
Spark ETL Chapter 0 with files (CSV | JSON | Parquet | ORC)
Previous blog/Context:
Please see the previous blog, where we have designed a plan for Spark ETL pipelines. In the coming days we will be doing spark ETL using all of the data sources mentioned. Please find the blog for more details.
Introduction:
In this blog, we will be discussing Spark ETL with files. We will be considering CSV, JSON and Parquet files. These are the most commonly used files.
Most of the people heard about CSV and JOSN files but not Parquet files. Parquet files are files which store data in column stores and that’s why it uses less space and is very efficient while reading from parquet files.
Today, we will be doing the task below in Spark.
- Read CSV file and write into dataframe
- Read JSON file and write into dataframe
- Read Parquet file and write into dataframe
- Read text file and write into dataframe
- Create temp table for all
- Create JSON file from CSV dataframe
- Create CSV file from Parquet dataframe
- Create parquet file from JSON dataframe
- Create orc file from JSON dataframe
First clone below GitHub repo, where we have all the required sample files and solution.
If you don’t have setup for Spark follow earlier blog for setting up Data Engineering tools in your system.
For all of the above Spark data pipelines, we will be using open (public) data.
Spark ETL with files
First of all, open Jupyter lab and upload all the files from GitHub chapter 0 to there.
Open notebook and start Spark session
Our spark session is started now with application name “chapter0”. Now we can start with all ETL.
Read CSV file and write into dataframe
We have nyc taxi data in CSV format in below format and we want to load that data into dataframe.
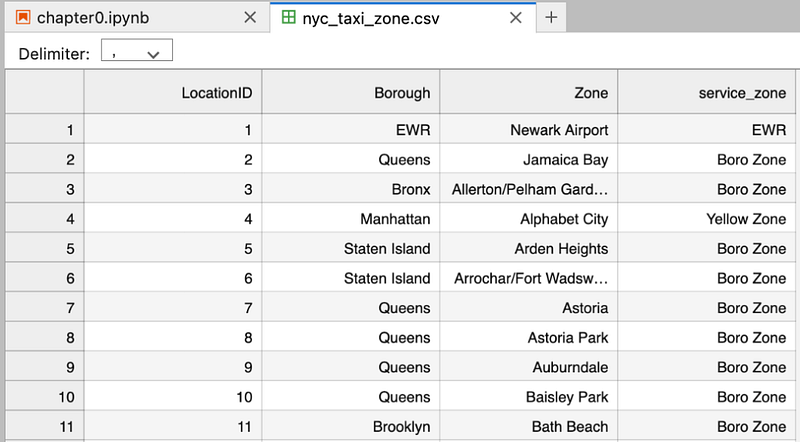
For that, we will use below code
#Load CSV file into DataFrame
csvdf = spark.read.format("csv").option("header","true").option("inferSchema","true").load("nyc_taxi_zone.csv")In format we are specifying that we have CSV file and header is true as we have first row as header in data.
This will load data into dataframe. Once data loaded into dataframe. We can print schema and can also check data loaded or not.
#Checking dataframe schema
csvdf.printSchema()csvdf.show(n=10)Read JSON file and write into dataframe
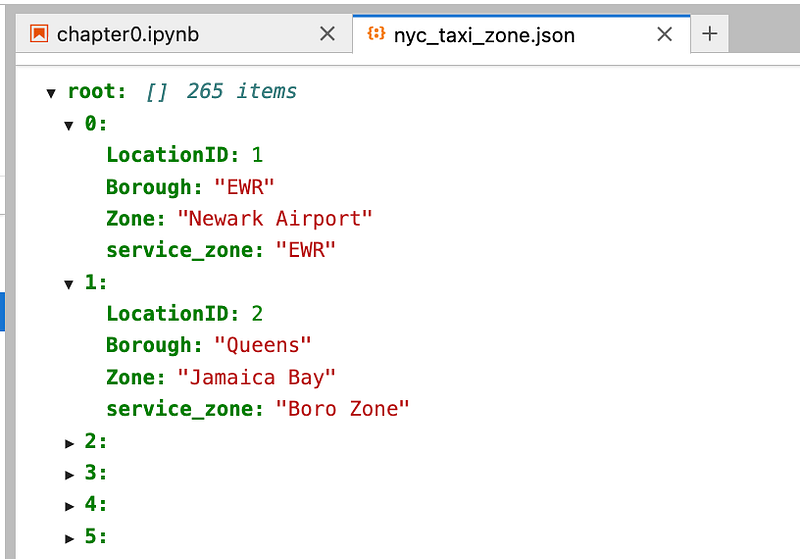
We have the same nyc taxi data in JSON format and now we want to load data into dataframe.
We will use same code as we used for CSV but this time we will specify JSON format.
#Load Json file into DataFrame
jsondf = spark.read.format("json").option("multiline","true").load("nyc_taxi_zone.json")Here, it is important that we specify multiline true otherwise it will not understand JSON data. (As this is multiline json. when it is not multiline json it is not need to specify this one)
We will print schema and also check data.
jsondf.printSchema()
jsondf.show(n=10)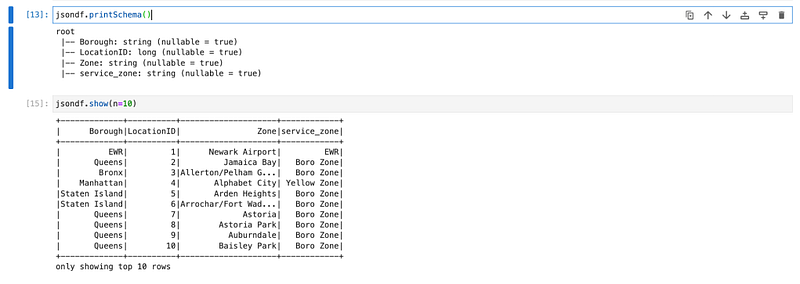
Read Parquet file and write into dataframe
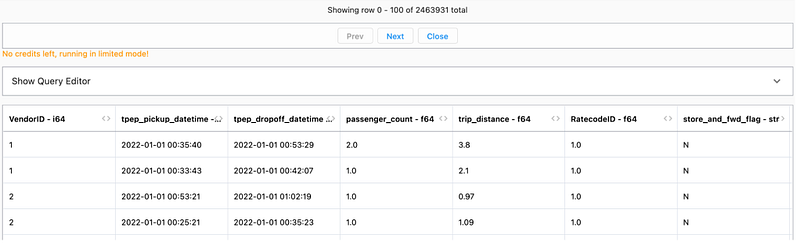
Please take sample file from below location and out on same folder. (File size is more than 25 MB so could not able to put on GitHub) ->
https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-01.parquet
Use any of the parquet viewer to have look on file
We will use the same code for reading data from parquet file by specifying format as parquet.
parquetdf = spark.read.format("parquet").load("yellow_tripdata_2022-01.parquet")This file size is more than 25 MB and has 2.4 M rows but it is loaded in dataframe very fast. The reason behind that is parquet store data into column store format.
We will check schema and print row count.
parquetdf.printSchema()
parquetdf.count()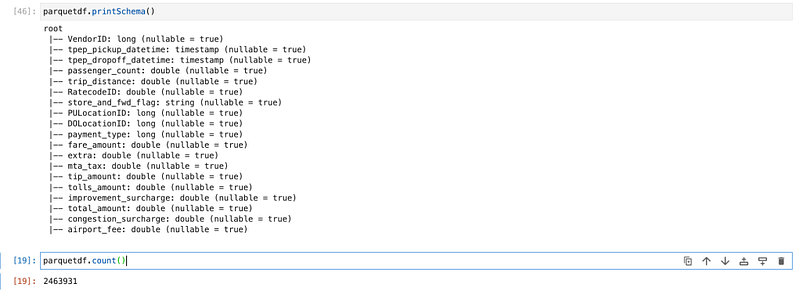
Read text file and write into dataframe
We have one sample text file and now loading text file into dataframe as below.
Code for the same
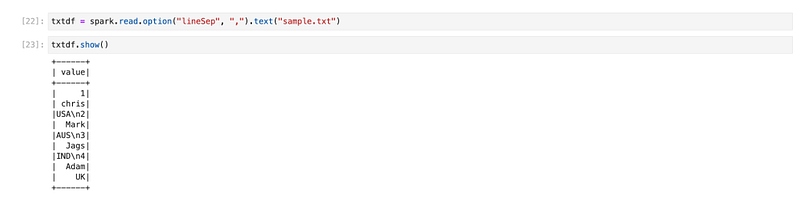
txtdf = spark.read.text("sample.txt")
we can specify what a line separator is. for example, if we say line separator is ‘,’
Create temp table for all
We have all the data into dataframe. Now we will create table table/view. So that we can write spark SQL queries.
csvdf.createOrReplaceTempView("tempCSV")
jsondf.createOrReplaceTempView("tempJSON")
parquetdf.createOrReplaceTempView("tempParquet")
txtdf.createOrReplaceTempView("tempTXT")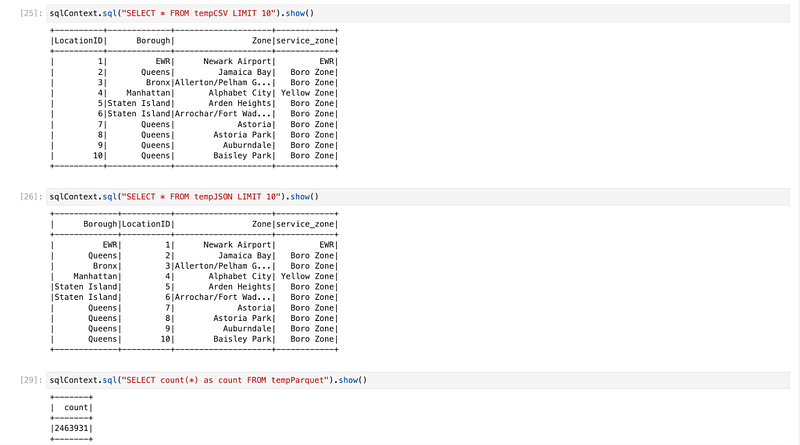
Create JSON file from CSV dataframe
We have data in CSV which we want to convert into JSON format. Data is already loaded in dataframe so we can directly use spark write and specify format as JSON, it will create JSON files.
csvdf.write.format("json").save("jsondata",mode='append')format -> format of file in which we want to write
mode -> There are three modes. append which appends data into existing location (folder). overwrite which overwrite existing file with new file. And ignore which will ignore if there is file on that location.
We have specified destination as “jsondata”, so it created folder with that name and put files in JSON format

Create CSV file from Parquet dataframe
Same way we will use below code for creating CSV files from parquet source.
parquetdf.write.format("csv").option("header","true").save("csvdata",mode='append')
Create parquet file from JSON dataframe
We will use the same code for creating parquet file from JSON source.
jsondf.write.format("parquet").option("compression","snappy").save("parquetdata",mode='append')We can also compress parquet files. If you see in our code, we have passed compression type snappy which will compress file.
Create orc file from JSON dataframe
Same way to create orc files from JSON source, we will use below code.
jsondf.write.format("orc").save("orcdata",mode='append')
Conclusion:
spark. Read -> Using file read we can read file by specifying file format. (CSV, JSON, text, parquet, orc or avro)
spark. Write -> Using this we can write to file by specifying file format in which we need data. (Format -> CSV, JSON, text, parquet, orc or avro)