
Sequences: Why We Need Them
A practical example demonstrating how collections based on Iterable fall short, a novel explanation of why this happens using traversal precedence, and showing how Sequence naturally arises from this view.
— — — — — — — — — — — — — — —
THE CURRENT VERSION OF THIS ARTICLE IS PUBLISHED HERE.
— — — — — — — — — — — — — — —

Tags: #FYI++
This article is part of the Kotlin Primer, an opinionated guide to the Kotlin language, which is indented to help facilitate Kotlin adoption inside Java-centric organizations. It was originally written as an organizational learning resource for Etnetera a.s. and I would like to express my sincere gratitude for their support.
It is recommended to read the Introduction before moving on. Check out the Table of Contents for all articles.
The Sequence interface, and it’s inheritors, form a completely separate collection hierarchy from the one we’ve been talking about until now (List, Set etc.), which is based on Iterable. In this article, we’ll give an example that demonstrates how what we’ve learned so far can fall short, and proceed to take a look at the fundamental reason why that happens, which also turns out to be the fundamental difference between Sequence and “normal” collections.
Let’s go!
Problem Statement
Imagine you’re reading from a file that contains interactions in a chat room. The format of each line is [<timestamp>] <username>: <message>, as follows:
[1667735259] funnyuser1993: Knock knock
[1667735268] boreduser95: Who's there?...You want to find the first message that was sent by a given user in a given time window.
Here’s how you might implement it using an imperative style:
Ugh, that’s horrible. We just spent multiple chapters talking about all the awesome things in the standard library, and we’re not using any of them!
Let’s give it another go:
Much better. Right? Well…no. This “functional” version really reads much better, but there’s a big problem.
The imperative version only did the minimum number of operations necessary — it traversed the lines until it either found the one it was looking for, or moved beyond the time window, and then returned. At the same time, it managed all this without ever loading the entire file into memory, only loading one line at a time.
The functional version, while definitely prettier, completely throws performance considerations out of the window. Not only does it load the entire file into memory, but it traverses it multiple times — first when it loads it into memory, then twice more when it filters out the messages outside the time window, and then when it searches for the appropriate message. For the worst case scenario where the time window encompasses all the messages, and the message we’re searching for is at the end, this means the new version will take on the order of 4x longer than the original one. And this problem is further compounded with each operation we stack up.
There are certainly things we could to do optimize the new version, but you would find out that there’s only so much that can be done. In other words, it would seem that we’re forced to decide between readable code, and performant code.
Thankfully, you’ll soon see that’s not the case.
Traversal Precedence
Before we move on, it is important to understand what the fundamental difference between the two approaches above is.
Notice that, in the imperative version, we applied all operations to a given element before moving on to the next element — we took an element, checked if it was within the time window, checked if it matched the user we were searching for, and then possibly transformed it. For each element, this version traversed all the operations and applied them.
Contrast that with how the functional version works. The functional version takes the first operation, and applies it to all the elements. It then takes the second operation, and applies it to all elements, and so on. For each operation, this version traversed all the elements and applied the operation to them.
In other words, the fundamental difference between the two approaches is whether traversing elements is given precedence over traversing operations, or the other way around.
The contrast between these two approaches actually makes a lot of sense when you think about it. You have more than one operation, more than one element, and need to apply each operation to each element. You can represent this by making a table of operations and elements, like so:
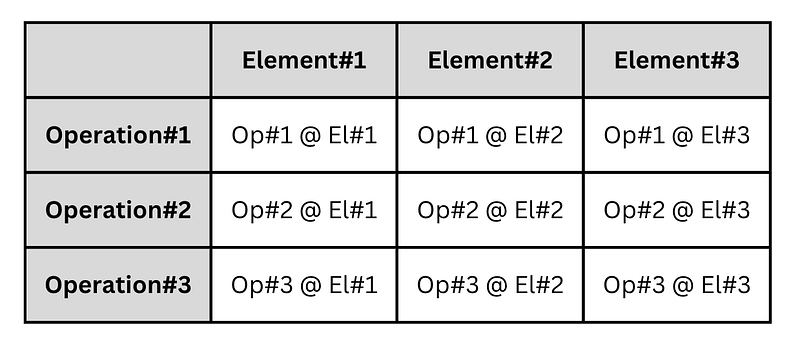
You need to traverse every cell in this table, and you have only two (reasonable) choices — either you go from left to right (give precedence to traversing elements), or from top to bottom (give precedence to traversing operations).
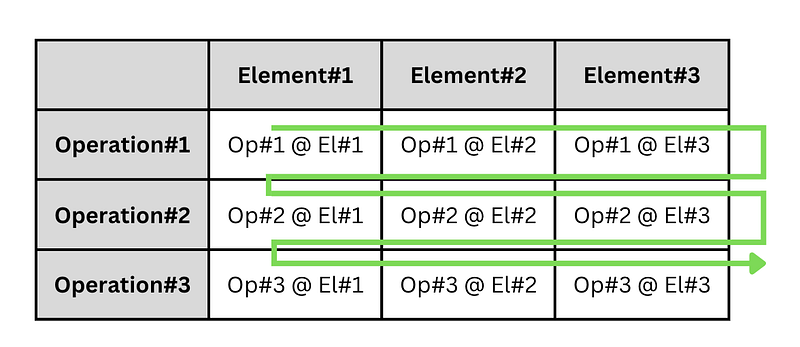
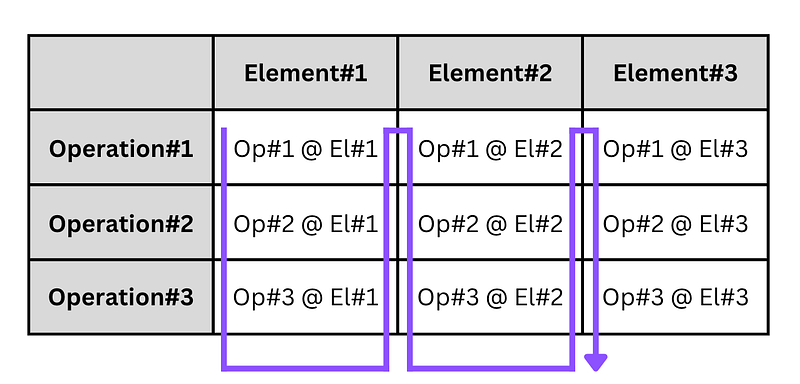
Our first, imperative, implementation of getFirstMessageOf above gave precedence to traversing operations, while our second, functional, implementation gave precedence to traversing elements.
Choosing a Style
When using an imperative code style, we can easily choose which of the above we want. Let’s illustrate this on a simple task:
Take a list of integers, filter out the even ones, and divide them by two.
However, when we want to use a functional approach, the methods we have at our disposal (defined on Iterable) are all of the element-traversal kind. It is, therefore, natural to ask — is there an implementation which gives precedence to traversing operations?
The answer is yes — that’s exactly what Sequence is.
Iterable vs. Sequence
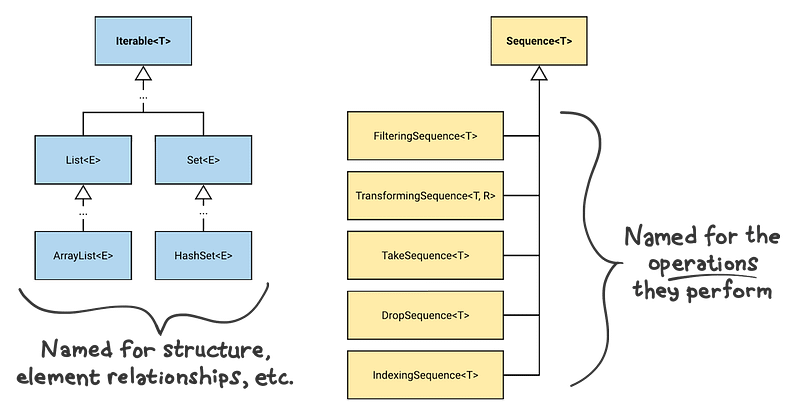
You already know Iterable well — it sits at the base of all the collections we’ve talked so far, such as List, Set, Map etc.
public interface Iterable<out T> {
/**
* Returns an iterator over the elements of this object.
*/
public operator fun iterator(): Iterator<T>
}Operations defined on Iterable give precedence to traversing elements, i.e. the first approach illustrated above.
At first look, it seems that Sequence is identical to Iterable, and this is often a source of confusion. Why define the same interface twice?
public interface Sequence<out T> {
/**
* Returns an [Iterator] that returns the values from
* the sequence.
*
* Throws an exception if the sequence is constrained
* to be iterated once and `iterator` is invoked the second
* time.
*/
public operator fun iterator(): Iterator<T>
}The answer is that, while the structure of the interface is identical, the contract that it represents is different — operations defined on Sequence give precedence to traversing operations, i.e. the second approach illustrated above.
Let’s put what we learned to good use, and rewrite the example in the introduction to use Sequence:
Notice that the code is identical to the code we wrote when we first translated the imperative version to the functional one, except for the call to File.useLines, which passes a Sequence of all the lines to its lambda parameter, and then closes the file. In other words, we are able to keep exactly the same benefits in readability, while recovering the effectiveness of the imperative version.
Once again, Kotlin allows us to have our cake, and eat it too.
Go back to Collection Operations: Grouping, jump to the Table of Contents, or continue to Sequences: How They Work & How To Use Them.






