
She is not real. Fakes and protocols.
ThisPersonDoesNotExist.com has popped up everywhere over the past week or so. Open it in your browser to generate an infinite number of people who don’t exist, each one generated by generative adversarial network, which is a way of using neural networks for machine learning. But this article isn’t about machine learning, it’s about layers of certainty.

There is something somehow evil about ThisPersonDoesNotExist.com.
The mere suggestion that this person should exist, and that the machines have looked at all of us and found the missing people suggests we, as a race have failed. That the machines are somehow able to look into the many possible worlds and find not just numbers which describe alternative realities, but the people who inhabit them. That these people should exist.
But it’s not evil. It’s just data.
Looking at these non-people, I find myself wondering if they have names and, if they are the average of millions of other people’s faces would their personalities be the average as well? And then: how would you generate a personality?

But it’s just data, even if it looks like a child on a beach is staring at you. And you wonder who their parents are. And whether it was warm that day.
But there are no parents. And there was no day. Because this person doesn’t exist, nor do their parents and nor did the day on which this photo was not taken.
They aren’t real. But writing that phrase — not a real person — is insane because that’s what people have said to justify war and genocide.
But we are just talking about data. This isn’t real.
Feeling real vs being real
This conflict between something feeling real and knowing that it definitely isn’t is one which happens every time a new technology is first misused. It questions what we think of as real and how we find out what is true.
When a new content technology appears it is amazing until someone finds a way to do evil with it and then it is terrifying. The camera never lies, until it did. Videos can’t be fakes, until they can.
ThisPersonDoesNotExist.com is a form of fake content, just like fake news and many others before it. True, it is generated by machines but the underlying problem is the same: what is true?
While we can stare at the faces of these non-people wondering what is true, all of our wondering is because of a trick and distraction of the specific content — their faces — not a phenomenon of the underlying technology.
It’s more interesting to think about how we know what’s real and how these faces, and our emotional reaction to them could teach us something about how to deal with what is not real.
The Postmodern Generator: Fake Essays
Like the ThisPersonDoesNotExist.com, The Postmodern Generator generates essays which are not true or real at all but on first glance look real so we think they might be true. Every time you refresh your browser, the site generates another seemingly real postmodern essay complete with realistic looking authors and headings, neatly organised into sections and footnotes.

Every essay looks as real as the one before it. You skim down the page and it has the look of something human generated.
When I first found this, I was studying at an arts college. Fellow students were working on this kind of essay and there was something unnerving about how easy it was to generate reams of this postmodern junk.
Or… was the stuff they were writing junk?
Which was true? Which was real?
You can argue that the kind of nonsense language that postmodern theorists spout lends itself to generating nonsense essays, but this kind of fake isn’t limited to the arts and philosophy.

Fake Maths
Mathsgen does the equivalent of this in maths — punch in couple of authors and it’ll generate a convincing mathsy-looking essay complete with authors, footnotes and formulae.
For anyone who has knowledge of the subject, these essays are clearly nonsense just like the postmodern generator essays but both are doing same thing as ThisPersonDoesNotExist.com does; create real-ish looking things, but in a tongue-in-cheek way.
None of these experiments suggest that their output is real.
It’s just for fun.
But…
All that it takes to turn this ‘good’ technology into ‘bad’ is to say “This one is real”.
She is real. She exists.

She exists.
If she exists, a sea of information about her must now be true.
She has a family. She’s wearing sunglasses, and I wonder what that says about her and her style? What is she thinking about? Where was the photo taken?
You have no practical way finding the information because you’d have to find the millions of people who look like her. I am your only source on this and all I’ve said is: “She exists. This one is true.”
But I could do the same with the essays, like the picture above of the maths article I wrote with Cavalieri on “Rings over Trivially Co-Huygens, Linearly Countable Primes”. I’m really proud of that essay.
As soon as I say it exists, it might be a fake and that creates a world of problems, as we know from the pain and confusion fake news is causing us. If there’s no way of verifying some data, you have to add in a heap of manual checks and you have to teach the humans how to behave.
This elicits emotional reactions and philosophical discussion but it turns out that the solution could be purely technical. Technology introduced this weirdness, and technology will make it disappear just as it has before.
The real fake war
As soon as a machine can generate fake news it makes sense for someone else to create a machine to spot the fakes. This is similar to the cybersecurity war which has been running since shortly after the dawn of the internet.
When the internet was first created, it was largely academic and unsecured to the extent that users were told to make their passwords dictionary words to make them easy to remember (which you can read about in The Cuckoo’s Egg). This allowed early hackers to brute force hack the user accounts of academic networks even if the passwords were encrypted.
Since then, security experts have added encryption, 2 factor authentication and other layers of security. Attackers escalated similarly, moving from malware to spam email, spam ads and more.
This can feel overwhelming, with the whole “fake news” noise making it easy to disengage from all news and information or to sit in your own little echo chamber believing the things that you can be very sure of and ignoring everything else. Like all new phases of information technology, the first wave puts the onus on the humans to understand what is real and what’s not.
Verifying the “rightness” of data is a variation of verifying the “rightness” that a given user can access a system which means the war on fakes can be seen as another phase in the cyber war, except that MO has changed: rather than the attackers trying to get access to systems they are using information to make us question our judgement about what is real.
While it’s feels like a very emotionally charged problem, with people being tricked into thinking lies are true, this is just a problem of certification and verification. We have been here before and we have precedence for solving this.
This is why certificates, passports and other official documents have become ever more elaborate and fiddly: so that they can be verified and they are hard to be forged.
Dating back to the middle ages, wax seals would effectively verify the sender adding a small piece of technology, the wax seal to the content, the letter. The content stays the same but the added protocol of sealing it with a pattern in wax increases the trustworthiness.
Proof of sender, proof of fact
If we look at the fake news or, more broadly, the fake content phenomenon in the light of a little bit of technology history we can see that we’re facing another “proof of sender” or “proof of fact” problem. Recipients (readers) need a way of verifying that the information is correct and since the information comes from a system (sender), we need a way of stamping that information at source.
This might sound very complex and you could ask how the hell we’d get the world coordinated to do this, but we already have done it. Several times.
If you’re old enough, you’ll remember the hell of file codecs. If you aren’t old enough, the gist is: there was a time when computers didn’t understand most file formats and so you would have to install a codecs (which is short for “coder-decoder”, that is: it’s a way of encoding and decoding a some kind of data).
You had to do this for videos, images, audio and other “special” types of data. There was no guarantee that a given file could be read by all computers.
Fast forward a couple of decades and we have file types for images, archives, audio, video and it’s pretty easy to grab most types of data and read them on most machines.
Machines were built for consuming the information that they were built for, but not for information their creators hadn’t thought of. After the machine was put into the world with many other types of machines, people had to find ways to make the information flow so they machines could work together.
Fake content is a similar problem: the machines are now in a world where other machines can generate content, but the machines and the systems — our phones, the web, Facebook, twitter — were created before this generated content.
And so, our protocols (that is, the web, Facebook and the other ways of sharing information) need a new layer added on: “proof of sender”. Like the wax seal of the middle ages or the intricate printing of passports, this will build on the existing information infrastructure.
The Proof of Sender layer — how we solve it now
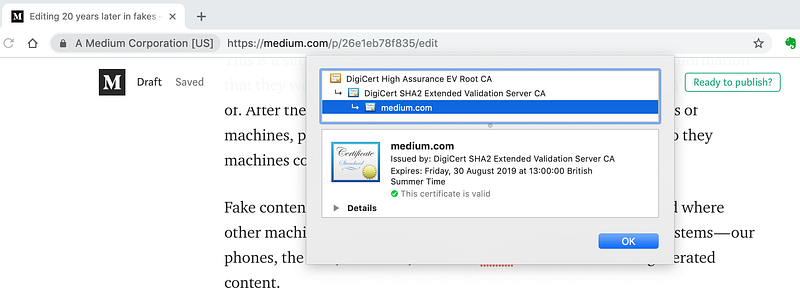
SSL was invented to make using websites more secure.
It does two important and separate things: it encrypts the information being sent from the sender to the recipient so that the “man in the middle” can’t find out what the web page says. It enables the little padlock in chrome which, if you click it and then “certificate” you’ll see who the host is.
This is built into the HTTPS protocol which means the servers for the website are passing this information to your browser and then your browser is using it to check that the content comes from those servers before it shows you.
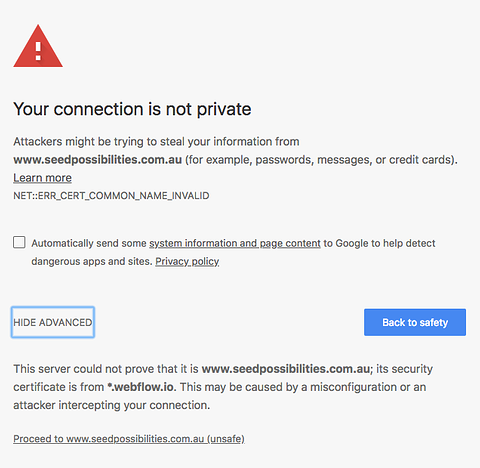
When things don’t look right, your browser gets all worried at you. All that’s happening here is the underlying protocol (remember, that’s just a fancy word for how we move information around) is passing extra information to verify where the content has come from.
The problem of the man in the middle attack is no longer a thing for you to think about. It‘s solved in the protocol.
Proof of sender — how we might solve it for content
How can we provide the same verification for individual pieces of content, like the photos at the top of this article?
We can use a few concepts from the examples we’ve been looking at:
- If a piece of content (i.e. lump of data) is true, it must have a creator. In the digital world, that will be a machine somewhere.
- Content creators need to sign their work digitally, in the same way that SSL ensures websites are signed by the server before being read by your web browser. They would have to sign all kinds of file format: text, image, audio, video or whatever.
- This gets baked into the content format (like the codecs we talked about earlier) or shared somewhere, such as on a blockchain (which for the end user will just be “the internet”; it doesn’t matter whether it’s blockchain or not).
- Content readers (browsers, email clients, etc) would slowly adopt this allowing users to see that the piece of content has an author.
This will get built into all large content creation platforms such as YouTube, which is already starting to ensure that you own the content you share, Facebook, twitter but also Microsoft Word, Powerpoint, Excel, PhotoShop and more. Just like the “Author” field which you can fill with your name when creating documents, there will be an automatically filled field in the file to make it verifiable.
Once the data has proof of sender embedded in it, all content clients (like your browser) will have the verification added just like they do with HTTPS these days.
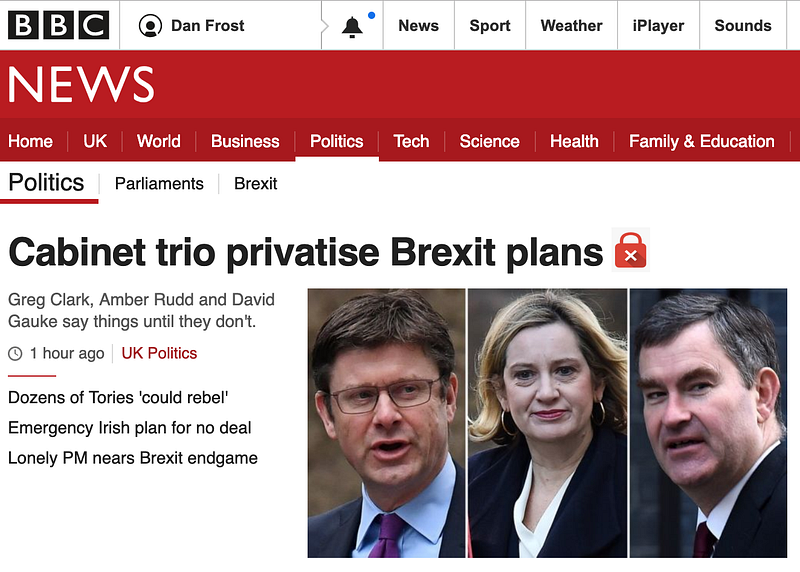
As you browse around the web or through apps, any content which has an untrusted source can be marked as “dodgy” (or a more legally meaningful word).
Like this article (which obviously, I’ve Photoshopped).
Once the content protocol has verifiability in it, the “fake news” problem becomes much less of a concern because the human at the end of it will see an icon and in under a second know to ignore or question the information.
But who do you trust?
This idea solves where something came from but not whether you trust that source. That is a whole other problem…
Dan Frost | TheLeanCTO.com to startups and the ambitious; Tech lead in R&D in edtech at Cambridge Assessment; enthusiast of ideas, podcaster, writer at thebaseline.co.
Follow me on twitter — https://twitter.com/danfrost. Or say hello in the comments.





