
Some Notes on DBSCAN Algorithm
In this post, I would like to discuss some of the insights on DBSCAN algorithm. Usually, when I look at an algorithm I try to see what each line of pseudocode does and why?

line 12: is q core or base point?
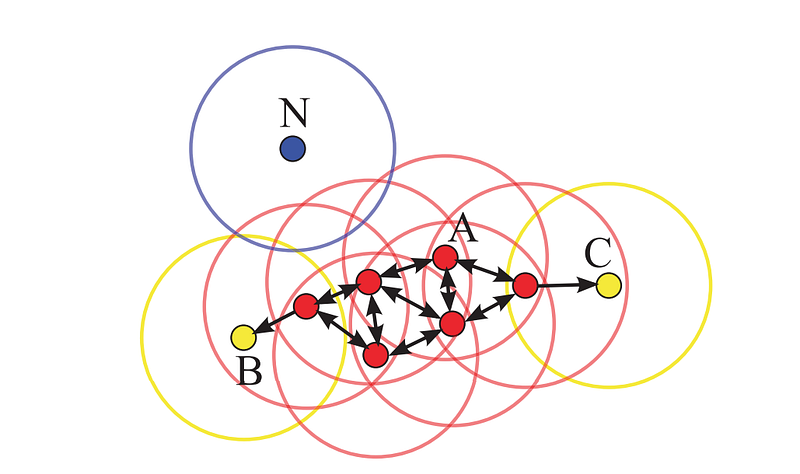
At any point, a point would have one of three types of labels: undefined, Noise, or a cluster label. I was wondering if q’s label is not undefined then it would be a cluster label. If it’s part of a cluster then either it is a core point or border point and it is already processed.
If it is a core point and as its already processed (a RangeQuery is already executed), p would have been part of the Neighbors returned from that. At that point, we can conclude that since p would have been already processed if q was a core point, q is not a core point.
If it is a border point and again as it is already processed, p would be returned as Neighbors of the same but not processed. That is because the number of neighbors returned would be less than minPts.
Definitely line 12 is needed as otherwise we would process q even though its already processed. Though this is a good example that a border point could be part of multiple clusters but depends upon the sequence of execution. This proves that DBSCAN is not deterministic, which is one of the disadvantages of the algorithm.
Sequence of Execution
Let us walk through an example demonstrating the non-deterministic nature of the DBSCAN algorithm. Let us say we have following data and parameters:
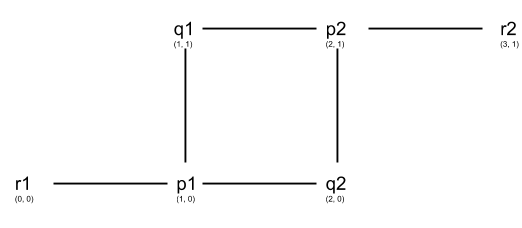
DB = [p1, q1, r1, p2, q2, r2]minPts = 3ε = 1dist = Euclidean It could be easily seen that p1, p2 are core points as there are 3 points, (r1, q1, q2) and (r2, q1, q2) respectively, are within ε distance from them. r1,r2, q1, q2 are border points as they don’t have 3 or more points within ε distance.
Now the key is the order of data. In current order, when the algorithm executes p1 would be picked first and since its core point, q1 and q2 will be assigned to the same cluster as p1. If the data order was such that p2 appeared first then q1 and q2 will be assigned to the same cluster as p2. Hence the nature of DBSCAN as not deterministic.
Now let us change the order a little to understand the algorithm in more detail.
DB = [q1, r1, q2, r2, p1, p2]In this scenario till r2, RangeQuery will return neighbors less than minPts. So all points q1, r1, q2, r2 will be labeled as noise as per line 5. When p1’s turn comes for execution, RangeQuery will return N = {r1, q1, q2}. Since the length of N is equal to minPts, a new cluster label would be created and assigned to p1. Their label would be set to the same cluster as p1 in line 11. So even though originally those points are marked as noise as we find any core point closer to them, their label is changed.
Finally, if we add one more point m1 = (3, 0), q2 will become a core point as well. And in that case, all the points will be part of the same cluster with p1, q2, p2 as core points, and the rest as base points. The beauty of the algorithm is such that even though point r1 and r2 are very far apart, they are part of the same cluster due to linkage with core points.




