
Retrain, or not Retrain? Online Machine Learning with Gradient Boosting
Comparing Refit Strategies for Continuous Learning in Scikit-Learn

Training a machine learning model requires energy, time, and patience. Smart data scientists organize experiments and track trials on the historical data to deploy the best solution. Problems may arise when we pass newly available samples to our pre-build machine learning pipeline. In the case of predictive algorithms, the registered performances may diverge from the expected ones.
The causes behind discrepancies are variegated. Excluding technical mistakes, the most common and feared responsible is data drift. From the standard distribution shift to the sneaky multivariate and conceptual drift, we must prepare to handle all these situations.
In this post, we don’t focus on how to detect data drift. We try to outline how to react in the presence of data drift. Numerous interesting tools and fancy techniques have been introduced recently to facilitate data drift detection. That’s cool but what can we do after? “Refit is all you need” is the most known slogan used to handle the situation. In other words, when new labeled data became available, we should make our model continuously learn new insights from them.
With online machine learning, we refer to a multi steps training process to allow our algorithms to dynamically suit new patterns. If it’s properly made, it may provide great benefits (both in terms of speed and performance) over retraining from scratch. That’s exactly what we want to test in this post.
EXPERIMENT SETUP
We imagine operating in a streaming context where, at some regular time intervals, we can access new labeled data, calculate the metrics of interest, and retrain our predictive model.
We simulate a conceptual drift scenario. We have some features that maintain stationary and unchanged distributions over time. Our target is a linear combination of the features. The contributions of every single feature to the target are dynamic and not constant over time.
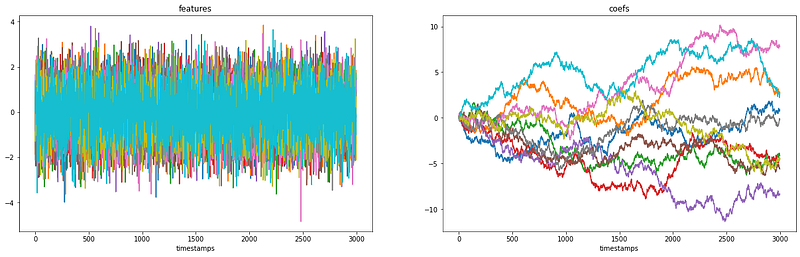
In this situation, using the same predictive model trained a time ago may be useless. Let’s investigate the option at our disposal.
REFIT IS ALL YOU NEED
To learn the relationships between target and features we need to frequently update our model. In this sense, we have different strategies at our disposal.
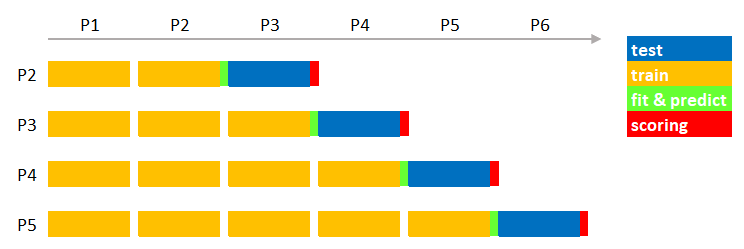
We may adopt stateful learning where we initialize, at some predefined intervals, training from scratch with the data at our disposal. All we have to do is merge the new samples with the historical ones. We don’t need to store the previously fitted model since we recreate it.
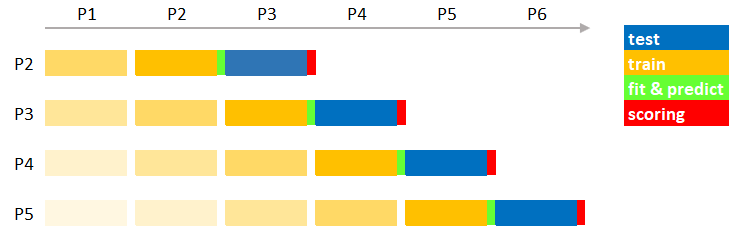
A variation of stateful learning it’s weighted stateful learning. It consists in giving the latest observations a higher weight. This may be useful to weigh more the recent data and make the new model focus on the latest patterns. Carrying out a weighted training is straightforward. Lots of the latest machine learning algorithm implementations provide the build-in possibility to give each sample a different weight.
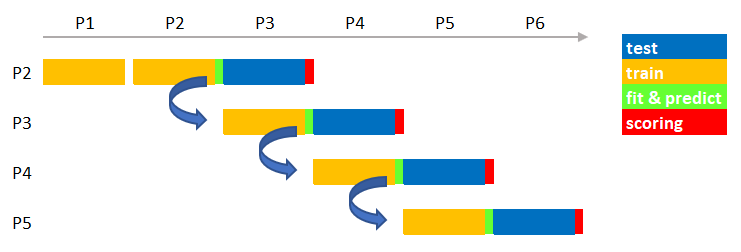
On the other hand, we may consider continuous learning, aka online machine learning. In continuous learning, we use the previous model knowledge to initialize a new training step. We take the new set of available samples and make the previously fitted model learn new patterns from them. By updating (instead of reinitializing) the model knowledge, we hope to get better performances reducing the costs of training from scratch.
ONLINE MACHINE LEARNING IN PRACTICE
Online machine learning is natively supported by all neural network-based algorithms. We can anytime continue the training process by updating the loss sample-wise while passing new data.
Practically speaking, in the scikit-learn ecosystem, all the algorithms that support the partial_fit method can carry out continual learning. In the code snippets below, we introduce how we can do it with a few lines of code.
cv = TimeSeriesSplit(n_splits, test_size=test_size)for i,(id_train,id_test) in enumerate(cv.split(X)):
if i>0:
model = model.partial_fit(
X[id_train[-test_size:]], y[id_train[-test_size:]]
)
else:
model = SGDRegressor(**fit_params).fit(
X[id_train], y[id_train]
)Coming back to our experiment, we test the three mentioned training strategies (stateful learning, weighted stateful learning, and continuous learning) on our simulated data using a SGDRegressor. We don’t do this a single time but we do it multiple times by simulating different scenarios to better take care of the variability in the simulation process. We regularly evaluate our models for 20 periods and store the prediction errors (calculated as SMAPE) for all the simulated scenarios.
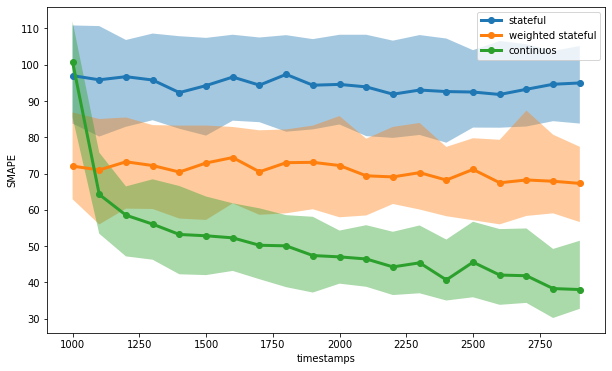
We can see that continuous learning can achieve the greatest performance compared to the other strategies. Giving more weight to the recent observations, weighted stateful learning can also do better than standard stateful learning.
These results sound promising. Is it possible to do online machine learning with other algorithms? We know the great power of tree-based gradient boosting. Lots of machine learning projects use them thanks to their adaptability in a variegated range of situations. It would be great to have the possibility to operate online machine learning also with them.
Hopefully, we can do it! It is easy as in the previous case. We report a snippet where we introduce how we can do it with LGBMRegressor.
cv = TimeSeriesSplit(n_splits, test_size=test_size)for i,(id_train,id_test) in enumerate(cv.split(X)):
if i>0:
model = LGBMRegressor(**fit_params).fit(
X[id_train[-test_size:]], y[id_train[-test_size:]],
init_model = model.booster_
)
else:
model = LGBMRegressor(**fit_params).fit(
X[id_train], y[id_train]
)Let’s see it in action in our simulated scenario.
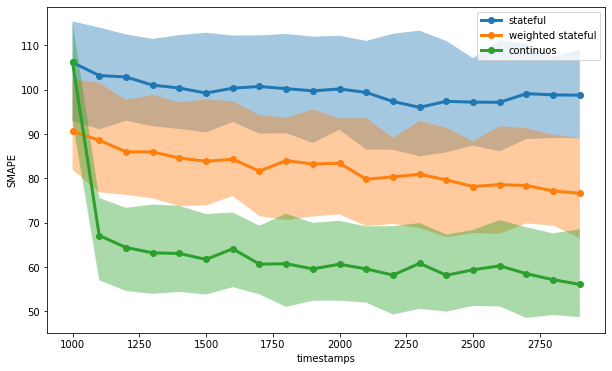
We achieve the same satisfactory results as before. If properly handled, online machine learning sounds to be effective and available with different algorithms.
SUMMARY
In this post, we introduced the concept of online machine learning. We explored different stateful refitting strategies comparing them with a continuous learning approach. Online machine learning revealed to be a good approach to test in some applications. Doing online machine learning is a bit of an art. It’s not granted it may lead to performance improvement. High it’s the risk to make the model forget what it learned (catastrophic forgetting). In this sense, having a solid and adequate validation strategy is more important than ever.
If you are interested in the topic, I suggest:
- SHAP for Drift Detection: Effective Data Shift Monitoring
- Data Drift Explainability: Interpretable Shift Detection with NannyML
- Model Tree: handle Data Shifts mixing Linear Model and Decision Tree
Keep in touch: Linkedin





