
SEC FILINGS QUESTION ANSWERING AND SUMMARIZATION: CHROMA DB, LANGCHAIN AND LLAMA INDEX
This article talks about my project on SEC filings question answering and summarization. Every publicly listed company has to file a yearly (10-K) and quarterly report (10-Q). With the rise in generative AI language models, we can build question-answering systems and summarization for these documents. Here are the project links and the SEC Data Downloader
SEC Data Downloader: https://llamahub.ai/l/sec_filings
QUESTION ANSWERING SYSTEM (SUPPORT ONLY FOR 10-K)
- Here I will explain the design decisions that I took while building the project
- I am using two LLMs here, one to understand the query and build the metadata for retrieval, and the second LLM to answer the question from the relevant context
section_names = ResponseSchema(name="Section_Names", description="Name of the sections")
tickers = ResponseSchema(
name="Tickers",
description="Name of the tickers, make sure to convert company names to tickers",
)
years = ResponseSchema(
name="Years",
description="Years mentioned, if no years are mentioned then output the last 5 years ['2018','2019','2020','2021','2022']",
)
# response_schema = [section_names, tickers, years, augmented_query]
response_schema = [section_names, tickers, years]
output_parse = StructuredOutputParser.from_response_schemas(response_schema)
format_instructions = output_parse.get_format_instructions()
llm1_template = """
You are a financial statement analyst, and here are the definitions of different sections {definitions_of_sections} in a SEC filings.\n
The definition is formatted as Section_Name: definition of the section. Based on the definitions, return the top {num_returns} possible section names that the user is asking for.\n
User request: "{user_request}"
{format_instructions}
"""
"""
Return the stocks tickers mentioned in the user query, make sure that you convert the company name to ticker.\n
Return the years that are mentioned in the user query, and if nothing is mentioned, then output the last 5 years. \n
For example:
User Query: What are the risk factors for Apple and Google for the year 2021 and 2022?\n
Augmented Query: ["What are the risk factors for Apple in 2022?","What are the risk factors for Apple in 2021?","What are the risk factors for Google in 2022?","What are the risk factors for Google in 2021?"]\n
"""
llm_1_prompt_template = PromptTemplate(
input_variables=[
"definitions_of_sections",
"user_request",
"num_returns",
"format_instructions",
],
template=llm1_template,
)
# Load variables from .env file
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
openai.api_key = openai_api_key
# autolog({"project":PROJECT, "job_type": JOB_TYPE+"_LLM1"})
# print(format_instructions)
def get_response_llm1(USER_REQUEST: str, filing_type: str = "10-K") -> dict:
if filing_type == "10-K":
section_def = DEFINITIONS_10K
elif filing_type == "10-Q":
section_def = DEFINITIONS_10Q
llm1_prompt = llm_1_prompt_template.format(
definitions_of_sections=section_def,
num_returns=NUM_SECTION_RETURN,
user_request=USER_REQUEST,
format_instructions=format_instructions,
)
llm1 = OpenAI(temperature=0.0)
output_1 = llm1.predict(llm1_prompt)
llm1_output_dict = output_parse.parse(output_1)
for key in llm1_output_dict:
if not isinstance(llm1_output_dict[key], list):
llm1_output_dict[key] = llm1_output_dict[key].split(", ")
llm1_output_dict["Section_Names"] = [
i.upper() for i in llm1_output_dict["Section_Names"]
]
llm1_output_dict['Section_Names'] = ["_".join(sec.split(" ")) for sec in llm1_output_dict['Section_Names'] ]
# print(llm1_output_dict)
# query_metadata = get_query_metadata(llm1_output_dict)
return llm1_output_dict- You can see that we have a structured output parser from Langchain to extract the sections where the answer to the query can be present, the years and the tickers. So for a query What are the risk factors of Apple for the year 2022? It will output
{
"Tickers":['AAPL'],
"Years":["2022"],
"Section_Names":["RISK_FACTORS","MANAGEMENT_AND_DISCUSSION"]
}2. Now, while building the database, I am storing the results using FinBERT embeddings in ChromaDB. By default, it takes in Sentence Transformer Embeddings (model_name=”all-MiniLM-L6-v2"), but you can also use FinBERT embeddings. Finance-specific embeddings may help us to better tokenize the financial documents, which will help us in our retrieval
class FinBertEmbeddings(EmbeddingFunction):
def __call__(self, texts: Documents) -> Embeddings:
embed_out = finbert_embed.embed_documents(texts)
return embed_out
def create_vector_store_langchain(documents, doc_name: str, if_finbert: bool = False):
if if_finbert:
embedding_function = FinBertEmbeddings()
else:
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2"
)
vector_store = Chroma.from_documents(
documents=documents,
embedding=embedding_function,
ids=[f"id{i}" for i in range(len(documents))],
persist_directory=f"sec-{doc_name}",
collection_name=f"SEC-{doc_name}",
)
vector_store.persist()
return vector_store3. Metadata creation was a bit tricky. After chunking the documents, we saved each chunked document in the following way
metadata_dict.update(
{
"full_metadata": sm["ticker"]
+ "_"
+ sm["year"]
+ "_"
+ sm["section"]
+ "_"
+ sm["filing_type"]
}
)You can see here that the full_metadata is saved as ticker, year, section name, and filing type. From our LLM-1, we get all this information, and we combine it in the above manner for the where clause in ChromaDB
def get_relevant_docs(query_metadata, restore_collection,user_request:str):
# print(llm1_output_dict)
if len(query_metadata) <= 1:
where_clause = query_metadata[0]
else:
where_clause = {"$or": query_metadata}
query_results = restore_collection.query(
query_texts=user_request,
n_results=20,
where=where_clause,
include=["metadatas", "documents", "distances", "embeddings"],
)
return query_results- You can see that the where clause has an OR condition to get the data from different sections. For example “AAPL_2022_RISK_FACTORS_10-K” OR “AAPL_2022_MANAGEMENT_AND_DISCUSSION_10-K”.
4. Also, we do Maximum Marginal Relevance to get the most diverse set of documents from our retrieved documents. This is useful in answering subjective questions, but not objective questions.
#Taken from Langchain math utils
def maximal_marginal_relevance(
query_embedding: np.ndarray,
embedding_list: list,
lambda_mult: float = 0.5,
k: int = 4,
) -> List[int]:
"""Calculate maximal marginal relevance."""
if min(k, len(embedding_list)) <= 0:
return []
if query_embedding.ndim == 1:
query_embedding = np.expand_dims(query_embedding, axis=0)
similarity_to_query = cosine_similarity(query_embedding, embedding_list)[0]
most_similar = int(np.argmax(similarity_to_query))
idxs = [most_similar]
selected = np.array([embedding_list[most_similar]])
while len(idxs) < min(k, len(embedding_list)):
best_score = -np.inf
idx_to_add = -1
similarity_to_selected = cosine_similarity(embedding_list, selected)
for i, query_score in enumerate(similarity_to_query):
if i in idxs:
continue
redundant_score = max(similarity_to_selected[i])
equation_score = (
lambda_mult * query_score - (1 - lambda_mult) * redundant_score
)
if equation_score > best_score:
best_score = equation_score
idx_to_add = i
idxs.append(idx_to_add)
selected = np.append(selected, [embedding_list[idx_to_add]], axis=0)
return idxs5. After getting the relevant data, we put everything in our prompt based on the ticker symbol and year and send it to our LLM-2 to generate the final answer
def get_response_llm2(relevant_sentences, user_query, llm1_output_dict):
llm2_template = """
You are a financial statement analyst with a strong understanding of financial documents and fundamental analysis. Base your answer only on the following relevant documentss: \n
{relevant_documents} \n\n
Answer the user question {user_query}\n
Don't make up any information, and if the relevant information is not present, then just give the most similar answer to the user query from the relevant documents and politely give a warning that the information that the user is looking for, may not be in the documents\n
Also, include all the relevant numerical figures\n
Recheck your answer so that it is more coherent with what user is asking\n
"""
llm2_prompt_template = PromptTemplate(
input_variables=["relevant_documents", "user_query"], template=llm2_template
)
# user_query = llm1_output_dict["augmented_query"]
# user_query = query_1+query_2
llm2_prompt = llm2_prompt_template.format(
user_query=user_query, relevant_documents=relevant_sentences
)
openai.api_key = os.environ["OPENAI_API_KEY"]
llm_2 = ChatOpenAI(temperature=0.0, model="gpt-3.5-turbo-16k",streaming=True)
output = llm_2.predict(llm2_prompt)
return outputSUMMARIZATION PROJECT
- Now, let’s go to the summarization project. Here, we build a tree-based summarization using llama_index.
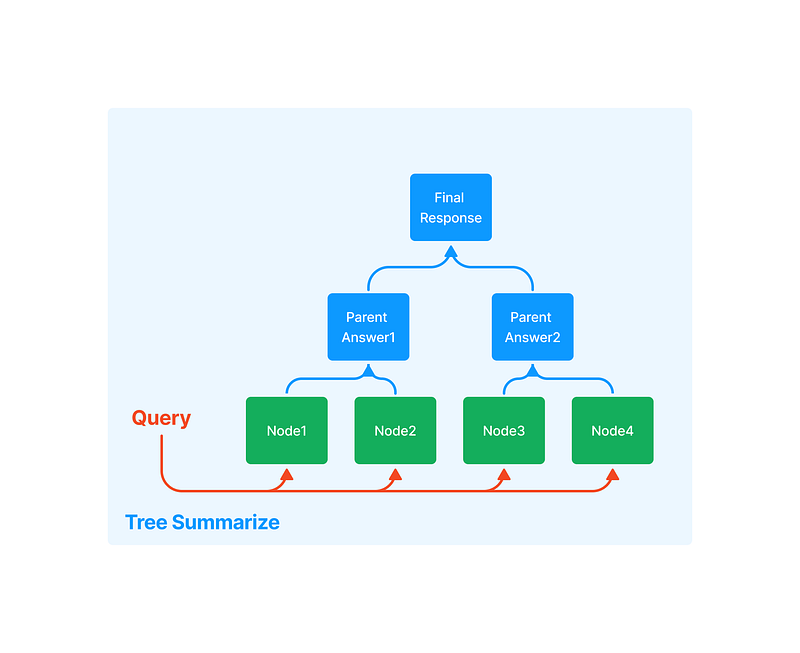
- Here, we build a bottom-up summarization of all the chunked documents. And we explicitly mention in the prompt to keep all the numerical figures.
- Also, we keep track of amended documents and see what are the changes in the amended documents compared to the originally published documents
def get_response(
doc: str,
query_str: str,
chunk_size: int = 1024,
chunk_overlap: int = 128,
verbose: bool = True,
use_async: bool = True,
):
service_context = ServiceContext.from_defaults(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
)
summarizer = TreeSummarize(
verbose=verbose, service_context=service_context, use_async=use_async
)
response = summarizer.get_response(query_str, [doc])
return response
def get_summary(
docs: List[str],
metadata: List[dict],
ticker,
year,
filing_type: str = "10-K",
quarters: str = "",
):
os.makedirs("summaries", exist_ok=True)
if filing_type == "10-K":
ALL_SECTIONS = SECTIONS_10K
elif filing_type == "10-Q":
ALL_SECTIONS = SECTIONS_10Q
full_summary = ""
for section in ALL_SECTIONS:
summary = ""
# Give me the idxs in splitted metadata for which we have this section
sections_docs = ""
section_amended_docs = ""
for idx, meta in enumerate(metadata):
sm = meta["full_metadata"]
if section in sm:
if sm.endswith(filing_type):
sections_docs = docs[idx]
elif sm.endswith(f"{filing_type}/A"):
# elif sm.endswith("10-K/A"):
section_amended_docs = docs[idx]
if filing_type == "10-Q":
file_name = f"summaries/{ticker}_{year}_{filing_type}_{quarters}.txt"
elif filing_type == "10-K":
file_name = f"summaries/{ticker}_{year}_{filing_type}.txt"
#Empty Section
if sections_docs == "":
summary += " ".join(section.split("_")) + "\n"
summary += ""
summary += "\n\n"
full_summary += summary
with open(file_name, "a") as f:
f.write(summary)
#Non-empty section but empty amended section
elif section_amended_docs == "" and sections_docs != "":
response = get_response(sections_docs, query_str)
summary += " ".join(section.split("_")) + "\n"
summary += response
summary += "\n\n"
full_summary += summary
with open(file_name, "a") as f:
f.write(summary)
#Both section and amended section non-empty
elif section_amended_docs != "" and sections_docs != "":
section_response = get_response(sections_docs, query_str)
section_amended_response = get_response(section_amended_docs, query_str)
summary += " ".join(section.split("_")) + "\n"
summary += section_response + "\n\n"
summary += "Amended Section: \n" + section_amended_response
summary += "\n\n"
full_summary += summary
with open(file_name, "a") as f:
f.write(summary)
return full_summary- The summary of Tesla 10-Q for Q3 2022 will look like
FINANCIAL STATEMENTS MANAGEMENT DISCUSSION The company's mission is to accelerate the world's transition to sustainable energy. They design, develop, manufacture, lease, and sell electric vehicles, solar energy systems, and energy storage products. They also offer maintenance, installation, operation, financial, and other services related to their products. The company is focused on increasing vehicle production, capacity, and delivery capabilities, improving battery technologies, and expanding their global infrastructure. They have produced 929,910 vehicles and delivered 908,573 vehicles in 2022. They have also deployed 4.08 GWh of energy storage products and 248 megawatts of solar energy systems. The company has recognized total revenues of $21.45 billion and $57.14 billion for the three and nine months ended September 30, 2022, respectively. Their net income attributable to common stockholders was $3.29 billion and $8.87 billion for the same periods. They ended the third quarter of 2022 with $21.11 billion in cash and cash equivalents and marketable securities. The company's cash flows provided by operating activities during the nine-month period ended September 30, 2022, was $11.45 billion. Their capital expenditures amounted to $5.30 billion during the same period. In the three months ended September 30, 2022, interest income increased by $109 million, or 352%, compared to the same period in 2021. In the same period, interest expense decreased by $73 million, or 58%, compared to the three months ended September 30, 2021. Other (expense) income, net, changed unfavorably by $79 million in the three months ended September 30, 2022, compared to the same period in 2021. The provision for income taxes increased by $82 million, or 37%, in the three months ended September 30, 2022, compared to the same period in 2021. Net income attributable to noncontrolling interests and redeemable noncontrolling interests decreased by $2 million, or 5%, in the three months ended September 30, 2022, compared to the same period in 2021. In the nine months ended September 30, 2022, interest income increased by $109 million, or 352%, compared to the same period in 2021. In the same period, interest expense decreased by $142 million, or 47%, compared to the nine months ended September 30, 2021. Other (expense) income, net, changed unfavorably by $68 million in the nine months ended September 30, 2022, compared to the same period in 2021. The provision for income taxes increased by $449 million, or 110%, in the nine months ended September 30, 2022, compared to the same period in 2021. Net income attributable to noncontrolling interests and redeemable noncontrolling interests decreased by $92 million, or 89%, in the nine months ended September 30, 2022, compared to the same period in 2021. As of September 30, 2022, the company had $19.53 billion of cash and cash equivalents, with balances held in foreign currencies having a U.S. dollar equivalent of $6.28 billion. The company had $2.41 billion of unused committed amounts under its credit facilities as of September 30, 2022. Net cash provided by operating activities increased by $4.53 billion to $11.45 billion during the nine months ended September 30, 2022, compared to the same period in 2021. Capital expenditures were $5.30 billion for the nine months ended September 30, 2022, mainly for the expansions of various manufacturing facilities. Net cash used in financing activities decreased by $914 million to $3.03 billion during the nine months ended September 30, 2022, compared to the same period in 2021. The fair market value of the company's remaining holdings of digital assets as of September 30, 2022, was $226 million. MARKET RISK DISCLOSURES The company conducts global business in multiple currencies, which exposes them to foreign currency risks. These risks include revenue, costs of revenue, operating expenses, and localized subsidiary debt denominated in currencies other than the U.S. dollar. The company is generally a net receiver of currencies other than the U.S. dollar for their foreign subsidiaries. Fluctuations in exchange rates impact their revenue and operating results in U.S. dollars, as they do not typically hedge foreign currency risk. The company has experienced fluctuations in net income due to gains or losses on the settlement and re-measurement of monetary assets and liabilities denominated in non-local currencies. Based on historical trends, adverse changes in foreign currency exchange rates of 10% for all currencies could be experienced in the near-term. These changes would have resulted in a gain or loss of $56 million at September 30, 2022, and $277 million at December 31, 2021, assuming no foreign currency hedging. The company is also exposed to interest rate risk on their borrowings with floating rates. They utilize derivative instruments to manage some of this risk, but not for trading or speculative purposes. A hypothetical 10% change in interest rates on their floating rate debt would have had an immaterial impact on interest expense for the nine months ended September 30, 2022, and 2021. CONTROLS AND PROCEDURES LEGAL PROCEEDINGS The text discusses litigation related to the acquisition of SolarCity. It does not provide any specific numerical figures. RISK FACTORS The given text discusses various risks and challenges faced by the company, including the impact of the global COVID-19 pandemic on operations, disruptions in the supply chain, and government regulations. It also mentions the shortage of semiconductors, labor shortages, and worker absenteeism. The text highlights the importance of suppliers, stable production workforce, and government cooperation for sustaining production and meeting demand. It mentions delays in launching and ramping production of new products, as well as potential challenges during production ramps. The text also emphasizes the impact of disruptions in the supply chain and the global shortage of semiconductors on production. Numerical figures mentioned in the text include the company's outstanding indebtedness of $2.41 billion as of September 30, 2022, and the various currencies in which the company transacts business and has debt denominated, including the Chinese yuan, euro, South Korean won, and pound sterling. USE OF PROCEEDS In March 2017, warrants were sold to several entities, including Goldman, Sachs & Co., Deutsche Bank Securities Inc., Citigroup Global Markets Inc., National Bank of Canada (assigned from Citigroup), Morgan Stanley & Co. LLC, and Barclays Capital Inc. These warrants were connected to the offering of the 2.375% Convertible Senior Notes due 2022. Between July 1, 2022, and August 15, 2022, a total of 28,853,619 shares of common stock were issued to the 2017 Warrantholders upon exercising their warrants. These shares were issued under an exemption from registration provided by Rule 3(a)(9) of the Securities Act of 1933. DEFAULTS MINE SAFETY OTHER INFORMATION
The Dockerfile for both applications are similar
FROM python:3.10-slim
COPY ./requirements.txt .
RUN apt-get update && apt-get install -y \
build-essential \
curl \
software-properties-common \
git \
&& rm -rf /var/lib/apt/lists/*
RUN pip3 install --upgrade pip
RUN pip3 install -r requirements.txt
WORKDIR /app
COPY . /app
EXPOSE 8051
HEALTHCHECK CMD curl --fail http://localhost:8501/_stcore/health
ENTRYPOINT [ "streamlit", "run" ]
CMD [ "Home.py", "--server.fileWatcherType", "none", "--browser.gatherUsageStats", "false", "--server.address", "0.0.0.0"]So this brings us an end to these two projects. If you are interested in what I am doing, please drop me a message and I would be happy to collaborate on the project and build something useful. Any queries, I am comment away.





