
Senior Java AWS developer Interview Questions 01
In which scenarios would you choose Dynamo DB?
Reasons to Choose DynamoDB
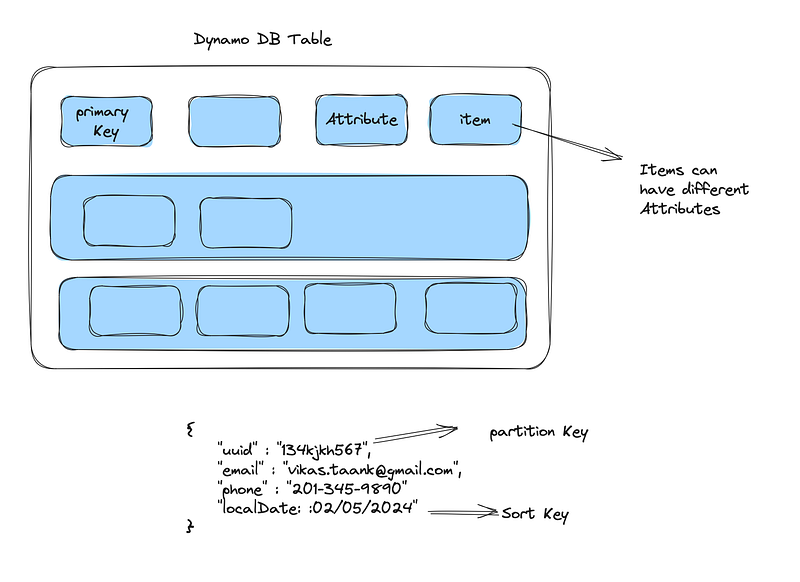
There are multiple reasons of choosing dynamo DB but not limited to:
Scalability: DynamoDB offers seamless scalability. You can start with minimal throughput and scale up to handle massive amounts of traffic with millions of requests per second.
Performance: It delivers single-digit millisecond response times at any scale. This is crucial for applications requiring fast access to data, like gaming, real-time analytics, or web applications.
Fully Managed Service: As a fully managed service, DynamoDB takes care of hardware maintenance, setup, configuration, replication, software patching, and scaling, reducing the overhead of managing a database.
High Availability and Durability: It automatically replicates data across multiple AWS Availability Zones, ensuring high availability and data durability.
Serverless Architecture Compatibility: It fits well within a serverless architecture, especially for applications built using AWS Lambda, as it provides triggers for real-time processing of streamed data.
Flexible Data Model: DynamoDB supports both document and key-value data models, offering flexibility in how you structure your data.
Global Tables: DynamoDB Global Tables provide a fully replicated multi-region, multi-master database without the need to manage replication or write conflict resolution logic.
How do you choose the partition key in Dynamo DB?
Choosing the right partition key in Amazon DynamoDB is crucial for ensuring efficient performance and scalability of your database. The partition key is used to distribute your data across different nodes for balanced read and write operations. Here are some guidelines to help you select an effective partition key:
What does partition key do?
- Data Distribution:
The partition key’s value determines which partition the data is stored in. DynamoDB uses the partition key’s value as input to an internal hash function to determine this.
- Uniqueness and Even Distribution:
Ideally, a partition key should have a high cardinality, which means the values are unique or almost unique across all items. This ensures an even distribution of data across partitions.
What are your data access patterns?
- Query Efficiency:
Choose a partition key that aligns with your application’s query patterns. You should be able to query and retrieve items efficiently based on the partition key.
- Avoid Hot Partitions:
A partition key that leads to uneven data access patterns (hot partitions) can create bottlenecks. Ensure that the access to data is as evenly distributed as possible.
Cardinality
- Cardinality:
A good partition key will have high cardinality. For example, user IDs or email addresses are better than gender or state, which have low cardinality.
- Variability:
Keys that change frequently may not be ideal, as they can lead to re-partitioning.
Partition Key and Sort Key
- Using Two Attributes: If a single attribute does not offer good distribution or aligns poorly with access patterns, consider using a composite primary key (partition key and sort key).
- Sort Key Utility: The sort key allows you to store multiple items with the same partition key but different sort keys. This is useful for one-to-many relationships, like users and their transactions.
Example Scenario: E-commerce Orders
Imagine we are designing a table to store order data for an e-commerce application. Each order has the following information:
OrderID: Unique identifier for each orderCustomerID: Identifier for the customer who placed the orderOrderDate: The date when the order was placedProductID: Identifier for the product orderedOrderAmount: The total amount of the order- Additional details like shipping address, order status, etc.
Access Patterns
- Retrieve all orders for a given customer.
- Retrieve a specific order by its order ID.
- Retrieve all orders within a specific date range.
Choosing Partition Key and Sort Key
Given these access patterns, we can design our DynamoDB table as follows:
- Table Name:
Orders - Partition Key:
CustomerID - Sort Key:
OrderID
Handling Other Access Patterns
- Secondary Index for Date Range Queries: To support the third access pattern (orders within a specific date range), we can create a Global Secondary Index (GSI) with
OrderDateas the partition key andOrderIDas the sort key.
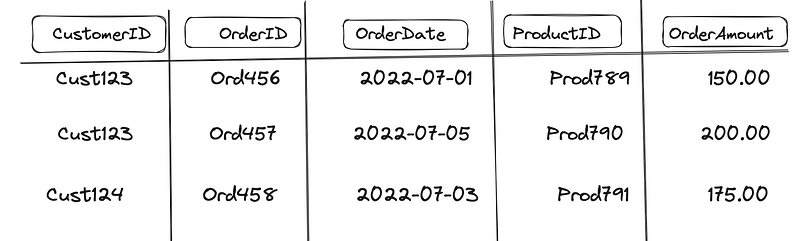
Table Design Summary
- Primary Key: (
CustomerID,OrderID) - Global Secondary Index: (
OrderDate,OrderID)
What are different kind of indexes in Dynamo DB?
Global Secondary Index (GSI)
- Enables querying data using an alternate key, in addition to the primary key of the table.
- Key Structure: You can define a completely different key structure for a GSI. This means you can have a different partition key and an optional sort key.
- GSIs are useful when you need to query your data with attributes other than the primary key of your table. For example, if your table uses a user ID as the primary key, but you frequently need to query by email address, you can create a GSI with the email address as the partition key.
- Performance: GSIs support eventually consistent or strongly consistent reads. They are maintained asynchronously, meaning that there might be a brief delay in synchronizing the data from the main table.
- Scalability and Provisioning: GSIs have their own throughput settings for read and write capacity, independent of the table’s settings.
Local Secondary Index (LSI)
- Purpose: Allows for additional query flexibility by using an alternate sort key, while keeping the same partition key as the base table.
- Key Structure: An LSI has the same partition key as the main table but a different sort key.
- Use Cases: LSIs are useful when you want to query your data across multiple dimensions. For instance, if your table’s primary key is a user ID (partition key) and timestamp (sort key), but you also want to query data by a different attribute like “last name” under the same user ID, an LSI would be appropriate.
- Performance: LSIs always provide strongly consistent reads.
LSIs must be defined at the time of table creation and cannot be added or removed later. Also, there is a limit on the total size of indexed items.
Key Differences Between GSI and LSI
- Key Flexibility: GSIs allow a different partition key and an optional sort key, while LSIs use the same partition key as the main table but a different sort key.
- Consistency: GSIs can provide either eventual or strong consistency, whereas LSIs always provide strong consistency.
- Scalability and Throughput: GSIs have separate throughput settings, while LSIs share throughput with the base table.
- Creation and Modification: GSIs can be added or removed after a table is created, but LSIs cannot.
Choosing the Right Index
- Access Patterns: Your choice between GSI and LSI depends on your specific access patterns and query requirements.
- Data Volume and Throughput Needs: Consider the volume of data and the throughput requirements for your application.
- Consistency Requirements: Decide whether you need strongly consistent reads (LSI) or if eventual consistency (GSI) is acceptable.
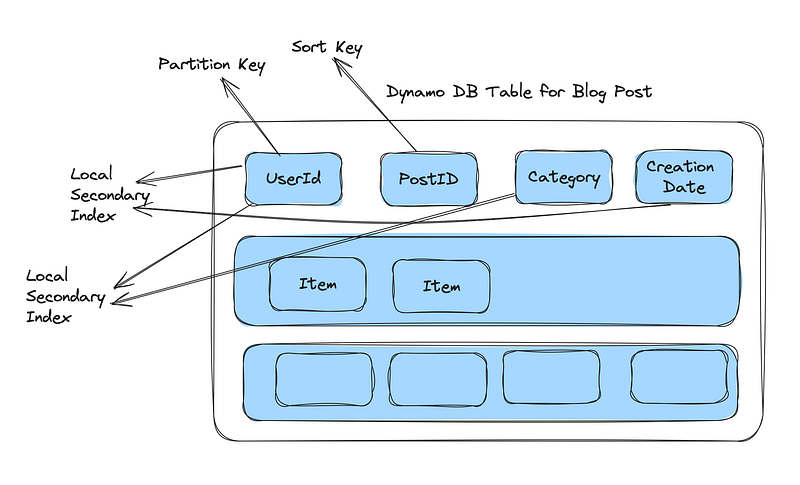
Example Use Case for Local Secondary Index (LSI)
Scenario: A blogging platform where each blog post is identified by a UserID (partition key) and PostID (sort key). You want to be able to query posts by the same UserID but using different attributes like CreationDate or Category.
Table Structure:
- Primary Key:
UserID(Partition Key),PostID(Sort Key) - Other Attributes:
Title,Content,CreationDate,Category
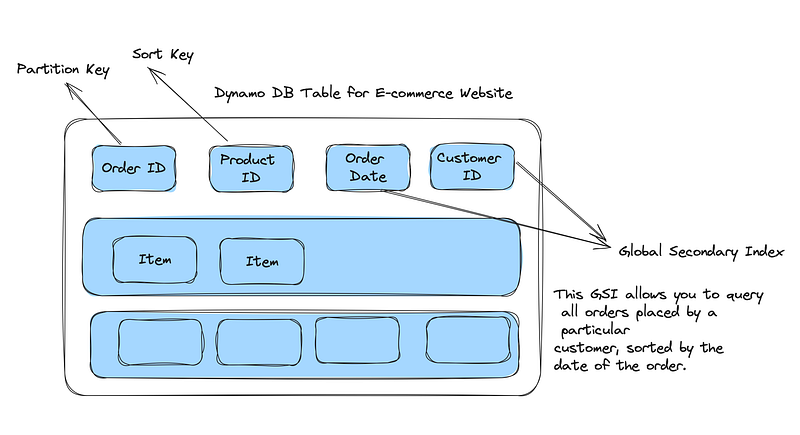
Example Use Case for Global Secondary Index (GSI)
Scenario: An e-commerce platform where each order is identified by an OrderID (partition key) and ProductID (sort key). However, you frequently need to query orders based on CustomerID and OrderDate.
Table Structure:
- Primary Key:
OrderID(Partition Key),ProductID(Sort Key) - Other Attributes:
CustomerID,OrderDate,Quantity,Price
GSI Use:
- You create a GSI with
CustomerIDas the partition key andOrderDateas the sort key. - Note here that LSI can only use the partition key as the partition key of the table however GSI can choose any other attribute as partition key and other key as Sort Key.
I hope you you will like this content and make use of this in your design choices. Thanks a lot for reading my content. I am really grateful to all my readers for reading my content and also clapping. Thanks keep reading , keep having fun.





