
Sampling — The Unsung Hero of Data Science
Sampling: Methodologies, Implementation and Comparison

Sampling is widely adopted in various businesses to audit and measure change — I know that sounds simple but it is more complicated than it seems. I see a lot of focus on Machine Learning in today’s Data Science work but without a well-designed and representative sample, all that effort might not bear fruit. For example, after training a brand new Machine Learning model variant, we need a representative sample to be able to determine the level of improvement (or degradation), compared to the previous version of the model — and just collecting a random sample is not always the right solution. A poorly-designed sample that does not represent the population well, can lead to wrong conclusions and business decisions.
In this post I will introduce and compare various sampling methodologies, which hopefully can be used as a reference for future sampling strategy designs.
Let’s get started!
What is Sampling?
Sampling is the process of collecting (or selecting) a subset of observations from a larger set. The collected smaller subset is called a “sample” and the larger set from which the sample was collected is called the “population”. The sample is used to make inferences about the characteristics (or the properties) of the population. But why do need a sample? Why not just analyze the population itself?
There are various reasons but some of the most common ones are:
- Cost: In some cases, for example when the population is very large, it is not cost-effective to analyze the entire population. In other words, sample enables us to make inferences from the population by analyzing a much smaller subset of the population, which is the sample
- Time: This is similar to cost. If the population is very large, it might not be feasible to spend the time to analyze the entire population. For example, U.S. Census makes inferences about the population of the U.S., based on a sample, since it is not cost and time efficient (among other reasons) to analyze the entire population of the U.S.
- Efficiency: A well-designed and collected sample theoretically provides a good representation of the entire population. In other words, inferences made from the sample, which is smaller than population, can be extended to the entire population. This makes the analysis much more efficient, compared to analyzing the entire population
Sampling Methodologies
Selection of the sampling methodology depends on the research and/or business questions and the type of population being studied. In other words, we first need to understand what we would like to measure and based on that we can select an appropriate sampling methodology to ensure the resulting sample represents the population in the study, given the existing limitations (e.g. time, cost, etc.).
Sampling methodologies can be broken down into two groups:
- Probabilistic Sampling: Where each member of the population has a non-zero probability of being selected (for example through random sampling, etc.)
- Non-Probabilistic Sampling: Where probability of selecting each member of the population is either zero or unknown and sample collection is primarily driven by convenience or availability. This will be easier to understand as we go through each group
Let’s look at each of these two categories more closely.
1. Probabilistic Sampling
1.1. Simple Random Sampling (SRS)
Every member of the population has an equal chance of being selected for the sample, which is also known as Random Sampling.
Collecting a SRS with the size k from a given population in Python can be as simple as:
# Import libraries
import random
# Collect the sample
sample = random.sample(population, k)1.2. Systematic Sampling
Where every kth member of the population is collected (starting from a random point in the population), until the desired sample size is met. Collecting a sample of size n from every kth member of a given population in Python is as follows:
# Collect the sample
sample = population[k-1::n]1.3. Stratified Sampling:
Population is divided into smaller groups or strata, based on one of the properties of the population. Then a sample is collected from each stratum, size of which is proportional to the weight of that stratum relative to the overall population. For example, if 55% of the population is female and 45% is male (and assuming female vs male is the selected stratification strategy), in order to collect a sample size of 100, 55 samples will be collected from the female stratum (since that stratum accounts for 55% of the population), while the remaining 45 will be collected from the male stratum.
Below is a Python implementation of a Stratified Sampling:
# Import libraries
from sklearn.utils import resample
# Create an empty list to store the stratified samples
stratified_samples = []
# Collect the sample
for label, stratum in strata.items():
# Collect the subset of sample for that lable/stratum
sample = resample(stratum, n_samples=sample_size)
# Add the subset to the overall sample
stratified_samples.append(sample)Note that strata above is a dictionary with label as its key and population as its value.
1.4. Cluster Sampling:
Population is divided into clusters and then a random sample of clusters are collected. On the surface Cluster and Stratified Sampling seem similar so let me explain the distinction. In Stratified Sampling, we collect a random sample from each stratum (similar to the example explained above). But in Cluster Sampling, a population is broken down into “n” clusters and then “m” clusters of them are randomly selected. When a cluster is selected, entire observations within that cluster are collected (unlike Stratified Sampling where a random sample of each stratum was collected).
Below is a Python implementation of Cluster Sampling:
# Import libraries
import pandas as pd
import random
# Create a list of clusters from the population dataframe
total_clusters = population['cluster'].unique()
# Select m random clusters from clusters_list
selected_clusters = random.sample(total_clusters, m)
# Select rows of the population dataframe with the randomly-selected clusters
sample = population[population['cluster'].isin(selected_clusters)]1.5. Multi-Stage Sampling
As the name suggests, this is sampling at multiple stages and for each stage, any of the above methodologies could be used and the resulting sample is used as the population for the next stage. For example, we may start with a population of 10,000 observations and collect a Simple Random Sample of 2,000 in the first stage. Then the 2,000 collected observations become the population for the second stage where we can collect another sample using a different methodology, such as any of the above 1 through 4 methodologies.
Sometimes the probabilistic sampling methodologies from 2 to 5 above are referred to as “Complex Sampling”, as opposed to the very first one which is a relatively simpler type of sampling.
2. Non-Probabilistic Sampling
2.1. Convenience Sampling
Where those that are easily accessible or available are collected as the sample. For example, let’s say a student is conducting a research at school and is looking for 100 volunteers to fill out a questionnaire. Then the student might just select the 100 students who are readily available to fill out the questionnaire at that point in time, which would result in a Convenience Sampling of the population of students in that school.
2.2. Snowball Sampling
Some times it is not easy to identify individuals who belong to the targeted population. In such cases, the researchers start with those members that can be identified and then ask those individuals to refer other members of that population (which is like a snowball effect).
2.3. Quota Sampling
A non-probabilistic sampling method Where researchers decide on how many samples to collect and will stop once they reach the desired number.
Sampling Methodology Comparison
I have created a comparison of various sampling methodologies discussed in this post in the table below. I have tried to remove my own bias when making this table but the topic is highly subjective overall and the levels can change based on specific use cases.
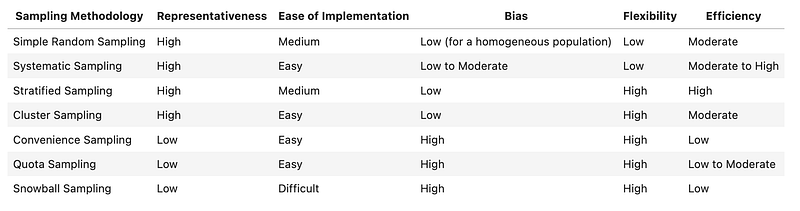
Here are the definition of each column:
- Representativeness: How closely the sample is expected to present the properties of the population
- Ease of Implementation: How easy it is to implement the sampling methodology
- Bias: How much sample might deviate from the population it is representing
- Flexibility: How flexible the sampling methodology is for different scenarios
- Efficiency: How accurately the sample estimates the properties of the population it represents
Conclusion
In this post we reviewed the importance of Sampling and the value of having a well-designed sample, based on the research and business needs. Then we reviewed various probabilistic and non-probabilistic sampling methodologies and compared them to get a better understanding of sampling options available to us.
Thanks for Reading!
If you found this post helpful, please follow me on Medium and subscribe to receive my latest posts!




