
Root Cause Analysis
using Deep Learning
In this tutorial we will use artificial neural network to solve one of the common problem that we call Root Cause Analysis. The use case to solve relates to root cause analysis of problems found in a data center.

We have a data center that runs a number of software services. Service failures happen sometimes, so the data center team have to quickly troubleshoot and identify the root cause. The team wants to create a model that can predict root causes reported by customers based on the telemetry generated and errors noticed. They already have a system monitoring tool that tracks CPU, memory, and application latency characteristics of their servers. In addition, they also track errors reported by their applications.
Can we use this information to predict root causes of the issues noticed?
Problem statement
Using features about CPU loads, memory load, network delays, and three types of errors observed, we want to build a deep learning model to predict the root cause of the error.
The available data set has available has one record for each incident to indicate if any of the load issues or errors were noticed when the problem happened.
You can download the data set that we use on this tutorial using the following link.
Each record in the file has a unique identifier ID that represents the incident. There are seven feature variables, namely CPU_LOAD, MEMORY_LEAK_LOAD, network DELAY, ERROR_1000, ERROR_1001, ERROR_1002, and ERROR_1003. Each of feature is a either a 1 or 0.
The target variable is ROOT_CAUSE. It has three classes, MEMORY_LEAK, NETWORK_DELAY, or DATABASE_ISSUE.
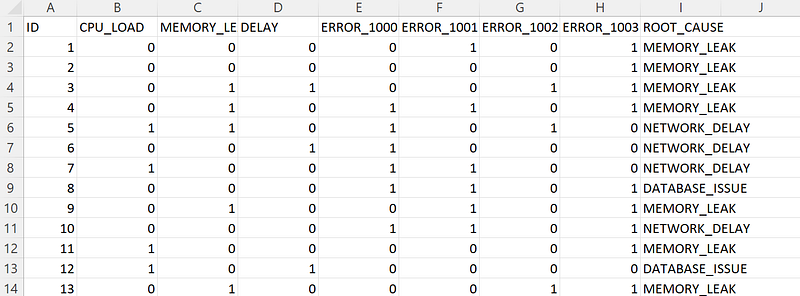
We want to build a model to predict the root cause based on the other values provided.
Here you can find the list of steps to follow in order to build the model and predict using new data.
Preprocess data
- Load the data into a pandas data frame and print the content;
import pandas as pd
import os
import tensorflow as tf
#Load the data file into a Pandas Dataframe
symptom_data = pd.read_csv("root_cause_analysis.csv")
#Explore the data loaded
print(symptom_data.dtypes)
symptom_data.head()- Use the label encoder to transform the target variable into numeric values;
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
label_encoder = preprocessing.LabelEncoder()
symptom_data['ROOT_CAUSE'] = label_encoder.fit_transform(
symptom_data['ROOT_CAUSE'])
Given that all the values for the feature variables are either one or zero, it is already normalized so we don’t have to do any further processing.
- Convert the data to a Numpy array of float numbers;
#Convert Pandas DataFrame to a numpy vector
np_symptom = symptom_data.to_numpy().astype(float)- Split the features variables from the target variable;
#Extract the feature variables (X)
X_data = np_symptom[:,1:8]
#Extract the target variable (Y), conver to one-hot-encodign
Y_data=np_symptom[:,8]- Use one hot encoding to encode the target variable;
Y_data = tf.keras.utils.to_categorical(Y_data,3)
- Split the data into training and test sets;
#Split training and test data
X_train,X_test,Y_train,Y_test = train_test_split( X_data, Y_data, test_size=0.10)
print("Shape of feature variables :", X_train.shape)
print("Shape of target variable :",Y_train.shape)Now the data ready for deep learning.
Build the model
Now we proceed to build a model for root cause analysis.
- Set the EPOCHS, BATCH SIZE, the number of nodes on the hidden layer N_HIDDEN, and the part of data to be used on validation VALIDATION_SPLIT;
from tensorflow import keras
from tensorflow.keras import optimizers
from tensorflow.keras.regularizers import l2
#Setup Training Parameters
EPOCHS=20
BATCH_SIZE=64
VERBOSE=1
OUTPUT_CLASSES=len(label_encoder.classes_)
N_HIDDEN=128
VALIDATION_SPLIT=0.2- Use a model with two hidden layers of and an output layer;
#Create a Keras sequential model
model = tf.keras.models.Sequential()
#Add a Dense Layer
model.add(keras.layers.Dense(N_HIDDEN,
input_shape=(7,),
name='Dense-Layer-1',
activation='relu'))
#Add a second dense layer
model.add(keras.layers.Dense(N_HIDDEN,
name='Dense-Layer-2',
activation='relu'))
#Add a softmax layer for categorial prediction
model.add(keras.layers.Dense(OUTPUT_CLASSES,
name='Final',
activation='softmax'))
#Compile the model
model.compile(
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()- Build the model, then fit the training data;
#Build the model
model.fit(X_train,
Y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=VERBOSE,
validation_split=VALIDATION_SPLIT)- Evaluate the model against the test data;
#Evaluate the model against the test dataset and print results
print("\nEvaluation against Test Dataset :\n------------------------------------")
model.evaluate(X_test,Y_test)The overall accuracy during training is around 86% and the accuracy against test data is 76%
If you wish to improve the model you can continue to increase the number of layers or the number of nodes.
Make predictions
Now that we built the model we can proceed to predict root causes. We will first predict the root cause for a single input . So we will:
- Set the values for the seven feature variables;
#Pass individual flags to Predict the root cause
import numpy as np
CPU_LOAD=1
MEMORY_LOAD=0
DELAY=0
ERROR_1000=0
ERROR_1001=1
ERROR_1002=1
ERROR_1003=0- Use the model to predict the probabilities for the various classes and use the argmax function to extract the position with the highest probability;
prediction=np.argmax(model.predict(
[[CPU_LOAD,MEMORY_LOAD,DELAY,
ERROR_1000,ERROR_1001,ERROR_1002,ERROR_1003]]), axis=1 )- Use the label and coder to retrieve the string class value for the root cause;
print(label_encoder.inverse_transform(prediction))The prediction results shows that the cause is a database issue.
We can also perform a batch prediction in a similar fashion for multiple incidents in one shot, as shown here
#Predicting as a Batch
print(label_encoder.inverse_transform(np.argmax(
model.predict([[1,0,0,0,1,1,0],
[0,1,1,1,0,0,0],
[1,1,0,1,1,0,1],
[0,0,0,0,0,1,0],
[1,0,1,0,1,1,1]]), axis=1 )))



