
Scraping News and Creating a Word Cloud in Python
A simple step-by-step tutorial in Python on creating word clouds from news topics.

Word clouds are a great way of quickly visualising the content of a website. It is also an easy way of summing up sentiment. Suppose you quickly wanted to gauge the current news sentiment of Bitcoin, or of the stock market — you can do this easily by scraping Google news search results for the specifed topic, and running a word cloud on your results.
You don’t need to be a great programmer to do this. This tutorial will teach you how.
We’re going to do two basic tasks in Python:
- Scrape text data from a Google news search
- Analyse this text data to create a word cloud
Step 0. Import libraries
First we’re going to import some Python libraries.
import requests
import urllib.request
import time
import spacy
from bs4 import BeautifulSoup
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as pltIf you don’t have wordcloud or spaCy installed, please use:
pip install wordcloudpip3 install https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-2.2.0/en_core_web_sm-2.2.0.tar.gzStep 1. Scrape text data from Google news search
First we need to get a handle on Google search parameters so that you can build your url. There is a good blog post that summarises most of Google’s search parameters:
All Google search urls start with:
https://www.google.com/search?And then you append your search parameters after it. Here are the key ones we will need:
q — this is the query topic, i.e., q=bitcoin if you’re searching for Bitcoin news
hl — the interface language, i.e., hl=en for English
tbm — to be matched, here we need tbm=nws to search for news items. There’s a whole lot of other things one can match for instance, app for applications, blg for blogs, bks for books, isch for images, plcs for places, vid for videos, shop for shopping and rcp for recipes.
num — controls the number of results shown. If you only want 10 results shown, num=10
OK. Now lets’ put all this together. If you wanted to find the latest 100 news articles on Bitcoin, you would:
topic="bitcoin"
numResults=100
url ="https://www.google.com/search?q="+topic+"&tbm=nws&hl=en&num="+str(numResults)Now we can scrape the results
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')Google search results gives us a title, a link and some basic descriptions. We will be using the basic descriptions to build our word cloud for this tutorial. Of course, you can use the links to scrape the corpus of news articles to build a more complete word cloud. But here, for simplicity, we will use the basic descriptors.
results = soup.find_all(‘div’, attrs = {‘class’: ‘ZINbbc’})
descriptions = []
for result in results:
try:
description = result.find(‘div’, attrs={‘class’:’s3v9rd’}).get_text()
if description != ‘’:
descriptions.append(description)
except:
continueYou should get a list that looks something like this
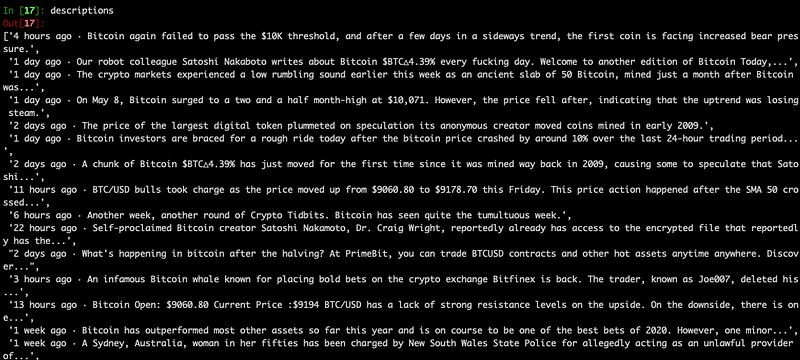
To flatten this to a string use…
text = ‘’.join(descriptions)
Step 2. Analyse text to create a word cloud
We need to clean the data before we generate a word cloud.
- Convert all words to lower case
- Identify all adjectives … you can add nouns, pronouns into the mix if you prefer
- Remove all the stop words. These are words such as “a”, “the”, “we” …etc. They are frequent and does not hold any use information. They are simply the glue that holds a language together.
First we load the language model from spaCy, and parse the text string int.
sp = spacy.load('en_core_web_sm')
doc = sp(text)We can check words and word types immediately — which is very cool!
for word in doc:
print(word.text, word.pos_, word.dep_)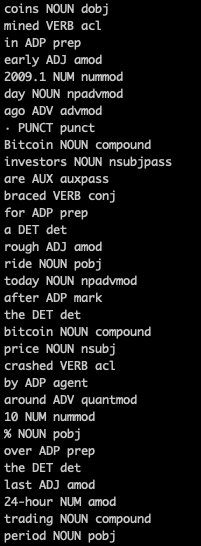
If you have issues with the en_core_web_sm model, try re-downloading it. I initially had some issues.
python -m spacy download en_core_web_smNext we only choose only adjectives, and force everything to lower case.
newText =’’
for word in doc:
if word.pos_ in [‘ADJ’]:
newText = “ “.join((newText, word.text.lower()))Now we’re ready to input it into the wordcloud!
wordcloud = WordCloud(stopwords=STOPWORDS).generate(newText)
plt.imshow(wordcloud, interpolation=’bilinear’)
plt.axis(“off”)
plt.show()
If we included nouns to the mix…
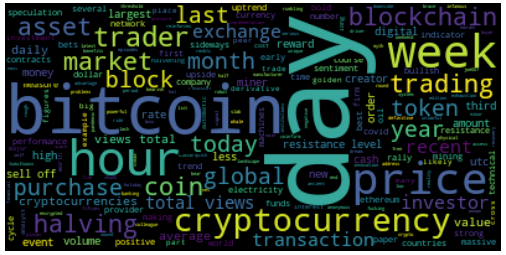
Putting it all together
In conclusion, we can pick any topic we want, and build a news-based word cloud on it.
import requests
import urllib.request
import time
import spacy
from bs4 import BeautifulSoup
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plttopic="bitcoin"
numResults=100url ="https://www.google.com/search?q="+topic+"&tbm=nws&hl=en&num="+str(numResults)
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')results = soup.find_all('div', attrs = {'class': 'ZINbbc'})
descriptions = []
for result in results:
try:
description = result.find('div', attrs={'class':'s3v9rd'}).get_text()
if description != '':
descriptions.append(description)
except:
continuetext = ''.join(descriptions)sp = spacy.load('en_core_web_sm')
doc = sp(text)newText =''
for word in doc:
if word.pos_ in ['ADJ', 'NOUN']:
newText = " ".join((newText, word.text.lower()))wordcloud = WordCloud(stopwords=STOPWORDS).generate(newText)plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()