
Spark Cluster Üzerine Java-Spark Projesi’nin Submit Edilmesi
Bu yazımda İngilizce kaynak olarak bile bulamadığım ve Java jar dosyasının oluşturulmasından, spark ile de Hadoop Yarn’a/opsiyonlara nasıl submit edileceğinden bahsedeceğim.
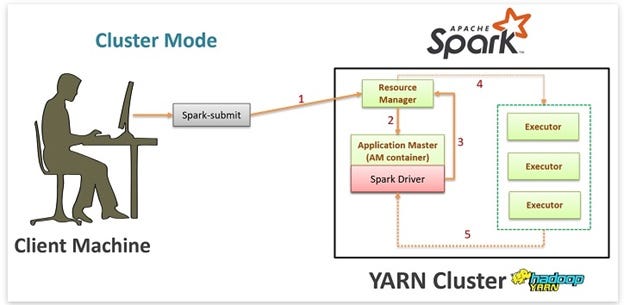
GİRİŞ:
Öncelikle submit işlemlerine geçmeden önce niçin buna ihtiyaç var buna değinelim. Eğer projemizde performans istiyorsak çalışma dosyamızı Hadoop Yarn’a gönderebiliriz ve projemiz local’den ziyade Cluster’ımız üzerinde çalıştırabiliriz. Yani Cluster içinde bizim node’larımız vardır bu nodelarda da worker’lar yer almaktadır. Bu workerlardan instance/ObjectRef oluşturabiliriz ve böylece uzak bir makineye atıfta bulunabileceğimiz benzersiz bir uique id bize sunar.
Kısaca projemizi Cluster üzerinde worker’lara bölerek çalıştırıyoruz. Projemizi çalıştırma bu workerlar üzerinde gerçekleşiyor ve local’de çalıştırmaya göre daha iyi bir performans artışı olmaktadır.
Spark Submit ile Uygulamayı Gönderme
Hadoop Yarn’a dosya submit etmeden önce jar dosyamızı oluşturmalıyız ancak bundan önce de submit ederken hata almamak için bazı dikkat etmemiz gereken noktalar var.
Scala — Spark Versiyon Uyumunun Dikkat Edilmesi:
Burada dikkat edilecek en önemli husus , kullanılan kütüphane versiyonunlarının clusterınızın destekliyor olmasıdır. Zira jar dosyanızı oluştururken her şey yolunda gibi görünebilir ancak submit ederken hata ile karşılaşabilirsiniz. Bunu önlemek için ise projenizde kullanmış olduğunuz kütüphanelerin spark versiyonu ile spark cluster’ınızın scala versiyonu uyumlu olmalıdır.
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.8</version>
</dependency>Şimdi ise örnek bir Data okuma projesi oluşturalım.
package spark.jarsubmit;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class App
{
public static void main( String[] args )
{ //Create session instance from SparkSession
SparkSession spark = SparkSession
.builder()
.master("local[*]")
.appName("Java Spark SQL basic example")
.getOrCreate();
//read data
Dataset<Row> read_data = spark.read().format("text").load("hdfs://id:port/dataset") //split data and set colon names
read_data = read_data.selectExpr("split(value,'::')[0] as id", "split(value,'::')[1] as name","split(value,'::')[2] as type"); //show 10 lines data
read_data.show(10 ,false);
}
}Daha sonra bu projemizi jar dosyası haline getirelim:
Son olarak ise oluşturmuş olduğumuz jar dosyasını terminalden submit ediyoruz. Burada master local olarak belirtirsek local’e submit edecektir. Ancak biz yarn’a submit edeceğiz ve bunun için --master yarn olarak belirtmeliyiz.
spark-submit --class spark.packetname.App --master yarn jarName.jarDosyanızı Spark ile submit etmek için diğer opsiyonlar şunlardır:
# Run application locally on 8 cores
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[8] \
/path/to/examples.jar \
100
# Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a Spark standalone cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a YARN cluster
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \ # can be client for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
# Run a Python application on a Spark standalone cluster
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
# Run on a Mesos cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master mesos://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
http://path/to/examples.jar \
1000
# Run on a Kubernetes cluster in cluster deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master k8s://xx.yy.zz.ww:443 \
--deploy-mode cluster \
--executor-memory 20G \
--num-executors 50 \
http://path/to/examples.jar \
1000Daha fazlası için: http://spark.apache.org/docs/latest/submitting-applications.html#launching-applications-with-spark-submit
SONUÇ:
Local’de çok uzun süren uygulamalarımız workerlar üzerinde çalıştırarak çok kısa sürede gerçekleşecektir. Böylece uygulamalarınızda gözle görülür bir performans artışı olacaktır.
Bir problem olması durumunda benimle bağlantı kurmaktan veya daha iyi bir çözümünüz var ise benimle paylaşmaktan çekinmeyin. 😉





