
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
New Technique Bypasses Need for Human Feedback in Reinforcement Learning
A new technique called RLAIF (Reinforcement Learning from AI Feedback) enables training reinforcement learning (RL) models without relying on human-labelled training data, according to a paper from researchers at Google. RLAIF instead uses preferences generated by a large language model (LLM) to train the RL model.
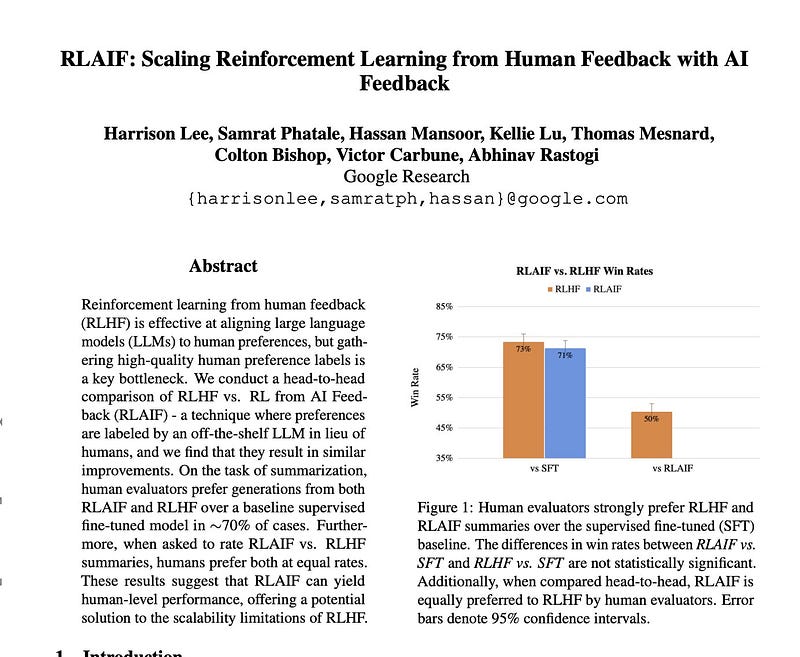
The researchers show RLAIF can match the performance of traditional reinforcement learning from human feedback (RLHF) on text summarization tasks. In side-by-side tests, human evaluators preferred summaries from RLAIF over a baseline supervised model around 70% of the time, similar to summaries from RLHF. When directly comparing RLAIF and RLHF summaries, humans showed no preference between them.
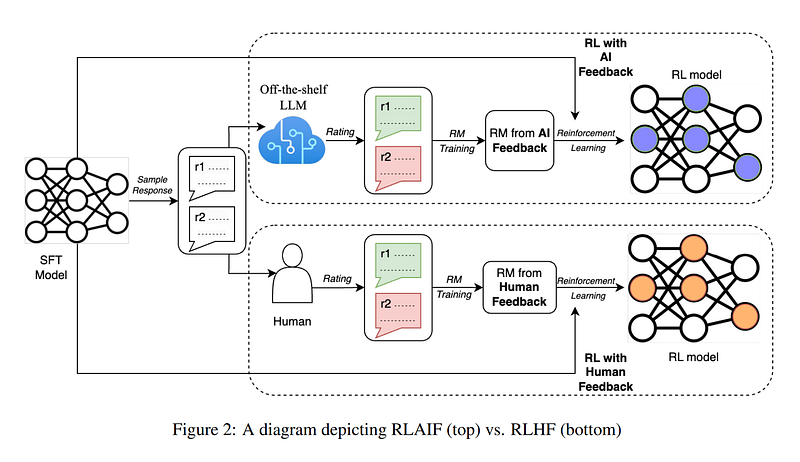
RLHF has become a popular way to optimize language models for complex objectives like generating summaries. It involves training a “reward model” on human preferences between sample outputs, then using this model to reinforce generations that humans would prefer. However, collecting high-quality human labels is expensive and time-consuming.
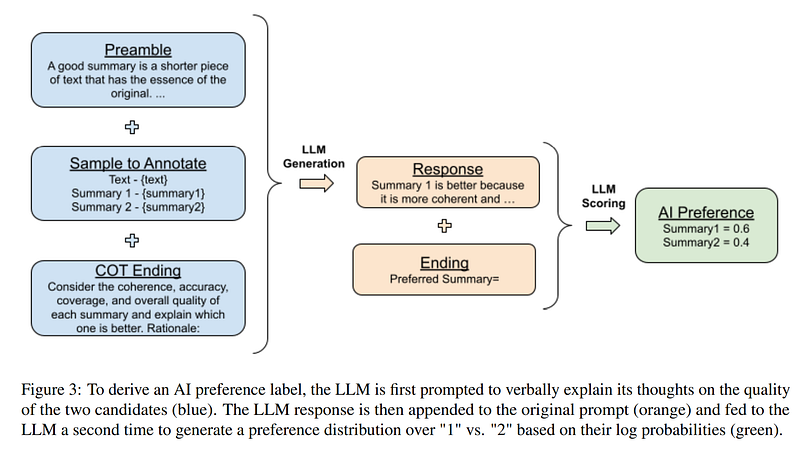
RLAIF offers a path to circumvent this bottleneck by replacing human raters with an LLM “labeler”. The researchers prompt a large LLM to judge which of two candidate summaries is better according to criteria like coherence and accuracy. The LLM’s soft preference outputs are used to train a lightweight reward model. RL fine-tuning is then conducted using this reward model for feedback.
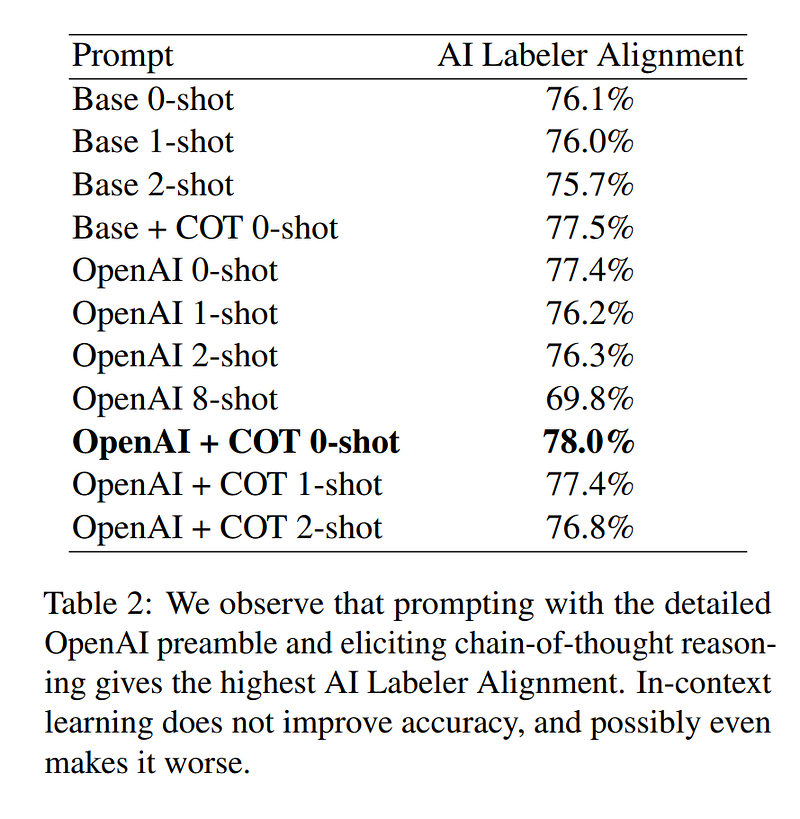
The researchers experiment with techniques to improve alignment between the LLM’s preferences and human preferences. Using detailed rating instructions and asking the LLM to explain its reasoning in free-text improves accuracy. Surprisingly, providing exemplar annotations in the prompt hurts accuracy.

Larger LLM sizes also increase alignment, with a 12% boost from the Extra Small to Large PaLM 2 models. This suggests using even bigger models could further improve alignment. The number of labelled examples plateaus in importance after a few thousand, meaning expensive inference costs are confined to an initial labelling phase.
While RLAIF currently matches RLHF, the researchers note more experiments on different tasks are needed to determine generalizability. Further research opportunities also exist in hybridizing human and AI labeling. Nonetheless, RLAIF demonstrates LLMs’ potential to circumvent the need for human raters, enabling rapid scaling of reinforced language model training.
Subscribe to DDIntel Here.
DDIntel captures the more notable pieces from our main site and our popular DDI Medium publication. Check us out for more insightful work from our community.
Register on AItoolverse (alpha) to get 50 DDINs
Support DDI AI Art Series: https://heartq.net/collections/ddi-ai-art-series
Join our network here: https://datadriveninvestor.com/collaborate