Score-based generative models
disclaimer: most of the context in this blog is taken from this paper: score-based generative models through stochastic differential equations (https://arxiv.org/pdf/2011.13456.pdf)
In this blog, we try to give a high-level introduction to the score-based generative models by collecting models from various papers.
The score function is the gradient of the log probability density with respect to data:

Score-based generative models directly learn the gradient of the distribution instead of the density functions themselves. Such gradient information can be utilized in reverse by stochastic sampling to generate diverse samples.
Generative modeling in general is generating data from the noise (except those that can model the data distribution which allows one to sample (for instance RNN, but even RNN starts the first token from the noise, do we have other models that do not utilize any prior distribution to get samples?).
The paper mentioned above follows this idea:
Using a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise.
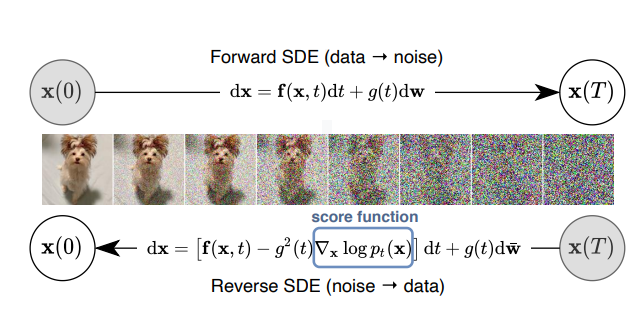
Transforming data to a simple noise distribution can be accomplished with a continuous-time SDE. This SDE can be reversed if we know the score of the distribution at each intermediate time step, ∇_xlog P_t(x). Solving reverse-time SDE yields a score-based generative model.
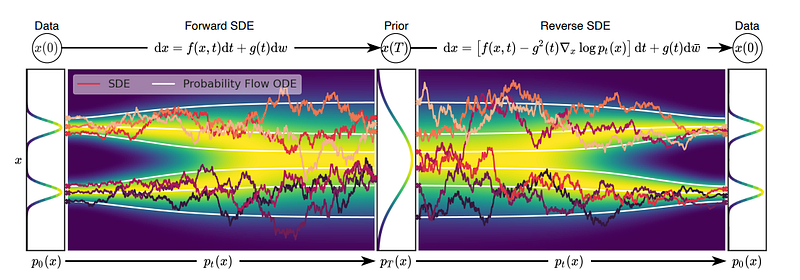
The Forward path uses SDE to smoothly transform a complex data distribution to a known prior distribution by slowly injecting noise, going from x(0) to x(T) where x(0) corresponds to a data point and x(T) is pure noise that corresponds to some prior distribution. w is the standard Wiener process (a.k.a., Brownian motion), f(., t) is a vector-valued function called the drift coefficient of x(t), and g(t)) is a scalar function known as the diffusion coefficient of x(t). There are various ways of designing such SDE (as shown in the equation above) so that it diffuses the data distribution into a fixed prior distribution.
The backward path uses reverse-time SDE to transform the prior distribution into the data distribution; going from x(T) back to x(0). The reverse of a diffusion process is also a diffusion process, running backward in time and given by the reverse-time SDE:
In this kind of model, instead of perturbing data with a finite number of noise distributions, a continuum of distributions that evolve over time according to a diffusion process is utilized. This process progressively diffuses a data point into random noise and is given by a prescribed SDE that does not depend on the data and has no trainable parameters. We can smoothly mold random noise into data for sample generation by reversing this process. Crucially, this reverse process satisfies a reverse-time SDE (Anderson, 1982), which can be derived from the forward SDE given the score of the marginal probability densities as a function of time. We can therefore approximate the reverse-time SDE by training a time-dependent neural network to estimate the scores, and then produce samples using numerical SDE solvers
Reverse-time SDE depends only on the time-dependent gradient field (score) of the perturbed data distribution.
The existing score-based models can be efficiently trained only if the forward/corruption process can be computed in closed form. (why?)
Score-based generative modeling and probabilistic diffusion modeling
Two successful classes of probabilistic generative models involve sequentially corrupting training data with slowly increasing noise and then learning to reverse this corruption in order to form a generative model of the data.
- Score matching with Langevin dynamics (SMLD) (Song & Ermon, 2019) estimates the score (i.e., the gradient of the log probability density with respect to data) at each noise scale, and then uses Langevin dynamics to sample from a sequence of decreasing noise scales during generation.
- Denoising diffusion probabilistic modeling (DDPM) (Sohl-Dickstein et al., 2015; Ho et al., 2020) trains a sequence of probabilistic models to reverse each step of the noise corruption, using knowledge of the functional form of the reverse distributions to make training tractable. For continuous state spaces, the DDPM training objective implicitly computes scores at each noise scale. We, therefore, refer to these two model classes together as score-based generative models.
Denoising score matching with Langevin dynamics (SMLD)
As we mention, there is two-step in score-based generative models: the forward path where we add noise to the data and gradually transform it to a prior distribution, then the backward path which denoises the data and gets the original samples back.
For the forward path: the SMLD model assumes a perturbational kernel:
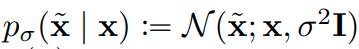
where x is the real samples, x tilde is the perturbed version of the samples and sigma is the size of the noise that is added to the x. Then we have the perturbed data distribution given by:
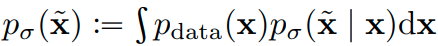
By setting the sigma values, we can get the perturbed data (for a given x, add gaussian noise with the given sigma). The next step is to obtain the conditional score network (NCSN) which approximates the score function that we will be needed to generate samples later on (in the backward path).
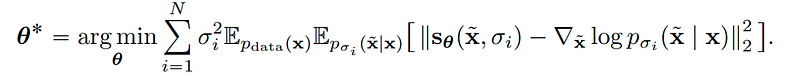
Here we can easily compute the score function for the conditional distribution of the perturbed data, we will fit a neural network denoted by a conditional score network whose output would be set to this conditional score. It is said that given sufficient data and model capacity, the optimal score-based model:
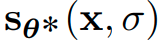
matches the score function (why not the conditional score?):
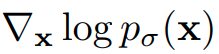
almost everywhere for the sigma_i, i=1,…N.
For the backward path (generation, sampling), the SMLD model proposes to run M steps of Langevin MCMC to get a sample for each p_{sigma_i}(x).
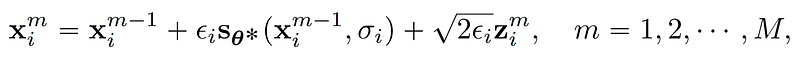
where epsilon_i is the step size and z_i^m is a sample from the standard normal distribution. This sampling process is repeated for i = N, N-1,…1 in turn with
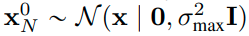
which means, we start from x⁰_N which is purely noise sampled with the biggest sigma and we apply the process (Langevin MCMC) for M step which gives us x^M_{N}, then we set x⁰_{N-1}= x^M_{N} and reapply the process again on x⁰_{N-1}. Finally, x^M_1 becomes an exact sample from p_{sigma_min}(x). Note that there are two recurrent iterations, one with respect to m(MCMC sampling) and the other one with respect to i (different sigma). Basically, we first sample a sigma (starting from the maximum) and apply the MCMC for M step (iterate over m) and then repeat it again with a different sigma.
Langevin dynamics is a concept from physics, developed for statistically modeling molecular systems. Combined with stochastic gradient descent, stochastic gradient Langevin dynamics (Welling & Teh 2011) can produce samples from a probability density p(x) using only the gradients ∇_xlogp(x) in a Markov chain of updates. Compared to standard SGD, stochastic gradient Langevin dynamics injects Gaussian noise into the parameter updates to avoid collapses into local minima.
So basically data is generated from a repetitive process of adding Gaussian noise to the previously generated sample (initialized by Gaussian noise too) plus scaled conditional score (gradient of the conditional distribution of the perturbed data given the input samples) and plus scaled Gaussian noise. This is the denoising process.
DENOISING DIFFUSION PROBABILISTIC MODELS (DDPM)
Using score-based generative modeling, we can accurately estimate the scores with the neural networks and use numerical SDE solvers to generate samples
(to be continued….)
references:
- Score-based generative models through stochastic differential equations
- Lil’Log https://lilianweng.github.io/posts/2021-07-11-diffusion-models/





