
Natural Language Processing
Similar Texts Search In Python With A Few Lines Of Code: An NLP Project
Find similar Wikipedia profiles using count-vectorizer and nearest-neighbor method in Python, a simple and useful Natural Language Processing (NLP) project

What is Natural Language Processing?
Natural Language Processing (NLP) refers to developing an application that understands human languages. There are so many use cases for NLPs nowadays. Because people are generating thousands of gigabytes of text data every day through blogs, social media comments, product reviews, news archives, official reports, and many more. Search Engines are the biggest example of NLPs. I don’t think you will find very many people around you who never used search engines.
Project Overview
In my experience, the best way to learn is by doing a project. In this article, I will explain NLP with a real project. The dataset I will use is called ‘people_wiki.csv’. I found this dataset in Kaggle. Feel free to download the dataset from here:
The dataset contains the name of some famous people, their Wikipedia URL, and the text of their Wikipedia page. So, the dataset is very big. The goal of this project is, to find people of related backgrounds. In the end, if you provide the algorithm a name of a famous person, it will return the name of a predefined number of people who have a similar background according to the Wikipedia information. Does this sound a bit like a search engine?
Step By Step Implementation
- Import the necessary packages and the dataset.
import numpy as np
import pandas as pd
from sklearn.neighbors import NearestNeighbors
from sklearn.feature_extraction.text import CountVectorizer
df = pd.read_csv('people_wiki.csv')
df.head()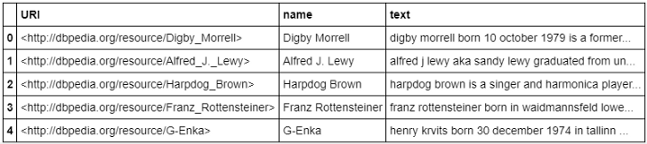
2. Vectorize the ‘text’ column
How to Vectorize?
In Python’s scikit-learn library, there is a function named ‘count vectorizer’. This function provides an index to each word and generates a vector that contains the number of appearances of each word in a piece of text. Here, I will demonstrate it with a small text for your understanding. Suppose, this is our text:
text = ["Jen is a good student. Jen plays guiter as well"]Let’s import the function from the scikit_learn library and fit the text in the function.
vectorizer = CountVectorizer()
vectorizer.fit(text)Here, I am printing the vocabulary:
print(vectorizer.vocabulary_)#Output:
{'jen': 4, 'is': 3, 'good': 1, 'student': 6, 'plays': 5, 'guiter': 2, 'as': 0, 'well': 7}Look, each word of the text received a number. Those numbers are the index of that word. It has eight significant words. So, the index is from 0 to 7. Next, we need to transform the text. I will print the transformed vector as an array.
vector = vectorizer.transform(text)
print(vector.toarray())Here is the output: [[1 1 1 1 2 1 1 1]]. ‘Jen’ has index 4 and it appeared twice. So in this output vector, the 4th indexed element is 2. All the other words appeared only once. So the elements of the vector are ones.
Now, vectorize the ‘text’ column of the dataset, using the same technique.
vect = CountVectorizer()
word_weight = vect.fit_transform(df['text'])In the demonstration, I used ‘fit’ first and then ‘transform’ later’. But conveniently, you can use fit and transform both at once. This word_weight is the vectors of numbers as I explained before. There will be one such vector for each row of text in the ‘text’ column.
3. Fit this ‘word_weight’ from the previous step in the Nearest Neighbors function.
The idea of the nearest neighbor’s function is to calculate the distance of a predefined number of training points from the required point. If it’s not clear, do not worry. Look at the implementation, it will be easier for you.
nn = NearestNeighbors(metric = 'euclidean')
nn.fit(word_weight)4. Find 10 people with similar backgrounds as President Barak Obama.
First, find the index of ‘Barak Obama’ from the dataset.
obama_index = df[df['name'] == 'Barack Obama'].index[0]Calculate the distance and the indices of 10 people who have the closest background as President Obama. In the word weight vector, the index of the text that contains the information about ‘Barak Obama’ should be in the same index as the dataset. we need to pass that index and the number of the person we want. That should return the calculated distance of those persons from ‘Barak Obama’ and the indices of those persons.
distances, indices = nn.kneighbors(word_weight[obama_index], n_neighbors = 10)Organize the result in a DataFrame.
neighbors = pd.DataFrame({'distance': distances.flatten(), 'id': indices.flatten()})
print(neighbors)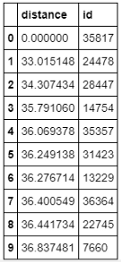
Let’s find the name of the persons from the indexes. There are several ways to find names from the index. I used the merge function. I just merged the ‘neighbors’ DataFrame above with the original DataFrame ‘df’ using the id column as the common column. Sorted values on distance. President Obama should have no distance from himself. So, he came on top.
nearest_info = (df.merge(neighbors, right_on = 'id', left_index = True).sort_values('distance')[['id', 'name', 'distance']])
print(nearest_info)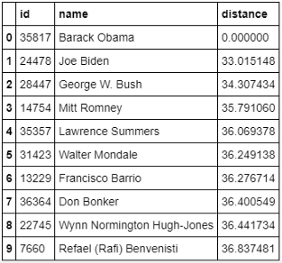
These are the 10 people closest to President Obama according to the information provided in Wikipedia. Results make sense, right?
A similar texts search could be useful in many areas such as searching for similar articles, similar resume, similar profiles as in this project, similar news items, similar songs. I hope you find this small project useful.