
Spark Streaming Part -1 || Python

What’s the point of waking up after your house gets broken in? Don’t you think it’s useless to alert yourself after the catastrophe has already hit you badly? We need to be aware of these things in real-time. Right???
We have a very good Hindi phrase
“अब पछताये होत क्या जब चिड़ियाँ चुग गई खेत”
This means:- When birds have spoiled the field they have eaten the seeds, and nothing remains there,
Why feel sad now.
The moral is “Do everything in time.”
Do not act when it’s too late. You will feel sorry then.
To resolve these issues we have “SPARK STREAMING” to get you going.
What are we going to cover in this article?
- What is Data streaming?
- Importance of steaming data
- Challenges in Data Streaming Applications
- What is spark streaming?
- Real-time data streaming using Socket || Python
Let’s roll !! (🌟)
What is data Streaming?
The word “Streaming” is used to describe a continuous, never-ending data stream with no start and end point,
Data Streaming is the process of transmitting a continuous flow of data known as a stream,
A data stream consists of a series of data ordered in time. As an example data streams include sensor data, transactions logs, IOT data, web browser logs, and many more.
We can think of data streaming as a conveyor belt carrying data and storing it in a database which can later be used to detect fraud in real-time, monitor health, send alerts and visualize data in real-time which can be very helpful.
Importance of Streaming data:
Today’s data is generated by an infinite amount of sources, they can be IOT data sensors, weblogs, gaming applications, security logs, servers, and all, and it is nearly impossible to control, and regulate data.
So the application that is working with data streams have required some functions: Storage and data processing,
Storage must be able to handle large amounts of data coming in real-time
Data Processing must be able to process and send accordingly the requirement
Real-world examples of real-time data streaming

- Fraud Detection
- Real-time multiplayer gaming
- IoT sensor data
- Customer activity
- Hate speech detection in real-time (social media)
- Social media feeds
- AL/ML prediction in real-time
And so on the list goes on…
Challenges in Data Streaming Applications
- Scalability:- We need a system that can store and scale according to needs as we have data coming in a large amount.
- Fault Tolerance and Data Guarantees:- With data coming from various sources, locations, and formats and at different speeds, To process and store all these data our system has to be fault-tolerant and made sure that whatever data is sent by the user is also received by our streaming pipeline, which made sure Data Guarantees.
- Ordering:- As our data is coming at a different speed we need to make sure that data in is order otherwise it wouldn’t make any sense, and our streaming processing pipeline must be aware of data transaction properties.
To maintain all of these properties we’re going to use well knows “Apache Spark”, and we’re handing data coming in real-time using Sockets.
What is Spark Streaming:-

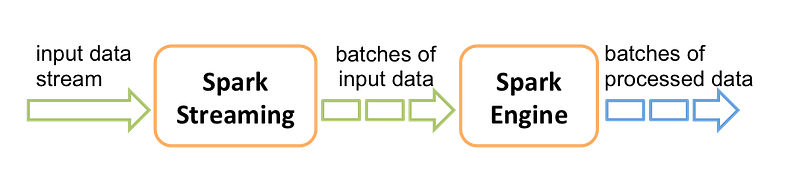
Spark Streaming is the highly fast engine to precess high columns of data and it is 100 times faster than Google’s MapReduce, the reason is that it uses distributed data processing which makes small chunks of data and computes in parallel across the servers.
Spark Streaming uses Spark Core’s fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD transformations on those mini-batches of data. This design enables the same set of application code written for batch analytics to be used in streaming analytics, thus facilitating the easy implementation of lambda architecture.
However, this convenience comes with the penalty of latency equal to the mini-batch duration. Other streaming data engines that process event by event rather than in mini-batches include Storm and the streaming component of Flink. Spark Streaming has support built-in to consume from Kafka, Flume, Twitter, ZeroMQ, Kinesis, and TCP/IP sockets. [wiki]
Spark Streaming is one of the most crucial parts of Big Data. Which ingest data from different sources in real-time and process it and applies Al/ML models on it and other functions to store it in a database or make real-time action.
Real-time data streaming using Socket || Python
Step 1:- Create Spark Session:
Spark session is an entry point of a spark application, in which we can define our spark app name which should be unique because spark identifies the running cluster based on the app name. To create a spark session
# creating spark sessionspark = SparkSession.builder.appName(“SocketExample”).master(‘local[*]’).getOrCreate()Step 2:- Create a function for reading data from sockets:-
- Need to create stream_df which contains data coming from sockets in some port and hostname
# loading/reading data from socketstream_df = spark.readStream.format(‘socket’).option(“host”,host).option(“port”,port).load()Step 3:- Check if data is streaming, and print the schema
# check if still streamingprint(stream_df.isStreaming)
stream_df.printSchema()Step 4:- Write received data into the console (we can save that data too, we’ll see that in upcoming articles)
# write stream in consolewrite_query = stream_df.writeStream.format(‘console’).start()Step 5: Wait for the socket to close
write_query.awaitTermination()That’s it now let’s see the complete code
Complete code:-
After that open 2 terminals and in one terminal start the server by using “netcat -lk 1100” and in the other server runs “socket_streaming.py” and WALLA!!
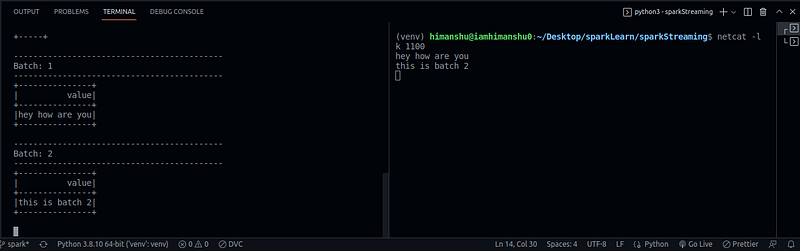
As you can see we’re able to send data and able to get the data in real-time in batches.
So in the next articles, we’re going to learn about, How we use triggers to perform some action and how we can perform data transformation in real-time, and more, So stay tuned for that…
That’s it for now see you in the next article.
I’ve provided the image links for those images which are not mine.
let’s get connected on Linkedin, Twitter, Instagram, Github, and Facebook.
Thanks for reading!





{kind=link}
{kind=link}