
Semi-Supervised Learning using Label Propagation
Label the unlabelled data using a semi-supervised Label Propagation algorithm
here you will learn
- What is semi-supervised learning?
- What is label propagation?
- How does it work?
- A Python implementation using sklearn
Semi-Supervised learning is a combination of supervised and unsupervised learning.
Supervised learning employs labeled data for training to learn the relationship between the input data and the target variable; however, unsupervised learning utilizes unlabeled data to identify the hidden data pattern in the input data.
Unlabeled data is easier to acquire and less costly compared to the labeled data. The semi-supervised machine learning technique aims to capitalize on the availability of a large amount of unbaled data to improve the generalization and performance of the model.
Semi-Supervised learning is
- Transductive learning: Transductive learning aims at classifying the unlabeled input data by exploiting the information derived from labeled data. It does not build the mapping function between the input data and target variable and hence learns a specific function for the input data. Example: Transductive Support vector machine(TSVM), Label Propagation Algorithm(LPA)
- Inductive learning: Learns from the labeled data and then predicts the unlabeled data. It draws conclusions based on observations and learns a generic function to map the input data to the target variable. Example: Traditional supervised learning algorithm.
Label Propagation and its working
Label propagation is a graph-based transductive method to infer pseudo-labels for unlabeled data. Unlabeled data points iteratively adopt the label of the majority of their neighbors based on the labelled data points
Label propagation makes a few assumptions.
- All classes for the dataset are present in the labeled data.
- Data points that are close have similar labels.
- Data points in the same cluster will likely have the same label.
A graph is a data structure consisting of nodes or vertices and edges. The edges represent the relationships between different objects.
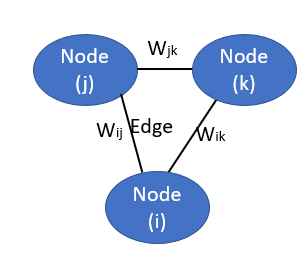
Label propagation creates a fully connected graph where the nodes are all the labeled and unlabeled data points.
The edges between the two nodes are weighted. The shorter the euclidean distance between two nodes, the larger the weight will be. A larger edge weight allows the label to travel easily.
A simple explanation of the working of the Label propagation Algorithm
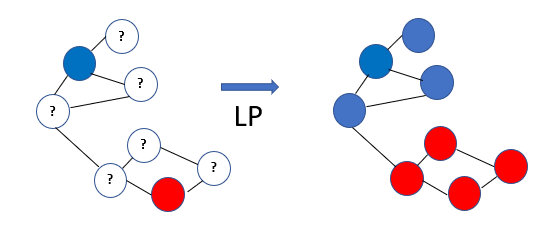
- All nodes have soft labels assigned based on the distribution over labels
- Labels of a node are propagated to all nodes through Edges
- Each Node will update its label iteratively based on the maximum number of Nodes in its neighborhood. The label of a node is persisted from the labeled data, making it possible to infer a broad range of traits that are assortative along the edges of a graph.
- Label propagation algorithm stops when every node for the unlabeled data point has the majority label of its neighbor or the number of iteration defined is reached.
Implementation using sklearn
Here we are using the breast cancer dataset from sklearn. The dataset will contain all of the input data, and the target will contain both labeled and unlabeled data.
The unlabeled points are marked as -1
The label Propagation algorithm will classify the unlabeled data
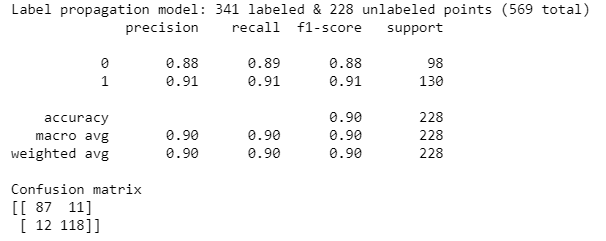
As we change the number of unlabeled data points, we can see the change in the performance matrix.
Conclusion:
Label Propagation is a semi-supervised graph-based transductive algorithm to label the unlabeled data points. Label Propagation algorithm works by constructing a similarity graph over all items in the input dataset. It works on the assumption that all data points close to each other will have similar labels. Labels are assigned to unlabeled data points based on the maximum number of labeled nodes in its neighborhood.
References:
Learning from Labeled and Unlabeled Data with Label Propagation
Unlabeled data: Now it helps, now it doesn’t
https://en.wikipedia.org/wiki/Transduction_(machine_learning)
https://stanford.edu/~jugander/papers/wsdm13-blp.pdf
https://scikit-learn.org/stable/modules/semi_supervised.html#label-propagation