
Search, Rank, and Recommendations
Easy way to re-rank search results and personalized recommendations.
This post is in continuation of my previous post “ Semantic Search with S-BERT is all you need”
What we covered in the previous post:
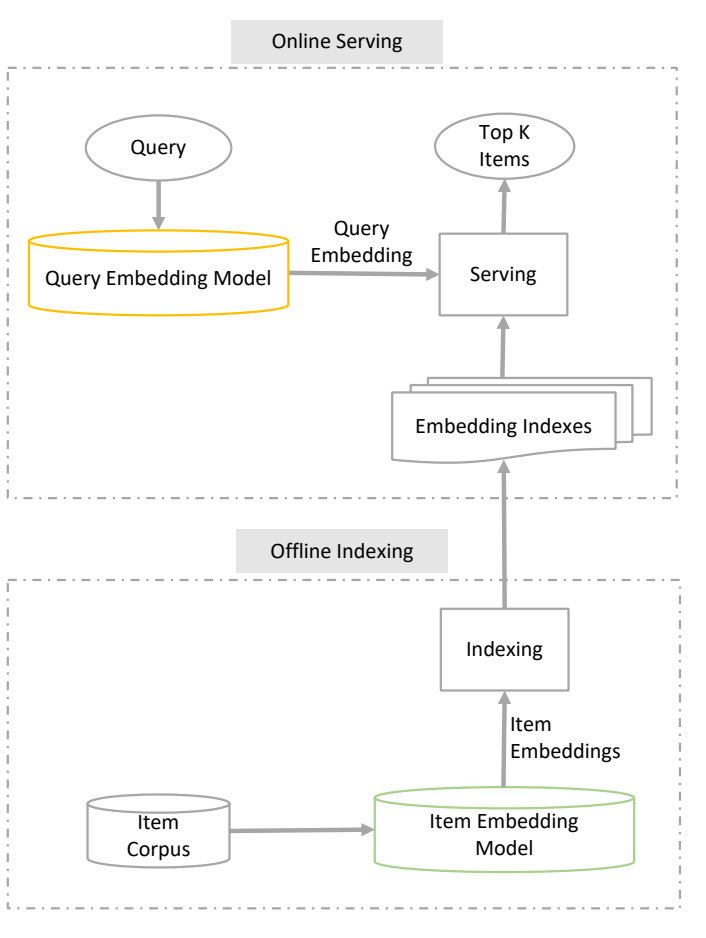
- Types of search: Asymmetric & Symmetric
- Dot Product and Cosine Product Based models
- Embeddings Storage (FAISS)
- Synthetic Query Generation
- Bi-Encoder Finetuning
And what we left hanging there were some important questions:
- methods of re-ranking of results
- quality of results, how inlined it is wrt to a user query.
- how to incorporate user behavior in recommending results
Get Started: Overview
Search Ranking and Recommendations are fundamental problems of crucial interest to major Internet companies, including web search engines, content publishing websites, and marketplaces. However, despite sharing some common characteristics a one-size-fits-all solution does not exist in this space. Given a large difference in content that needs to be ranked, personalized, and recommended, each marketplace has a somewhat unique challenge.
Search and recommendations have a lot in common. They help users learn about new products, and need to retrieve and rank millions of products in a very short time (<150ms). They’re trained on similar data, have content and behavioral-based approaches, and optimize for engagement (e.g., click-through rate) and revenue (e.g., conversion, gross merchandise value).
Nonetheless, search differs in one key aspect — it has the user’s query as additional input. (Think of search as recommendations with the query as extra context.) This is a boon and a bane. It’s a boon because the query provides more context to help us help users find what they want; it’s a bane because users expect results to be in line with their query.
One common architecture for search and recommendation systems consists of the following components:
- candidate generation
- scoring
- re-ranking
In the previous post, we understood how to create a concept search by better understanding the data and fine-tuning our model to generate better candidates for a user search query.
However, the retrieval system might retrieve documents that are not that relevant for the search query. Hence, in a second stage, we use a re-ranker based on a cross-encoder that scores the relevancy of all candidates for the given search query.
Cross-Encoders
C.E performs full (cross) self-attention over a given input and label candidate, and tends to attain much higher accuracies than their counterparts. Cross-Encoders can be used whenever we have a pre-defined set of sentence pairs we want to score.
A re-ranker based on a Cross-Encoder can substantially improve the final results for the user. The query and a possible document is passed simultaneously to the transformer network, which then outputs a single score between 0 and 1 indicating how relevant the document is for the given query.
Since we were dealing with movie plots, I passed the user query and plots retrieved.
Kaggle Kernel: https://www.kaggle.com/sbrvrm/search-ranking
def cross_score(model_inputs):
scores = cross_model.predict(model_inputs)
return scores
model_inputs = [[query,item['Plot']] for item in results]
scores = cross_score(model_inputs)
#Sort the scores in decreasing order
ranked_results = [{'Title': inp['Title'], 'Score': score} for inp, score in zip(results, scores)]
ranked_results = sorted(ranked_results, key=lambda x: x['Score'], reverse=True)Before:
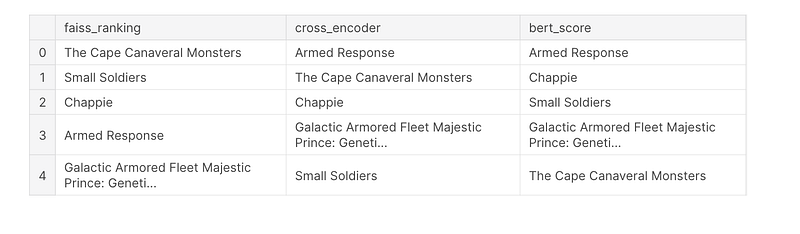
query="Artificial Intelligence based action movie"
results=search(query, top_k=5, index=index, model=model)Results: 'Title': 'The Cape Canaveral Monsters' 'Title': 'Small Soldiers' 'Title': 'Chappie' 'Title': 'Armed Response' 'Title': 'Galactic Armored Fleet Majestic Prince: Genetic Awakening'
After using cross-encoder and sorting results with the score:
'Title': 'Armed Response' 'Title': 'The Cape Canaveral Monsters' 'Title': 'Chappie' 'Title': 'Galactic Armored Fleet Majestic Prince: Genetic Awakening' 'Title': 'Small Soldiers'
BERT-score (Bert Token Embeddings+Token IDF weights)
BERTScore leverages the pre-trained contextual embeddings from BERT and matches words in candidate and reference sentences by cosine similarity. It has been shown to correlate with human judgment on sentence-level and system-level evaluation. Moreover, BERTScore computes precision, recall, and F1 measure, which can be useful for evaluating different language generation tasks.
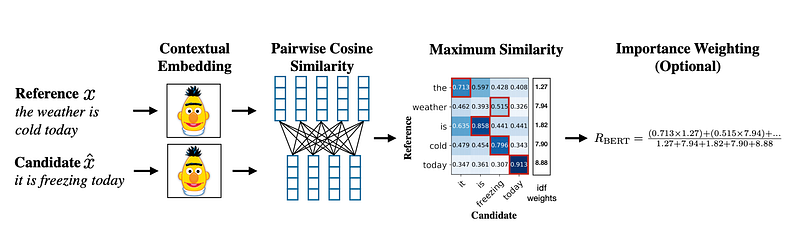
Taking our query as reference and results as the candidates we calculate BERT score f1.
ranked_results_bert = []
for cand in results:
P, R, F1 = score([cand['Plot']], ref, lang='en')
ranked_results_bert.append({'Title': cand['Title'], 'Score': F1.numpy()[0]})Results:'Title': 'Armed Response' 'Title': 'Chappie' 'Title': 'Small Soldiers' 'Title': 'Galactic Armored Fleet Majestic Prince: Genetic Awakening' 'Title': 'The Cape Canaveral Monsters'
The below diagram represents roughly what we have covered in this series, what we have not discussed is taking user behavior into account while showing results or performing new recommendations on the basis of past searches.
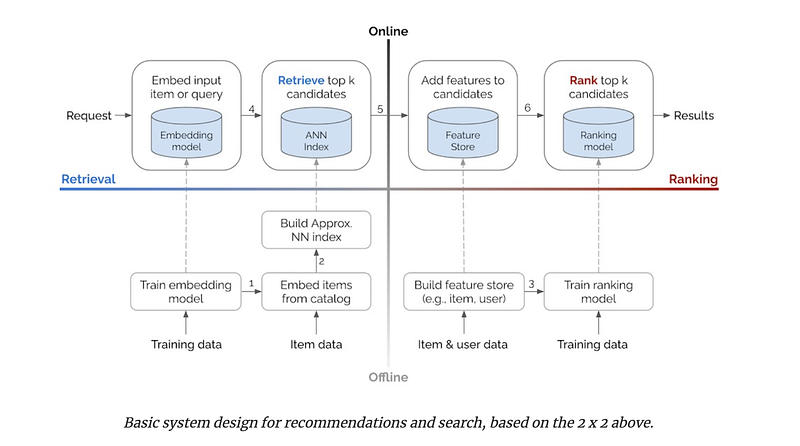
Personalization in Search using Embeddings
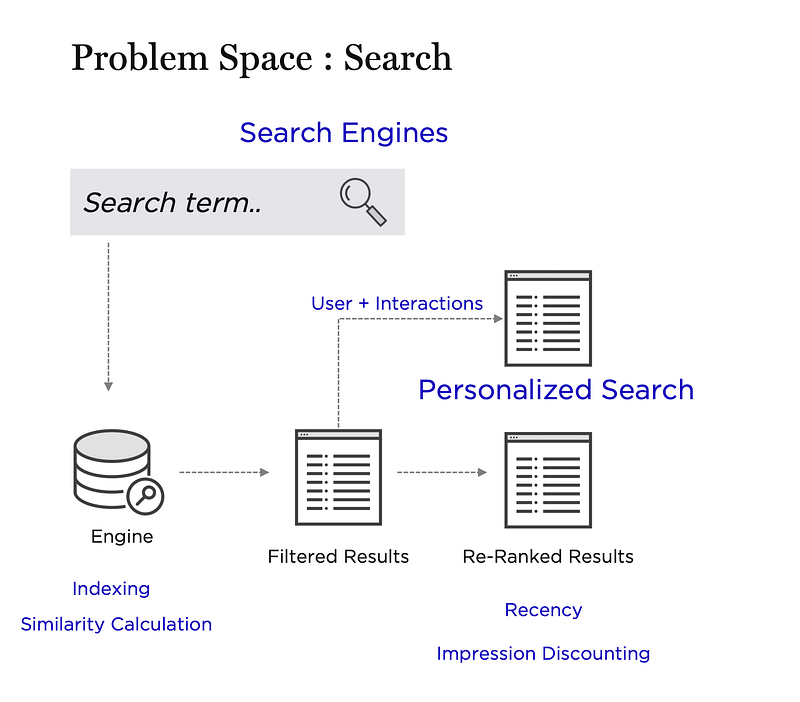
Now understanding user behavior can be done via his past item interactions/searches or from similar interest users, famously know to everyone as content-based and collaborative recommenders. These are not just helpful in recommendations but can help rank results.
Before we jump to any formulation, let’s understand that just recommending things to has also dependency on recency and frequency of items. The genre of movies that a user browsed or viewed recently reflects his recent taste and area of interest, so we might wanna give a weightage to that while recommending the results items while keeping the frequency factor into consideration.
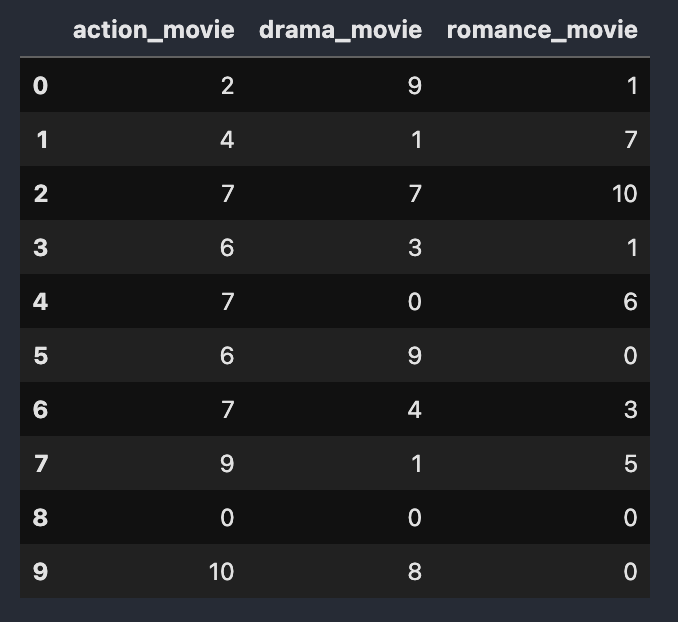
Let’s take the example of movies only. User A has watched or interacted with 3 genres of movies say action, drama, and romance.
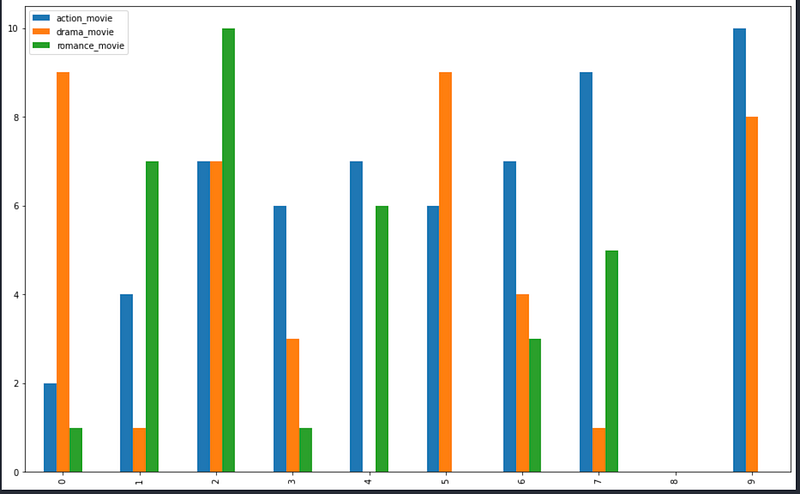
Below Data shows week-wise interaction history with each genre of movie. It clearly shows the taste of users has inclined more towards action movies and affinity towards romance movies has declined.
We use the exponential recency weighted average formula to aggregate the user browsing history. Below is the Recommended For You (RFY Model) formula :

This aligns with our assumption that the most recent browsing data contributes most to the prediction of the next action. x(i) is our item vector and w(i) is the weight assigned based on its recency.
For alpha=0.5, a higher value of “i” will be assigned higher weightage. I have modified the above little bit and added softmax across all the item weights before getting the weighted vector.
*************** method-1 ****************
>> softmax(np.asarray([weight(10), weight(8), weight(0)]))
array([0.43589772, 0.29958783, 0.26451446])I only took the recent browsing data count and calculated the weight for the respective genre of the movie. But it did not take into account the past 9-week window. So let us consider something which gives a distance score keeping in mind the complete user watch history data distribution i.e z-score.
action_movie_zscore = stats.zscore(user_watch_hist[‘action_movie’])[-1] drama_movie_zscore = stats.zscore(user_watch_hist[‘drama_movie’])[-1] romance_movie_zscore = stats.zscore(user_watch_hist[‘romance_movie’])[-1]
*************** method-2 ****************
>> x = np.asarray([action_movie_zscore, drama_movie_zscore, romance_movie_zscore])
>> softmax(x)
array([0.56467654, 0.38601828, 0.04930517])Z-score is easier to calculate and maintain and is a powerful metric that reflects how far the current observation is from the mean. It is quite clear from the softmax output of method-1 and method-2 that later has much more user behavior relevancy in its score. The added benefit of the z-score based softmax method is for newly or recently added genres in the catalog. Suppose you have a new genre so you add a z-score ‘0’ corresponding to that genre.
>> x = np.asarray([action_movie_zscore, drama_movie_zscore, romance_movie_zscore, 0])
>> softmax(x)
array([0.49878136, 0.34097171, 0.04355148, 0.11669544])You can see from the weight scores that it has assigned more weightage than romance movies, so your final recommendation will have diversity and freshness in recommendations.
from sentence_transformers import SentenceTransformer, util#Compute embeddings of retrieved candidate movie plots
embeddings = model.encode(candidate_plots)#Compute cosine-similarities for each plot with user vector
cosine_scores = util.pytorch_cos_sim(user_encoded_vector, embeddings)#Find the pairs with the highest cosine similarity scores
titles = [x[‘Title’] for x in results]ranked_user_behaviour = [{‘Title’:x ,’Score’: y} for x,y in zip(titles,cosine_scores.numpy()[0])]
ranked_user_behaviour = sorted(ranked_user_behaviour, key=lambda x: x[‘Score’], reverse=True)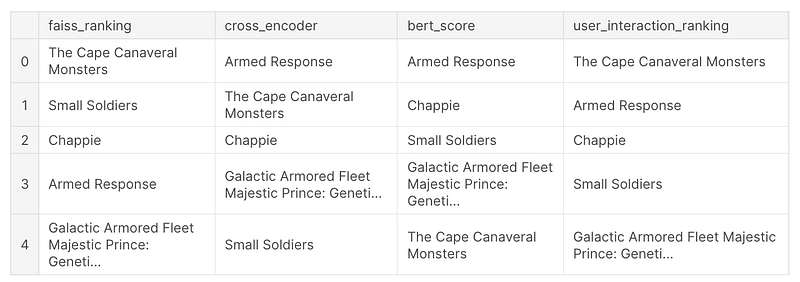
We use the user behavior (user_encoded_vector) to re-rank the output shown to User A.
And when he returns back to home page we use the same user_encoded_vector to fetch nearest neighbor movies and can recommend him to watch them. The recommendation will have lot of action movies, drama and bit of romace too.
#codet=time.time()
query_vector = user_encoded_vector
top_k = index.search(query_vector, 20)
top_k_ids = top_k[1].tolist()[0]
top_k_ids = list(np.unique(top_k_ids))
[fetch_movie_info(idx) for idx in top_k_ids]#output>>>> Recommendation Results in Total Time: 0.03316307067871094[{'Title': 'Key Witness'},
{'Title': 'The Good Mother'},
{'Title': 'Fire on the Amazon'},
{'Title': 'Bang'},
{'Title': 'How to Make a Monster'},
{'Title': 'Hammers Over the Anvil'},
{'Title': 'The Nursemaid Who Disappeared'},
{'Title': 'Third Person'},
{'Title': 'You Were Never Really Here'},
{'Title': 'Shadow Dancing'},
{'Title': 'Remembrance'},
{'Title': 'Small Town Murder Songs'},
{'Title': 'Eadweard'},
{'Title': 'Caught in the Web'},
{'Title': 'Bounty Hunters'},
{'Title': 'Fulltime Killer'},
{'Title': 'Amar'},
{'Title': 'SMS'},
{'Title': 'JAKQ Dengeki Tai'},
{'Title': 'Gekijō-ban Tiger & Bunny -The Beginning'}]Code:
What Next?
- BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
- Training PRM (Personalized Re-ranking Model) using User Data
- Tacking Cold Start Problem by enhancing user geo and meta features
- Graph: Learning from a user or item’s neighbors
- Item2Item Similarity
- RFM based Customer segmentation for targeted recommendation and branding.