
Generative AI Series
Retrieval Augmented Generation(RAG) with LlamaIndex with Wikipedia
Implement the RAG technique using Langchain, and LlamaIndex for conversational chatbot on Wikipedia.
This blog is an ongoing series on GenerativeAI and is a continuation of the previous blog, which talks about the RAG pattern and how RAG is used to augment prompts and enhance the content and context of an LLM, with specific data.
In this blog, we will build a Q&A chatbot for content fetched from Wikipedia on Star Wars Franchise. We will be using the LlamaIndex reader WikipediaReader
Please go through the following blogs
- Prompt Engineering: Retrieval Augmented Generation(RAG)
- Retrieval Augmented Generation(RAG) with LlamaIndex
- Retrieval Augmented Generation(RAG) with LlamaIndex on a Database (Text2SQL)
Let's walk through the code. I won’t be walking through all the code, as it is very similar to what I had published and explained in my previous blogs. I will just call out specific changes made.
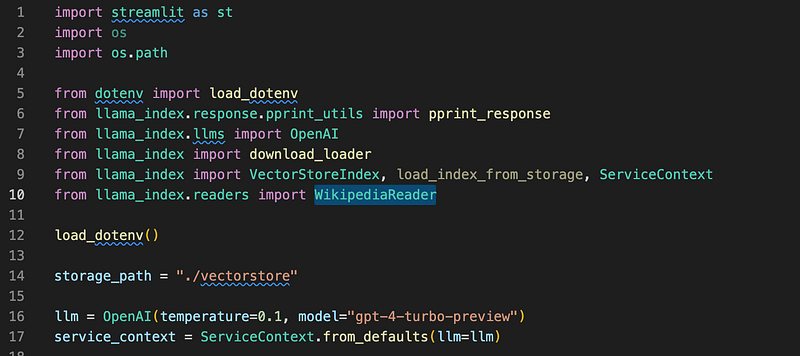
The above code is very similar to what we had done before, except that we are importing a reader WikipediaReader We will use this to parse a specific topic through Wikipedia (Star Wars). This content will be chunked, indexed, and stored as vectors. Please refer to my previous blogs for details.
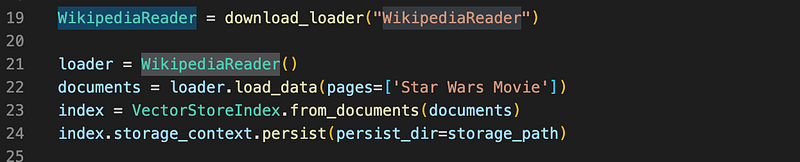
In the above code, we are initializing the WikipediaReader and providing the topic “Star Wards Movie” and creating a vector store, with that documents
The following code is very similar to what we did in the previous blogs. Please refer to those blogs for explanations
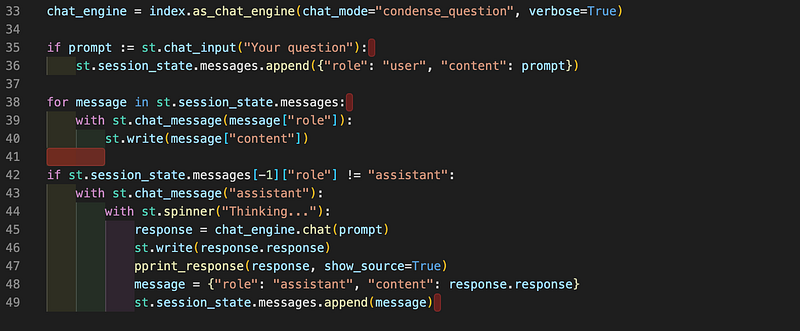
Let's run this with streamlit run wiki_chat.py
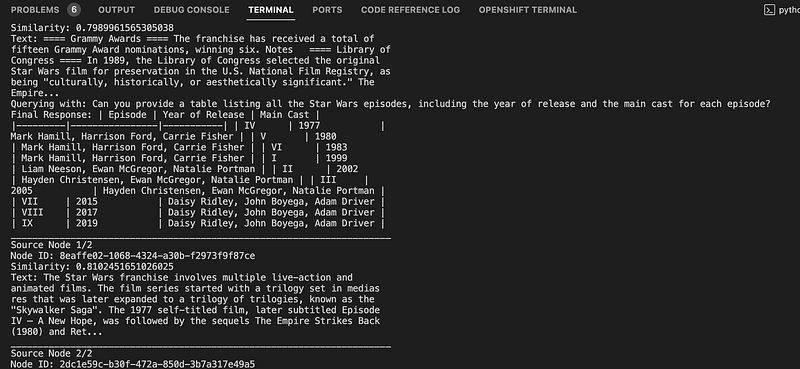
You should see a screen like below, where you can chat with the content. In the below screenshot, you can see the output
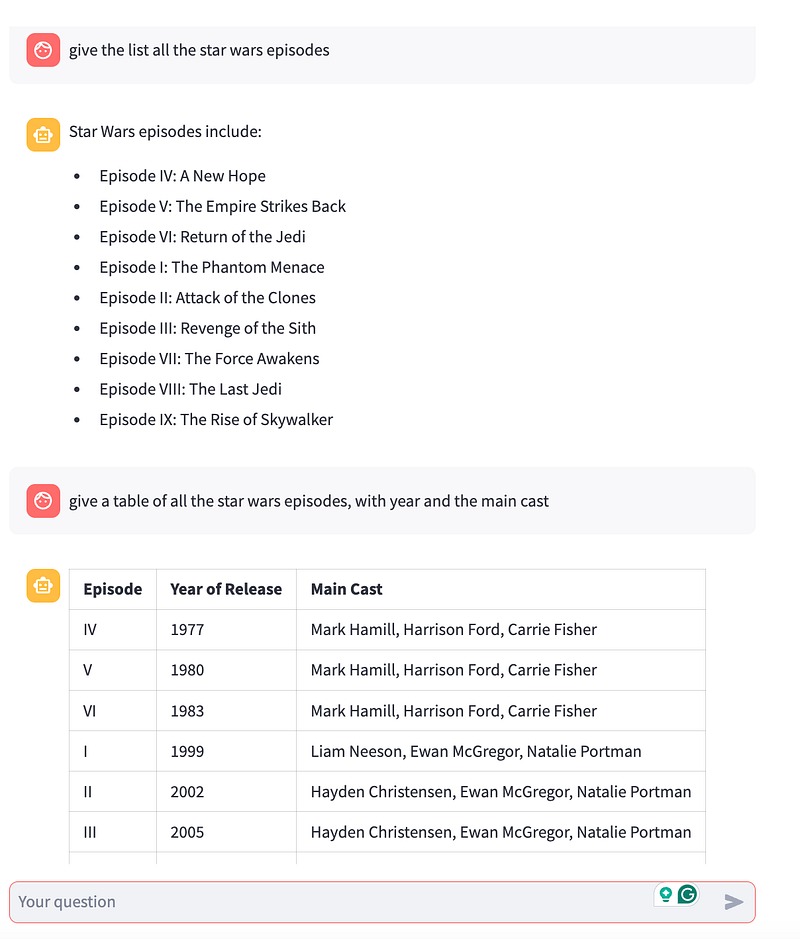
On the console, I am also printing (pprint_response) the top 2 similar responses.
Conclusion
There you go…As you can see this is super easy to implement complex RAG applications using LlamaIndex, which can ingest content from Wikipedia (and other sources). Please leave your feedback, and comments. I always learn from hearing from you all…
you can find the complete code in my GitHub here
I think I blogged enough of various document sources, I will be going a little deeper on other RAG patterns with LlamaIndex in my future blogs. Until then, stay safe and have fun… ;-)



