Revealing BART : A denoising objective for pretraining

True Authors of the paper : Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer
INTRODUCTION:
The article talks about a way of denoising the pretraining of a sequence to sequence model for Natural Language Generation. I have tried to explain everything from my study in a lucid way with the hope that every reader will understand the writing and will get benefitted from it. BART (though it sounds like BERT which you already know, but don’t stop here because that’s the motive of writing down this article as it will help you understand the exact literature of BART).
Nowadays, self-supervised learning for pretraining has achieved massive success in various downstream NLP tasks, for example, Word2Vec, ELMO, BERT, spanBert, XLNet etc. are all based on self-supervised learning. But among all of these, the self-supervised masked language models have really shaken the domain of NLP with its fruitful and SOTA performance. Likewise, BART is another success.
Here comes the question “What is BART?”, well, it is a self-supervised auto-encoder that first uses a noise-added source text (by corrupting some tokens in source text or using any of the suitable noise schemes discussed later in the article) as input and later uses a LM (Language Model) for reconstructing the original text by predicting the true replacement of corrupted tokens. The model is best in terms of performance when used for Natural Language Generation (NLG) tasks but it is also commendable for comprehension tasks.
ARCHITECTURE:
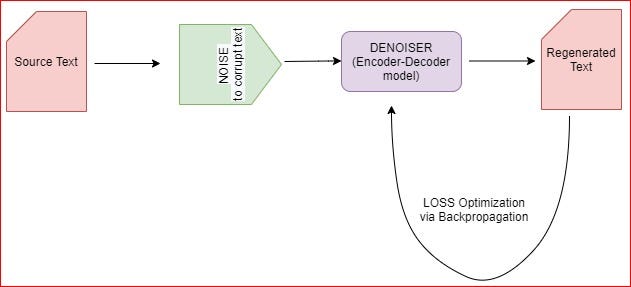
As the authors have suggested in the paper, it is a transformer based Seq2Seq model that uses corrupted source text and then tries to denoise the source text by regenerating the original text from decoder and each layer of the decoder attends to the final hidden layer of encoder. It can be seen as a Seq2Seq model modified to work as an auto-encoder. A notable feature in the architecture is the use of GELU instead of RELU activation layer. When compared to BERT, it doesn’t make use of a feed-forward network at the top for word prediction while BERT does. Moreover, BART uses just 10% more parameters compared to equivalent BERT based architecture and achieves better performance for language generation tasks. The parameters involved in the architecture are initialized as a normal distribution ~ N(0.00,0.02). The authors have talked about providing two different pretrained models as per the user’s requirement:
- Base-Case Model (6 layered architecture)
- Large-Case Model (12 layered architecture)
To prepare model for pre-training, firstly, some tokens from the input/source text are corrupted randomly (addition of noise schemes) and while training the regeneration loss is optimized using cross-entropy loss between output and the decoder’s output. Unlike existing denoising auto-encoders, which are tailored to specific noising schemes, BART allows us to apply any type of document corruption. In the extreme case, where all information about the source is lost, BART is equivalent to a language model. Let us also have a look over the noise schemes/transformations that can be used in BART over the source text:
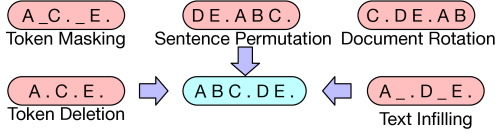
1. Token Masking : Random tokens are sampled and are masked with [MASK] tokens.
2. Token Deletion : Random tokens are sampled and deleted (similar as masking) and the model adds new token in their place.
3. Token Infilling : A number of text spans (group of contiguous tokens) is drawn from Poisson’s distribution and each span is replaced by a masked token [MASK].
4. Sentence Permutation : Random shuffling of document’s sentences.
5. Document Rotation : A token is uniformly chosen at random and the document is rotated about that token so that the document begins with that token.
Why BART is so expressive and at the top of the hill?
Let us understand this by assuming a situation where we have only BERT as a Language Model which we are interested to use for NLG tasks. Can you see any limitation? Okay, let me give you a hint: “BERT uses the source text in which some of the tokens are masked and it tries to predict the words that can actually replace those masked tokens.” If my hint sounds as if it is of no help to you, it does not mean that you are bad at things, as probably my hint was poor 😔.
Well, let me elucidate, the reason why I underlined the word “masked” in last two lines in the above hint can be understood easily if you already know that the masked tokens are predicted independently by BERT and is claimed to be a “not so good” architecture for NLG based tasks, though BERT is deeply bidirectional in nature. But architectures like GPT (that reads left-to-right context) are robust at NLG tasks due to their auto-regressive nature, however, it consists of only left-to-right context reading and is not deeply bidirectional.
Hence, in order to achieve good performance for such tasks, it is advisable to take the best of both the worlds by combining BERT for encoding the corrupted source text and GPT for generating the original text by predicting the masked tokens. That motivates the need for upbringing an encoder-decoder (seq2seq) based architecture called BART to improve the performance on downstream NLG and comprehension tasks.
Applications:
BART can be fine-tuned to have impressive performance over various downstream tasks:
- Sequence Classification: The pretrained BART is used and the final representation of the decoder’s output (top hidden states of decoder) is used as meaningful input representation of sequence and is used in a new multi-class classifier.
- Token Classification: The pretrained BART is used and the final representation of the decoder’s output (top hidden states of decoder) provides the meaningful representation of each of the words and is used for classification of token.
- Sequence Generation: It is similar to denoising pre-training objective as the decoder outputs sequence which has information copied from the original input sequence. It can be used for sequence generation in summarization and question answering tasks.
- Machine Translation: The whole pretrained encoder-decoder is assumed as decoder that will generate the target sequence and a new encoder is brought that takes source sequence as input. While training, the parameters of the pretrained architecture are frozen, only new encoder’s parameters are learned in first step where the encoder tries to learn the alignment between the source and target sequences. In second step, the whole architecture is learned for fewer iterations.
I hope that my writing was found useful, productive and advantageous to all the readers out there. I am also thankful to all the curious readers who invested their time in reading my first article. I am also sorry to those who feel that things could have been explained in more lucid way, and will request them to surely give necessary feedback, I will surely take care of your suggestions next time. Moreover, I am fully receptive and answerable your questions, doubts and feedback in relevance to this article. Signing off, stay healthy, stay motivated!