
Spark ETL Chapter 6 with APIs
Previous blog/Context:
In an earlier blog, we discussed Spark ETL with HIVE. Please find below blog post for more details
Introduction:
In this blog, we will do Spark ETL with APIs. We will source data from API and load data into one of the below destinations. We will learn how to call APIs from Spark and create a data frame from the API response. Once we have data in the data frame, we will transform and then load data into JSON and CSV format.
Today, we will perform below Spark ETL operations
- Call API and load data into the data frame
- Create a temp table or view and analyze data
- Filter data and store it in CSV format on the file server
- Filter data and store it in JSON format
First, clone below GitHub repo, where we have all the required sample files and solution
If you don’t have a setup for Spark instance follow the earlier blog for setting up Data Engineering tools in your system. (Data Engineering suite will setup Spark, MySQL, PostgreSQL, and MongoDB in your system) In that Spark instance, we already have packages installed for Azure blog storage and Azure Data Lake Services.
We will use a publicly available API, for this demo we will be using the API below.
https://api.publicapis.org/entries
If you call this API from Postman/Browser, you will see the response below

Call API and load data into the data frame
First, we will start the spark application and session. And after that, we will call API.
# First Load all the required library and also Start Spark Session
# Load all the required library
from pyspark.sql import SparkSession
#Start Spark Session
spark = SparkSession.builder.appName("chapter6").getOrCreate()
sqlContext = SparkSession(spark)
#Dont Show warning only error
spark.sparkContext.setLogLevel("ERROR")
We will use the python package “request” to call API. Once we get a response from API, using the “JSON” package, we will convert a response into JSON format.
#import package for calling API and formating JSON
import requests
import jsonurl = "https://api.publicapis.org/entries"
response = requests.request("GET", url)# print(response.text)
jsontext = json.loads(response.text)
print(jsontext["count"])
As per the JSON response, we see that all the content is in the entries node. So, we will get the entries node into one variable. And from that list variable, we will create a spark data frame.
jsonentries = jsontext["entries"]
#Create dataframe
listdf = spark.createDataFrame(data=jsonentries)
Once the spark data frame is created, we will check the schema of the data frame and we will also check sample data into the data frame.
#print Schema of dataframe
listdf.printSchema()
#list first 20 open APIs
listdf.show()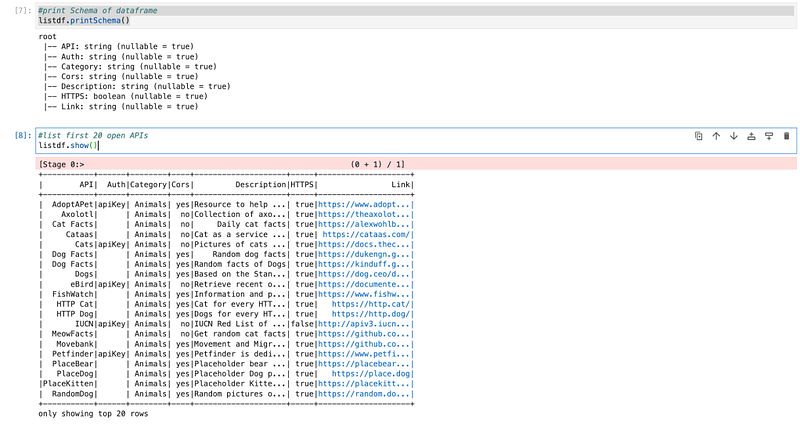
Create a temp table or view and analyze data
As we discussed in an earlier blog on the HIVE table/view. We will create a HIVE temp view from this data frame so that we can write Spark SQL and can do all the required transformations.
# Creating Temp Table or HIVE table
listdf.createOrReplaceTempView("tmpOpenAPI")
We will write a query for getting distinct categories.
sqlContext.sql("SELECT DISTINCT(Category) FROM tmpOpenAPI").show()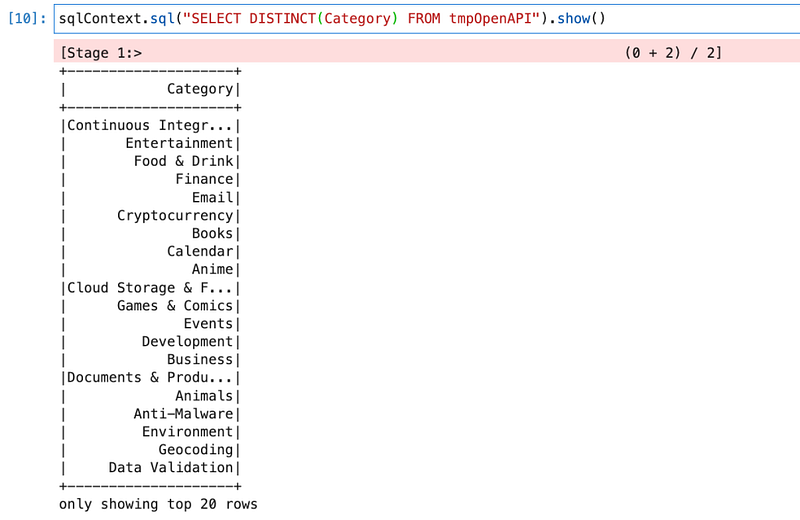
Filter data and store in CSV (& Json) format on the file server
We will filter data with the category “Email” and store data in CSV and JSON format on the file server.
The query for filtering data
emaildf = sqlContext.sql("SELECT * FROM tmpOpenAPI WHERE Category = 'Email'")
Write data into CSV format
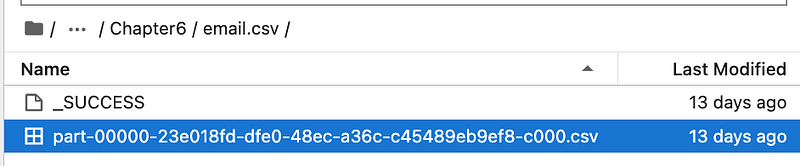
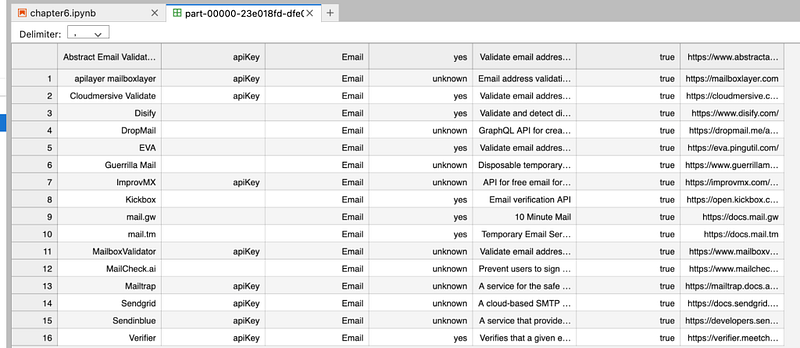
emaildf.write.format("csv").save('email.csv')
It will create a folder named “email.csv” and creates a CSV file inside it.
Write data into JSON format.
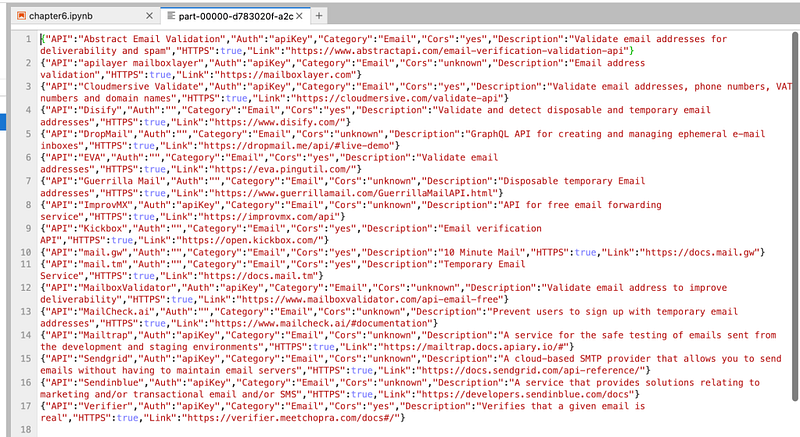
emaildf.write.format("JSON").save('emailJSON')It will create a folder with the name “emailJSON” and will store data in JSON format.

Conclusion:
Here, we learned
- How to read APIs in Spark and create a spark data frame
- How to write data into JSON format into file server (source can be anything, here we had API as source)
- How to write data into CSV format into file server (source can be anything, here we had API as source)