
SHAP for Machine Learning: A Step-by-Step Python Tutorial
Learn how to interpret machine learning models using SHAP values with hands-on Python examples and step-by-step explanations.

Machine learning models are revolutionizing everything from medical diagnoses to financial predictions. They’re incredibly powerful, often achieving superhuman accuracy. But there’s a catch: many of these models are complex, opaque “black boxes.” We feed them data, they spit out a result, but we often have no idea how they arrived at that conclusion. This lack of transparency can be a real problem, especially when these models are making decisions that impact our lives.
Imagine applying for a mortgage and being denied. You ask the bank why, and they tell you it was the algorithm. No further explanation. Frustrating, right? You deserve to understand the factors that led to the denial. This is precisely why model interpretability is so crucial. We need to open up these black boxes and understand what’s going on inside.
Enter SHAP values. Think of them as a decoder for machine learning models. They help us understand the influence of each input feature on the model’s prediction. Let’s stick with the mortgage example. SHAP values could reveal how much your income, credit score, loan amount, and other factors contributed to the bank’s decision. They show which features were most important and whether they pushed the decision towards approval or denial.
In this tutorial, we will learn about SHAP values and their role in machine learning model interpretation. We will also use the Shap Python package to create and analyze different plots for interpreting models.
How SHAP Values Work (Simplified)
The math behind SHAP values is a bit complex (it involves game theory!), but the core idea is pretty intuitive. SHAP values assign an “importance” score to each feature for a specific prediction. This score reflects how much that feature contributed to the difference between the actual prediction and the average prediction for all data points.
What are SHAP Values?
SHAP (SHapley Additive exPlanations) values provide a reliable way to interpret machine learning models by showing how each feature contributes to a prediction.
Rooted in game theory, SHAP values assign an influence score to each feature. A positive SHAP value indicates that a feature increases the prediction, while a negative value means it pushes the prediction lower. The larger the value — positive or negative — the stronger the feature’s impact.
One of the biggest advantages of SHAP values is that they are model-agnostic. This means they can be applied to any type of machine learning model, such as:
- Linear regression
- Decision trees
- Random forests
- Gradient boosting models
- Neural networks
Why are SHAP values so useful?
- Explainability: They provide a clear and concise explanation of a model’s prediction, making it easier to understand why a particular outcome occurred.
- Feature Importance: They identify the most influential features, giving you insights into which variables are driving the model’s decisions.
- Model Debugging: They can help you identify potential problems with your model, such as unexpected relationships between features or biases in the data.
- Trust: By understanding how a model works, we can build trust in its predictions.
Getting Hands-on with the Shap Python Package
Let’s see SHAP values in action using the Shap Python package. First, you’ll need to install it:
pip install shap
Now, let’s load some data and train a simple model (we’ll use a basic example for demonstration purposes):
Load the data machine failure dataset, which you can download from Kaggle. The dataset looks clean, and the target column is machine failure. Before training a model, it’s essential to explore the data, handle any missing values, and perform feature engineering to improve predictive performance.
import shap
import numpy as np
import pandas as pd
df = pd.read_csv("./dataset/machine failure.csv")
column_selected = ['Air temperature [K]', 'Process temperature [K]', 'Rotational speed [rpm]',
'Torque [Nm]', 'Tool wear [min]', 'TWF', 'HDF', 'PWF', 'OSF', 'RNF', 'Machine failure']
df = df[column_selected]
df.head()
# Convert data types to float
df = df.astype(float)
Plot Correlation Matrix
import matplotlib.pyplot as plt
import seaborn as sns
corr_matrix = df.corr()
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', linewidths=0.5)
plt.title("Corelation Matrix")
Model Training and Evaluation
- Create X and y using a target column and split the dataset into train and test.
- Train Random XGBClassifier on the training set.
- Make predictions using a testing set.
from xgboost import XGBClassifier
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score, f1_score
from sklearn.model_selection import train_test_split
X = df[['air_temperature__k_', 'process_temperature__k_',
'rotational_speed__rpm_', 'torque__nm_', 'tool_wear__min_', 'twf',
'hdf', 'pwf', 'osf']]
y = df['machine_failure'] # Dependent variable
# Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train an XGBoost model
model = XGBClassifier(n_estimators=100, random_state=42, use_label_encoder=False, eval_metric='logloss')
model.fit(X_train, y_train)
# Predictions
y_pred = model.predict(X_test)
# Evaluate model
accuracy = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.4f}')
print(f'F1-score: {f1:.4f}')The model has shown better performance. Overall, it is an acceptable result with 99.51%

Setting up SHAP Explainer
Now comes the model explainer part.
We will first create an explainer object by providing a XGBClassifier classification model, then calculate SHAP value using a testing set.
explainer = shap.Explainer(clf)
shap_values = explainer.shap_values(X_test)Summary Plot
Display the summary_plot using SHAP values and testing set.
The summary plot shows the feature importance of each feature in the model. The results show that torque_nn, rotation_speed_rpm and tool_wear_min play major roles in determining the results.


SHAP Force Plot
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values.values[0], X_test.iloc[0])
The model predicts a significantly lower value than the base.
shap.force_plot(explainer.expected_value, shap_values.values[:10], X_test.iloc[:10])
SHAP Waterfall Plot
shap.waterfall_plot(shap.Explanation(values=shap_values.values[0], base_values=explainer.expected_value, data=X_test.iloc[0]))
SHAP Decision Plot
shap.decision_plot(explainer.expected_value, shap_values.values[0], feature_names=X_test.columns.tolist())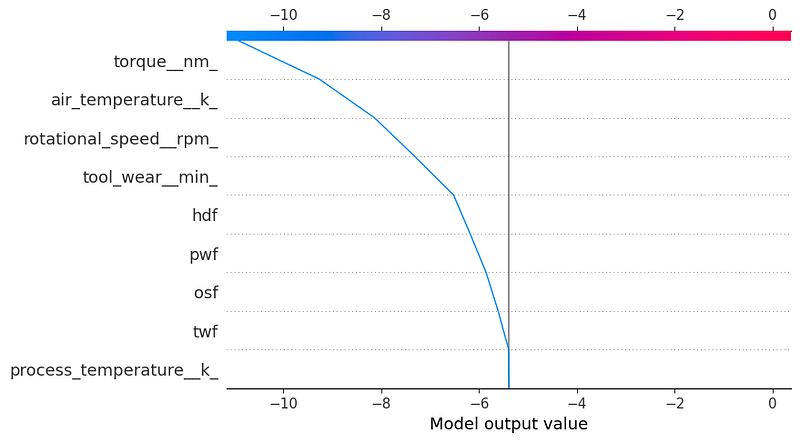
Conclusion
SHAP values are a game-changer for machine learning interpretability. They empower us to move beyond black box models and gain valuable insights into how these powerful tools are working. By understanding the “why” behind model predictions, we can build more trust, improve our models, and ultimately make better decisions. So, dive in, explore the Shap package, and start unlocking the secrets of your machine learning models!
If you found value in this post, feel free to treat me to my favorite coffee, a cappuccino! 😊
If you found this post helpful, a clap would mean a lot. Don’t forget to follow me on Medium for more articles like this!





