
Emote Portrait Alive (EMO): Expressive Digital Humans Generation
With the advent of the AI-generated content (AIGC) era, human-computer interaction has become increasingly important. Currently, the primary mode of interaction with large models is through text, which, while somewhat resembling human conversation, still leaves a strong desire for interaction with digital humans possessing a realistic appearance. Compared to the impersonal nature of text, human expressions often convey a wealth of information, particularly through micro-expressions, which can express a richer range of emotions such as happiness, anger, sorrow, and joy. Furthermore, a digital human with a highly realistic appearance can significantly enhance the immersive experience of human-computer interactions.
Recently, Alibaba’s TongYi XR Lab released a work named EMO, short for Emote Portrait Alive, which aims to animate portraits in a lifelike manner driven by an audio clip. A key feature of this work is the generation of digital humans with high expressiveness, a field that previous studies have rarely touched upon.
Pre-EMO Era
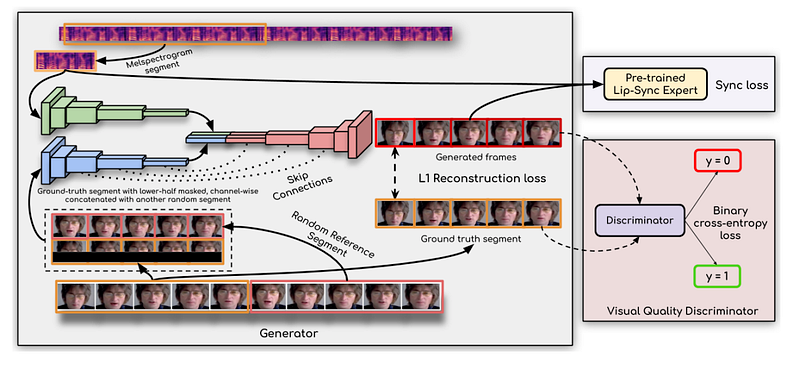
Before delving into EMO, let’s briefly review what previous digital human generation efforts have accomplished and why they haven’t garnered as much attention as they do now. When discussing works related to digital humans, one must mention an early project named Wav2Lip. The goal of Wav2Lip was to replace the lower half of a digital human’s face, regenerating a speaking head that aligns with the driving audio. Nonetheless, Wav2Lip’s limitations are glaringly evident, as it frequently produces results with exaggerated lip motions. While these appear to synchronize well with the audio, they often come across as strikingly unnatural.
Subsequent efforts, such as SadTalker, GAIA, and others, have aimed mainly to enhance the quality of generation and the synchronicity between lip movements and speech through various strategies. Although GAIA also delves into some explorations of expressiveness, both its demo’s expressive outcomes and the clarity of its generated images fall significantly short of what EMO achieves today.
Here we summarize the challenges before the EMO era:
Consistent Facial Generation. This involves ensuring the consistency of a person’s face, especially when changing angles or speaking in profile. At times, a person’s identity may seem to shift, perhaps an algorithm driving a stranger’s face might seem acceptable, but when trying to animate a friend’s or your own face, you’re likely to notice, and possibly complain, that something just doesn’t look right — certain features don’t quite match up to your own.
Imaginative Backgrounds. Previous methods either experimented on a singular background, ignoring the challenges posed by complex environments, or faced severe blurring issues when the subject moved, especially at the edges. Imagine a scenario where the subject in a scene is completely moved aside — could the background be convincingly filled in? Most previous networks lacked the imagination for this, allowing only for minor movements in the subject’s posture.
High Expressiveness Generation. I divide expressiveness into control over micro-expressions and head posture. We know that when people talk, their heads move unconsciously — imagine nodding when saying “yes.” Previous algorithms lacked this capability, maintaining the head’s posture from the original video, even if the new audio indicated a “no,” leading to a highly unnatural feeling. Additionally, control over micro-expressions, such as occasionally furrowing brows, smiling joyfully, or squinting while singing, are natural ways of interaction that were missing in previous methods.
EMO’s Architecture
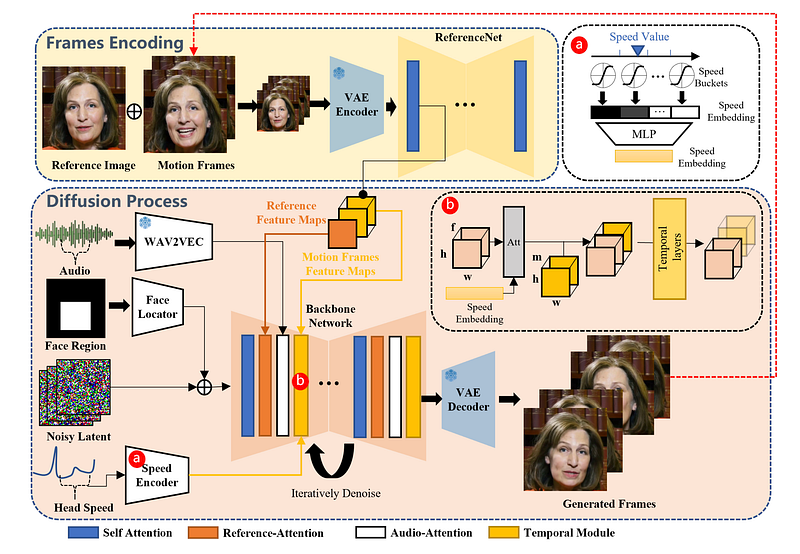
Let’s take a closer look at how EMO addresses these challenges. The structure of EMO might seem complex at first glance, but despite its impressive results in digital human generation, this architecture has been seen in other tasks. It’s essential to mention another work by the authors’ group, AnimateAnyone.
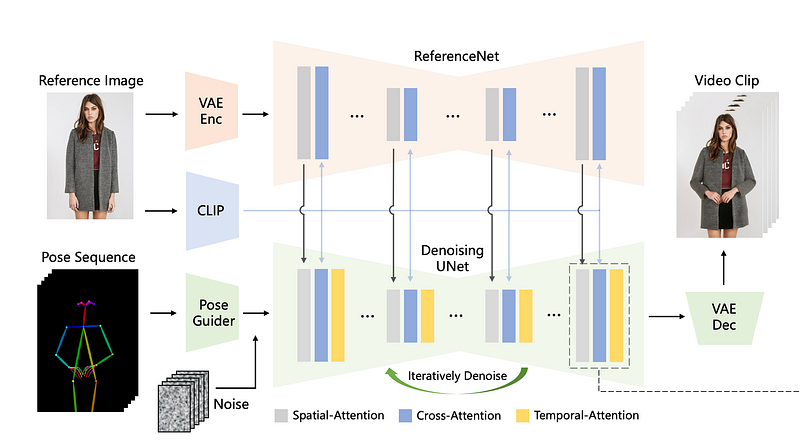
The structure of EMO is very similar to that of AnimateAnyone, employing a two U-Net structure previously seen in TryOnDiffusion. Both U-Nets used in EMO and AnimateAnyone are derived from Stable Diffusion (version 1.5), one serving as the backbone network for generating the final EMO faces (or human poses in AnimateAnyone), and the other, referred to as the reference net, aims to provide the backbone with detailed scene content, including complex backgrounds and fine facial textures (or human identity in AnimateAnyone). AnimateAnyone called backbone network denoising UNet but they are the same.
Why Stable Diffusion? Stable Diffusion was pre-trained on a vast collection of images, seeing over hundreds of millions of pictures, making it akin to an LLM (Large Language Model) for the image domain. With excellent initial parameters from extensive pre-training, it can quickly adapt to face generation tasks. Unlike text-to-image generation, where text ambiguity leads to diverse outputs, face generation requires high consistency, including maintaining identity and background information. This consistency is why the reference net is crucial, offering detailed reference frame information to accurately replicate faces and backgrounds. Moreover, the imaginative capability of Stable Diffusion allows for accurate fill-in details when parts of the scene are altered. The reference net’s U-Net and the backbone share the same structure, initially initialized from Stable Diffusion, to manipulate based on Stable Diffusion’s latent space. This approach has effectively addressed the challenges of Consistent Facial Generation and Imaginative Backgrounds by connecting two Stable Diffusion models, one for reference and the other for frame-by-frame generation.
How does EMO achieve High Expressiveness Generation? EMO outputs a video driven by an audio input based on a portrait, where the expressiveness is primarily derived from the audio. Similar to tasks related to TTS (Text-to-Speech), the audio contains rich information, such as content, pitch, speed, and emotions. The challenge lies in translating this rich audio information onto a static face. Below, I’ve redrawn an illustration focusing on three key aspects highlighted by arrows. Please pay attention to these arrows in the following diagram.
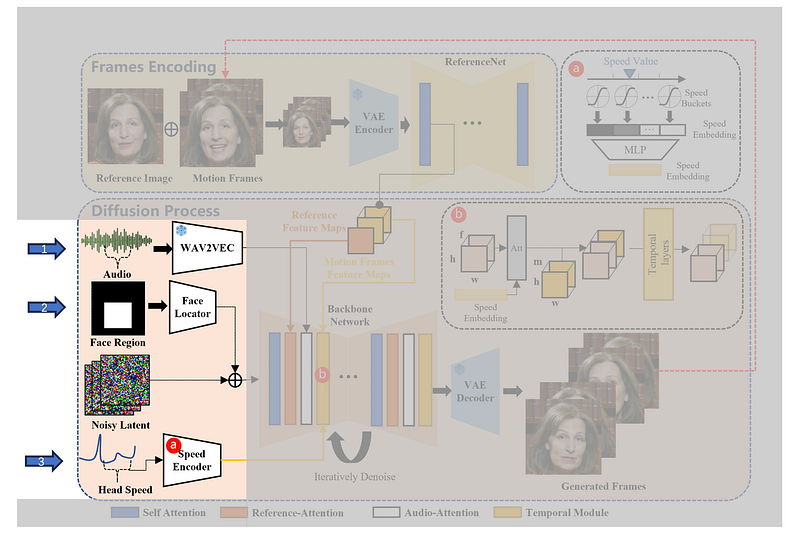
The process of generating speaker videos from audio alone presents a classic one-to-many mapping problem. For instance, when the sound “a” is uttered, the extent of mouth opening and closing varies across individuals. To address this challenge, EMO have employed pre-trained tools during the training phase to manually extract specific features as conditional inputs, thereby preserving the integrity of the mapping. The conditions are as follows:
1. Audio Condition (indicated by Arrow 1 in the diagram): Previous research primarily focused on extracting phoneme information from audio, which are the smallest units of sound in speech and are closely related to textual content, to accurately control lip movements. The results from the EMO project clearly demonstrate the successful extraction of additional information beyond phonemes, such as micro-expressions and nuanced lip movements. The wav2vec audio extractor used in this process is a self-supervised tool proven to capture both non-content-related information (such as emotion and individual speaking style) and content information (related to text), thereby providing both textual information to drive lip movement and emotional content.
2. Face Locator (indicated by Arrow 2 in the diagram): Unlike prior works that used aligned faces, thus eliminating the need to model facial positions within the frame, the EMO project did not adopt this method. Instead, it also modeled the relative position of faces within the frame. This approach allows for better control over the extent of head movement, as opposed to mechanically aligning the face within a fixed position.

3. Head Speed (indicated by Arrow 3 in the diagram): The concept of head speed is somewhat complex. It is defined as the velocity of head movement, which can be further broken down into yaw, pitch, and roll movements. The yaw refers to rotation around the vertical axis, pitch to rotation around the horizontal axis, and roll to rotation around the axis that runs from the front to the back of the head. The author argues that these dimensions allow for a nuanced modeling of head dynamics.
In summary, by explicitly modeling these three control informations during the model training process, the researchers have significantly reduced the uncertainty inherent in this process. Specifically, EMO say those controls minimize jitter, enhancing the expressiveness of talking head.
You might wonder, with these elements in place, does this task transform into a one-to-one mapping problem? It’s important to remember that the entire process is based on training using diffusion models, which possess robust modeling and sampling capabilities. Diffusion models are a class of generative models that gradually learn to produce complex distributions, starting from noise and progressively refining the output through a reverse process. By incorporating these conditions, it enables the diffusion models to more adeptly learn and harness the power of diverse sampling distributions. This inclusion significantly enriches the diffusion model’s ability to grasp and generate a wide range of potential outputs, effectively maintaining the essential one-to-many mapping nature of real-world human expressions and speech patterns.
Key Takeaways
1. Stable Diffusion: The pre-training of Stable Diffusion endows the network with a robust rendering capability, crucial for realistic face and background generation.
2. Weak Conditions: Implementing weak conditions stabilizes diffusion training, allowing the generation of diverse samples under varying conditions, ensuring stability and expressiveness in the output.
That’s all for today’s discussion. I hope this gives you some insight into the structure and design of EMO. There are still some topics we haven’t touched upon, which, although important, shouldn’t affect your understanding of the main architecture. These include:
1. The impact of using musical data on enhancing expressiveness; 2. Given that Stable Diffusion is 2D, how it can be elevated to 3D and address consistency issues within it. 3. The model’s controllable capabilities.
I plan to delve into these topics in future articles.
See you then.





