The Bad
Based on user feedback, you can still generate nudes but the generated images tend to lack any sexual attractiveness. Also, the new model performs poorly for images related to human anatomy and faces of celebrities.
Moreover, certain prompts tend to generate mostly black and white images (bias towards monochrome), and you have to add the prompt “colourful” to generate colored images.
The Ugly
Similar to version 1, hands and text-in-image generations are still a big problem. Also, it is unsure why Stable Diffusion 2 did not use the estimated watermark probability strategy to filter the LAION-5B datasets. Based on my own personal anecdote, the new model has a higher tendency to generate images with watermarks as compared to the old model.
Furthermore, LAION is a quantity over quality datasets. You can easily verify the images and their text labels pairs via the following clip retrieval page. You will realize that most of the images are poorly labelled, which will have big implications on the performance of the model.
Text encoder
Stable Diffusion 2 is based on OpenCLIP-ViT/H as the text-encoder, while the older architecture uses OpenAI’s ViT-L/14. ViT/H is trained on LAION-2B with an accuracy of 78.0. It is one of the best open-source weights provided by OpenCLIP.
Although the weight for ViT-L/14 is open-source, OpenAI did not release the training data. As a result, you will have little control on what is being learned by the model. StabilityAI solves this by leveraging on an open-source implementation OpnCLIP-ViT/H weight, which is trained on the same datasets they used for the latent diffusion model.
The Good
The new model will now understand your prompt better. Moving on forward, StabilityAI and the community can improve the text encoder by training their own OpenCLIP model. As a result, you can guide the model to generate the desired images easily.
In addition, there seems to be less biases on certain domains. For example, version 2 is now capable of generating rooms with non-white ceilings.
The Bad
All existing prompts for version 1 will not work the same for version 2. The input prompt needs to be a little more descriptive. Using the prompt “cat” is different from the prompt “a photo of a cat”.
Besides that, all existing embedding and dreambooths model will not work out-of-the-box. You need to use the corresponding text encoder in your pipeline depending on the based pre-trained model.
Not only that, the new text encoder will not recognize some of the “famous artists” in your prompt. It will only recognize artists that are presents in the LAION-5B datasets.
Note that no artists were deliberated removed from the training datasets.
The Ugly
Since Stable Diffusion is trained on subsets of LAION-5B, there is a high chance that OpenCLIP will train a new text encoder using LAION-5B in the future. Given that the text encoder is a crucial component in the entire stable diffusion architecture, most of the existing works related to prompts will be invalidated when the text encoder changed.
Also, some of the existing implementations will have to provide backward compatibility support for both the old and new versions.
Depth-to-Image Model
The new depth-guided model is one of the most promising features released by StabilityAI. It is based on MiDaS, which infers the depth of an image, and then using both the text and depth information to generate new images.
Here is an example of how it works:
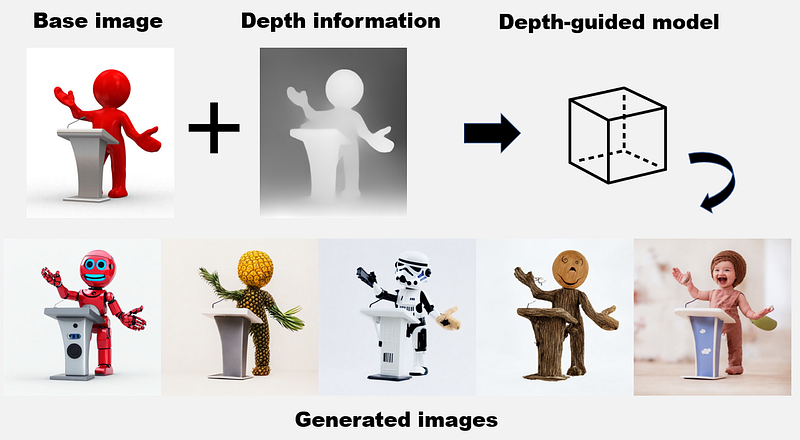
Check out the following space in Hugging to learn more about generating depth information from an image.
The Good
The new depth-guided model offers better results for image to image generation. This opens up new possibilities on features such as generating images with layers or even text to 3D models.
The Bad and The Ugly
At the time of this writing, you can only use the depth-guided model with the stablediffusion repository, making it difficult to test the model as most users experienced difficulties in setting up and running the provided scripts. The diffusers version 0.9.0 only supports the other four models:
From version 0.10.0 onward, you can now run the model with diffusers:
import torch
import requests
from PIL import Image
from diffusers import StableDiffusionDepth2ImgPipeline
pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-depth",
torch_dtype=torch.float16,
).to("cuda")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
init_image = Image.open(requests.get(url, stream=True).raw)
prompt = "two tigers"
n_propmt = "bad, deformed, ugly, bad anotomy"
image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]Conclusion
StabilityAI states that the new model only serves as a base model for further improvement by the community. In the future, they will do a regular releases so that anyone can further improve upon it by fine-tuning it with their own datasets. They will also offer methods to do public distributed training (experimental test that is not guaranteed to work).
All in all, the released of Stable Diffusion 2 marks a step forward in research and problem with legal issues. However, it is also a step back for some of the adopters in the community that prefer unrestricted creations or general improvement from the previous version.
Thanks for reading this piece. Have a great day ahead!






{kind=link}