
Scale AI TransformX Highlights
My company held an AI conference called TransformX last week, and the contents were really good, so I wanted to share them with my readers. IMO, it was the best AI conference this year (other than academic ones) in terms of various topics, interesting speakers, accessibility, relevancy, etc. I might be biased, of course :).
I think Xavier’s tweet summarizes it well.
I don’t know how Alex (and the team) can pull this together either. I think a massive team effort went in there. They got so many famous speakers while each talk was very high quality.
Here are a few highlights from the TrasnformX that happened on October 6th, 7th, 2021.
ML at Waymo: Building a Scalable Autonomous Driving Stack — Drago Anguelov
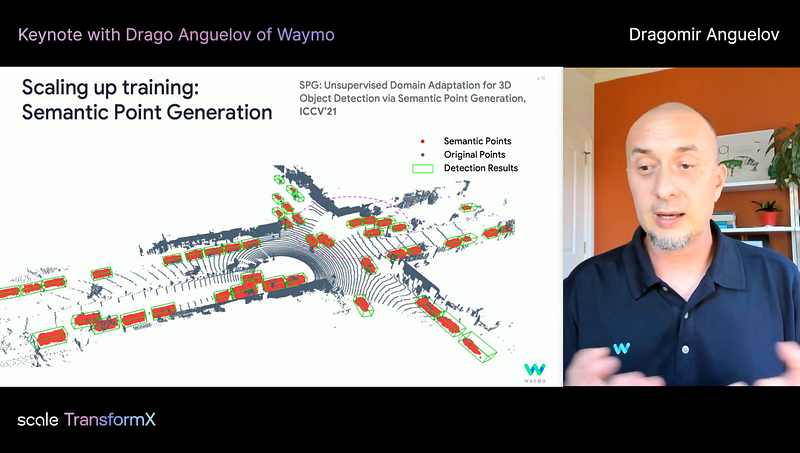
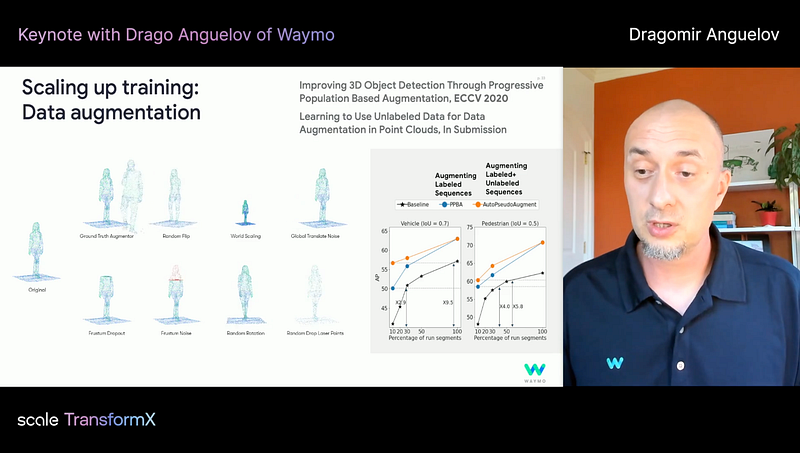


Drago presented Waymo’s progress towards building an AV stack. If you are into self-driving, you will find his talk informative. He talked about Waymo’s service car (it’s the world’s first commercial ride-hailing service open to the public), different approaches to augment 3D data, and the map — how Waymo uses a map, as as a prior, or as a safety feature, not as an immutable truth. Through the maps, fleets can share their observations with each other.
ML at Scale: How Scale Uses ML to Improve Data Quality and Labeler Productivity — Aerin Kim
This is my talk 😊. I presented in one of the break-out sessions. I tried to make my session as applicable as possible for the audience. If you like my writing style, I think you will like this presentation as well.
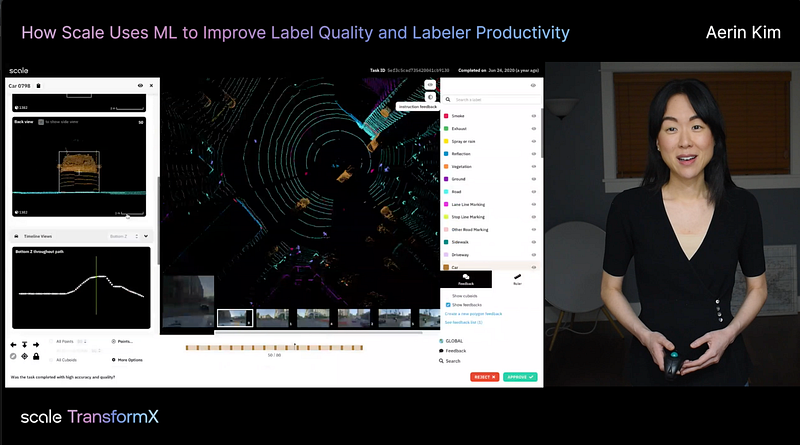

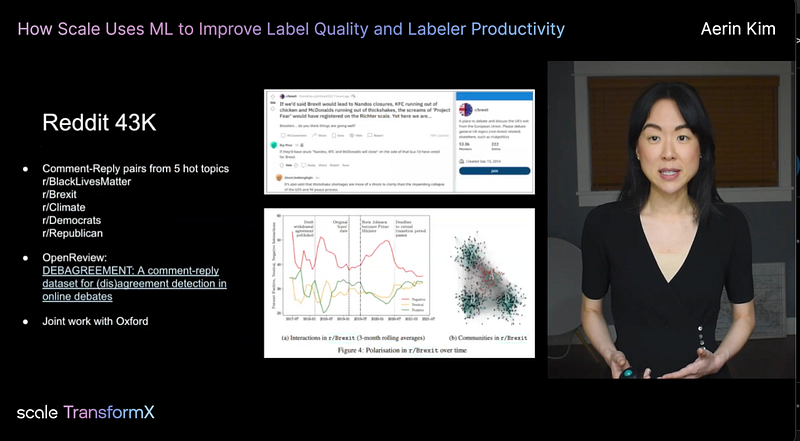
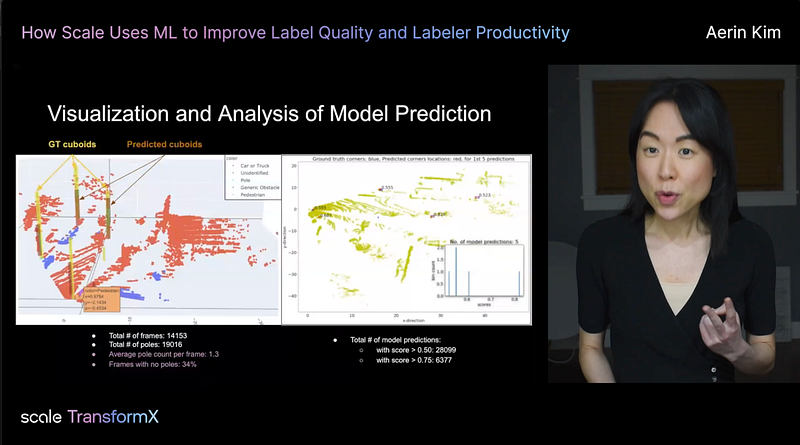
In this talk, I demonstrated our 3D annotation platform and introduced ML linters (e.g., a pole detector) that we built using LIDAR data. The talk will be especially helpful if you use machine learning (detection, semantic segmentation, etc.) to improve your training data quality. I also talked about our recent work submitted to the @Neurips dataset track.
Building Better Reinforcement Learning With World Models & Self-Attention Methods — Hardmaru
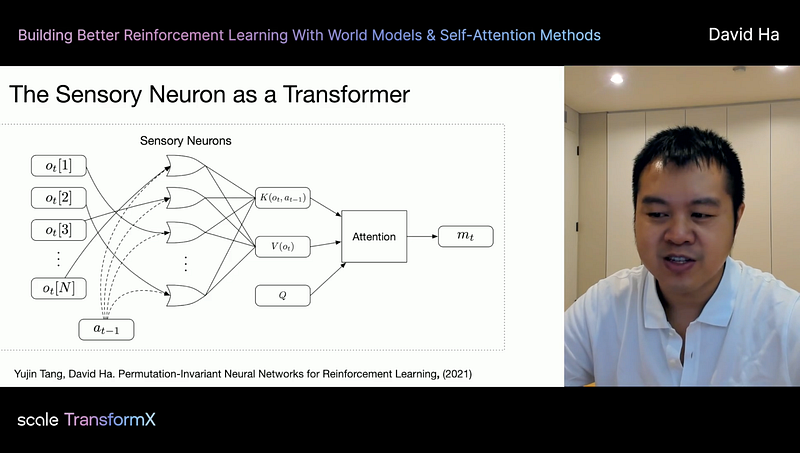

David Ha, Research Scientist at Google Brain, presented how he’s building “world models” (an abstract representation of the agent’s environment. can be temporal or spatial.) and using self-attention as a constraining mechanism in Reinforcement Learning. He shared his recent experiment results — how the agent can achieve better generalization by attending to more informative patches of the data and not focusing on distracting or confusing information.
What’s Next for AI Systems & Language Models — Ilya Sutskever

Ilya and Alex sat down and discussed a variety of topics.
Some interesting remarks from Ilya:
“Traditionally because of the roots of the field of machine learning, because the field has been fundamentally academic, and fundamentally concerned with discovering new methods, and less with the development of very big and powerful systems, the mindset has been someone builds, someone creates a fixed benchmark. So a data set of a certain shape of certain characteristics. And then different people can compare their methods on this data set. But what it does is that it forces everyone to work with a fixed data set.”
…
(He was talking about embodiment) here is a distinction between what people learn, and what our artificial neural networks learn, because people see and they walk around, they do all those different things. Whereas our neural networks, the text ones are only trained on text. if you bring the training data to be more similar to that of people, that maybe we’ll learn something more similar to that of people as well.
…
The reason it was important for that framework to have a fixed data set is so that you could compare which method is better. And I think that really did lead to a blind spot where very many researchers were working very hard on this pretty difficult area of can we improve the model more and more and more, while leaving with a very large improvements that are possible by simply saying, “Hey, let’s get much more data on the table.”
The Future of AV Sensors — Austin Russell

If you are interested in the depth data (LIDAR) and voting against Tesla’s idea — image-only autonomous driving is safe enough, you will like this talk.
Even the lidar skeptic Elon Musk is reportedly testing Luminar’s LIDAR.
Alex and Austin discussed relevant topics such as — what does the choice of sensor technologies mean for downstream perception, prediction, and planning algorithms? What do we need from today’s hardware or software to enable L4/L5 urban self-driving autonomy? What is the most critical strategic decision that CEOs of companies in this space should be thinking about?, etc.
This highlight is quite arbitrary because I only went over the talks that I watched. Other talks that I haven’t watched yet also look great to me. I plan to consume them over the next few weeks. If you desire to explore new perspectives in AI, I think transformX is one of the best resources that you can watch now.
All recordings: https://exchange.scale.com/public/videos




