
RoPE: A Detailed Guide to Rotary Position Embedding in Modern LLMs
Rotary Position Embedding (RoPE) has been widely applied in recent large language models (LLMs) to encode positional information, including Meta’s LLaMA and Google’s PaLM.
Position is crucial in sequential models, and position embedding plays a vital role in transformer-based architectures. RoPE, the rotary position embedding, use a clever method to incorporate both relative and absolute positional information.
Rethink the Attention Product
Before introducing RoPE, let’s recap the basics of the attention mechanism. Attention focuses on pair-wise relationships: there’s a query vector q from one token and a key vector k from another. We obtain the attention score by taking the inner product of q and k, and this inner product is key to how position embeddings function.
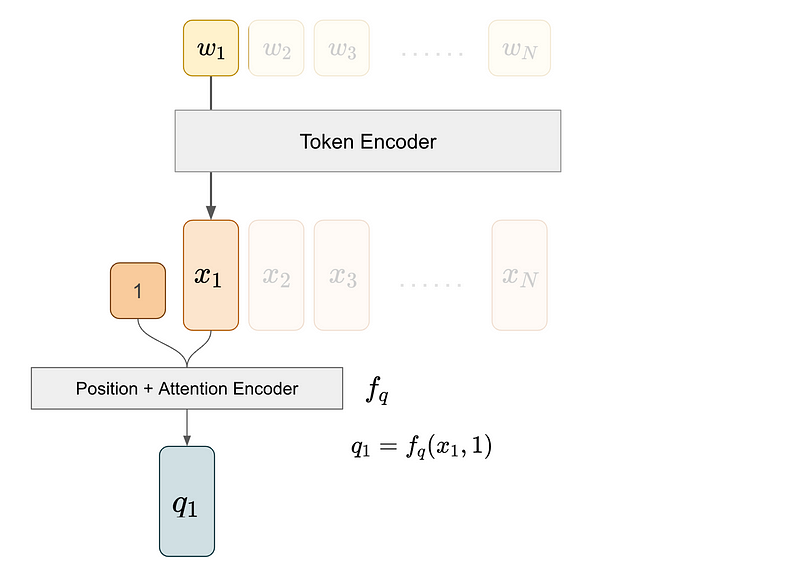
For example, to get the attention score for the pair (1, 3), we get the query vector from token 1 and the key vector from token 3.
We obtain the query vector q1 by first extracting its token embedding through the token encoder. Then, we feed this embedding and its positional information into the position+attention encoder, which integrates position information and projects the result to produce the key vector.
We perform a similar process for the third token to obtain k3, the key vector corresponding to token 3.
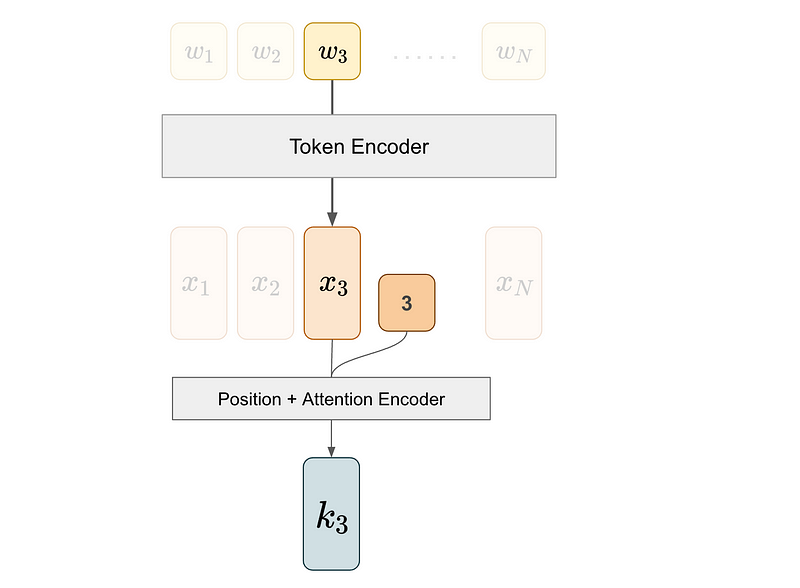
Finally, we take the inner product of q1 and k3 to determine the attention score for (1, 3). In the equation below, angle brackets <> denote the inner product, x represents the token embedding, and f is the attention+position encoder.

The authors then reflect on this formulation and realize that in this setup, the relative positional information is encoded before the inner product — meaning it’s inherently tied to the token embedding.
They ask themselves: “Is there another way to encode relative positional information only when we need the attention score — i.e., at the moment we perform the q,k inner product?” Or equivalently, the q,k inner product is equivalent to another function g that takes only the token embeddings and their positions as input?

This is where the RoPE position embedding comes into play.
Intuition of RoPE: A 2D Simple Case
The authors begin by considering a simple 2D case, where token embeddings and attention vectors (query, key) all reside in 2D space. For convenience, these 2D vectors can also be represented using a complex number (as shown in the figure).

The counterclockwise rotation matrix can be expressed both in a matrix form and in an exponential form.

Similarly, we can represent the projection from token embeddings to key or query vectors using 2D matrices.

The authors discover that one possible solution (i.e., the transformations of f and g) that satisfies the following condition:

has the following form:

or graphically:
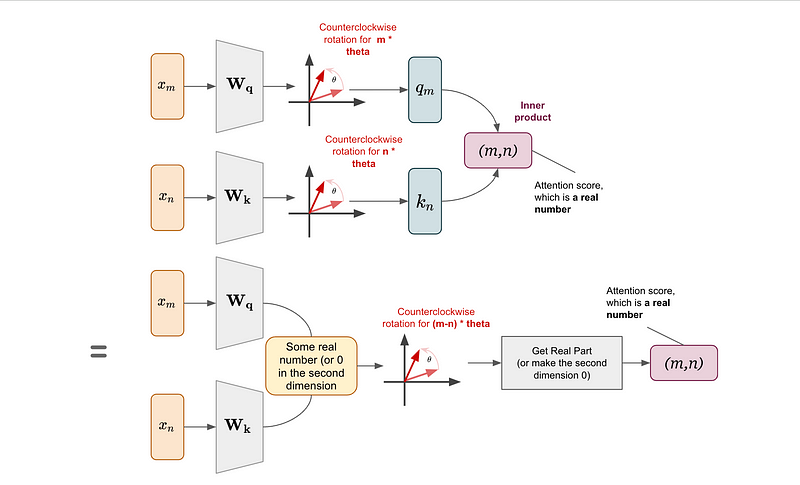
In simple terms, this means that after the transformation, we can either rotate first and then perform the inner product, or we can perform the inner product first and then rotate, and take the real part. In the second approach, we only need (m–n) for the rotation, which signifies that this is a type of relative position embedding.
This is the intuition behind Rotary Position Embedding (RoPE): simply rotate the affine-transformed word embedding vector by an angle proportional to its position index.
The General Form of RoPE
To generalize into the. d dimentional case, let’s consider how rotation matrix would look like. The authors suppose that d is an even number, and thus divide d into d/2 blocks. Each block performs a 2D rotation respectively:
To generalize this into the d-dimensional case, consider how the rotation matrix would look like. The authors fisrt assume that d is an even number, and thus can be divided into d/2 blocks. Each block performs a 2D rotation independently:
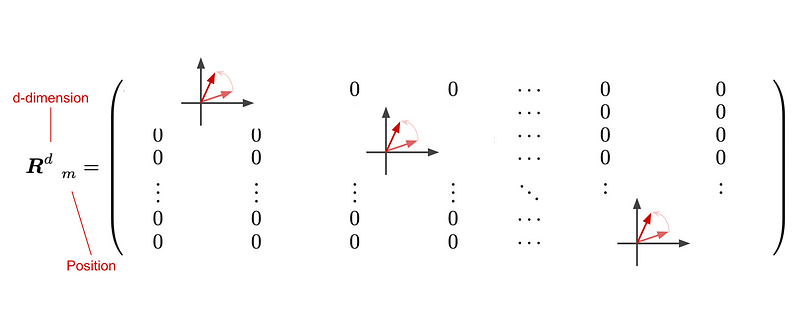
Now, the question is: how much do we rotate (in each block? Recalling how sinusoidal position embeddings are applied in transformers, the angle parameter they use is:
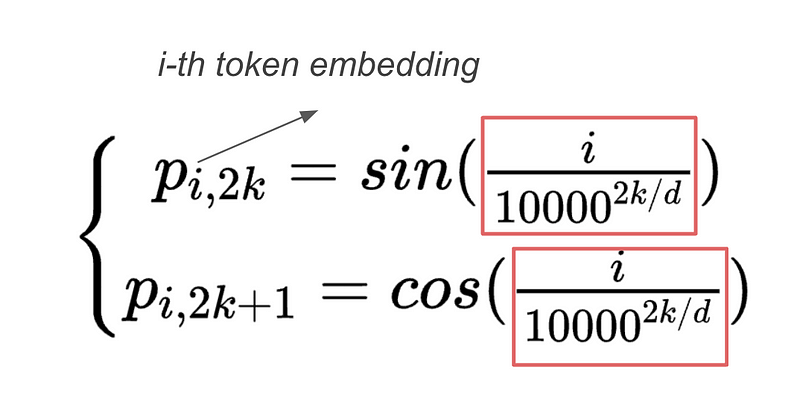
Following this implementation, the authors adopt a similar parameter:
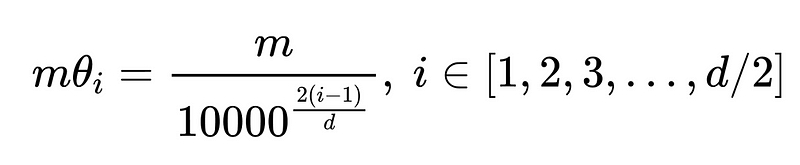
Here, i represents the i-th sub-block, and m·θ determines the rotation for the corresponding sub-block. Thus, the general form of the rotation matrix is:

And the overall transformation applied to a token embedding is:
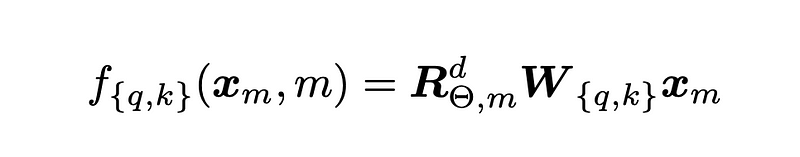
where W is the d-dimensional affine transformation for either the query or the key vector, and R is the rotation matrix mentioned above. Below is a graphical explanation from the original paper.
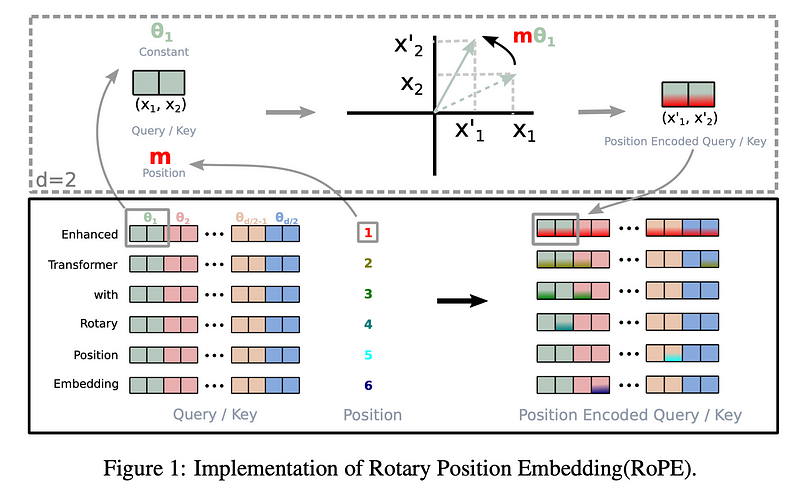
Note that the rotation matrix R is quite sparse, hence direct multiplication is not efficient. Instead, a more computationally efficient realization of the R multiplication looks like this:
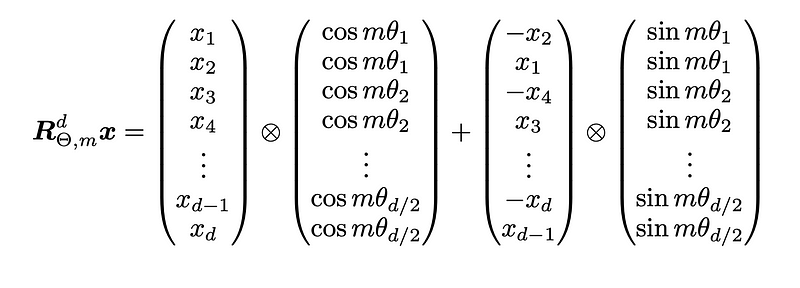
Here, the operator with a circle and a cross (⊗) denotes the element-wise (Hadamard) product.
How RoPE Improves Language Models
In the original RoPE paper, the authors validate its performance by replacing BERT’s original sinusoidal position encoding with RoPE during pre-training, resulting in a model they call ReFormer. During pre-training, the masked language modeling (MLM) loss shows that BERT with RoPE converges more quickly.
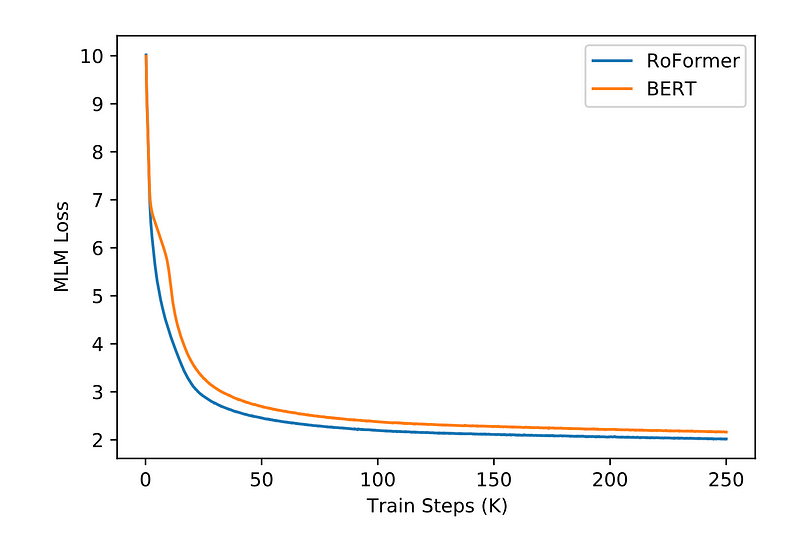
After pretraining, the authors fine-tune the weights of the pre-trained RoFormer on various GLUE tasks (NLP tasks) to assess its capabilities for downstream NLP tasks, and RoFormer outperforms BERT on 3 out of the 6 datasets.






