
RetNet: Transformer killer is here
I don’t think there has been a bigger paper than “Attention is all you need.” In the last few years. Attention-inspired Transformers have become the backbone of every major AI architecture, given its capability to process everything from sound to images, from text to video. Transformer has been the king of architecture for the last few years and became even more popular after the release of LLMs. But this architecture has a slight problem: it is quite a memory and resource-intensive design. In today’s blog, we will look into a new architecture developed by Microsoft to beat Transformers. This paper could be seen as the successor to Transformers and might hold great promises as we move towards the future.
Here’s what we are going to talk about:
- What does RetNet achieve?
- Background (Problem with attention mechanism and other research avenues)
- Understanding recurrent and parallel
- RetNet architecture
What does RetNet achieve?
Let’s begin with what is the claim of the paper directly.
It is foundational architecture for LLMs, simultaneously achieving training parallelism, low-cost inference, and good performance.
- The proposed retention architecture supports three computation paradigms, i.e., parallel, recurrent, and chunkwise recurrent.
- The recurrent representation enables low-cost O(1) inference, improving decoding throughput, latency, and GPU memory without sacrificing performance.
- The chunkwise recurrent representation facilitates efficient long-sequence modeling with linear complexity, where each chunk is encoded parallelly while recurrently summarizing the chunks.
The below image shows the performance increase over the traditional transformer architecture.
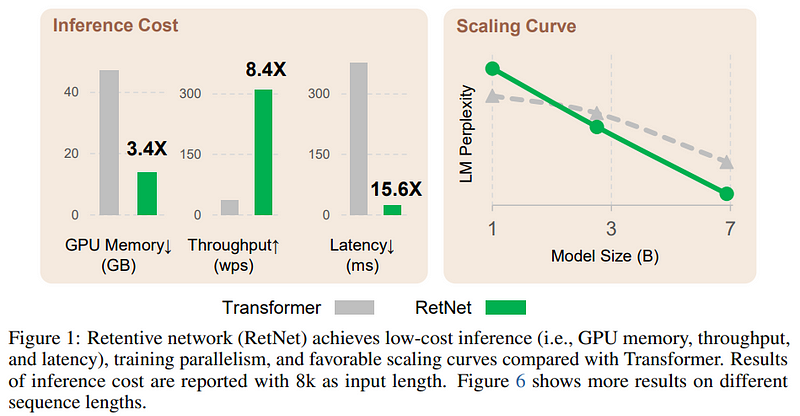
Now the objective of the paper is clear, let’s try to understand how this is achieved and get more background on the problem itself.
Background
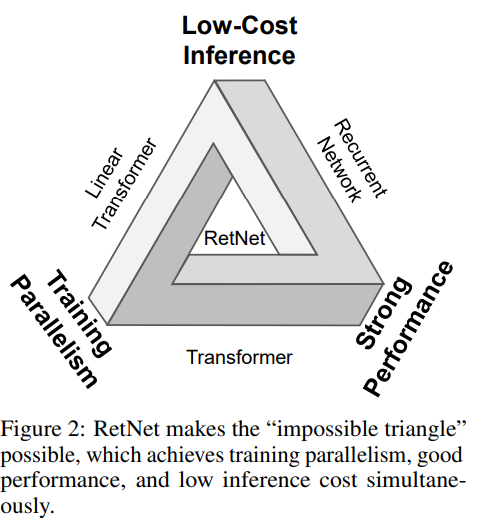
The above diagram clearly shows what RetNet is trying to achieve: Training parallelism, stronger performance, and low-cost Inference.
Let’s break down what are the problems with current Transformers
Quadratic Complexity: When you look at Transformers and their self-attention bit, they’re kind of like the nosy neighbors of the algorithm world. Each token wants to know about every other token in a sequence.
So, if you’ve got a sequence that’s (N) tokens long, you’re doing (N times N) calculations just for attention scores. In perspective, if you have a sequence of 100 tokens, that’s 10,000 calculations — just for one layer! If you double the sequence length, the math gets crazy. You’re talking about 40,000 calculations. It’s like trying to listen to every conversation at a packed stadium.
Memory Needs: Now, let’s talk space. Beyond just the brainpower needed for these calculations, you’ve got to have room to store all the information. It’s like needing a massive wardrobe for all your clothes and buying more. For instance, think about BERT. Typically, BERT juggles info from 512 tokens at a time.
For every token pair, there’s a bit of data stored. So, if you imagine a grid of 512 by 512 for each attention “look” (or head, in techie terms), it adds up. Now picture BERT with its 12 different “looks” or attention heads. That’s 12 massive grids, and that’s just scratching the surface. It’s like trying to cram all your belongings into a studio apartment.
Dealing with Longer Sequences: The thing about Transformers is they’re champs with short to medium-sized tasks. But give them something long, like a book? That’s where things get dicey.
For instance, if you tried summarizing a 10-page magazine feature using BERT, you’d hit a wall. Even if you managed it, you’d have to chop up the article, handle each bit separately, and then try piecing it together. And in that process, you might miss out on the broader story or the subtle connections. It’s like trying to create a movie plot by only watching snippets.
Now let’s look at the things that have been tried to solve these challenges. Before the invention of RetNet, there were three different strategies to tackle these challenges.
Linearized Attention
Methodology: This approach approximates the standard attention scores, traditionally calculated as exp(q · k). Instead, it uses linearized attention kernels, denoted as ϕ(q) · ϕ(k). This approximation allows for autoregressive inference to be reshaped into a recurrent form.
Drawbacks: This approach's performance and modeling capability are inferior to Transformers. Due to these limitations, linearized attention hasn’t gained widespread popularity in the research community.
Recurrent Models with Element-wise Operators
Methodology: This method borrows inspiration from recurrent models to enhance inference efficiency. However, in doing so, it sacrifices training parallelism. To mitigate this limitation, the models incorporate element-wise operators designed to accelerate the process.
Drawbacks: Even with the accelerative capabilities of element-wise operators, there’s a detrimental effect on the model's representation capacity and overall performance.
Alternative Attention Mechanisms
Methodology: The third approach seeks to use something other than the attention mechanism.
Drawbacks: None have successfully overcome the “impossible triangle” challenge. As a result, no methodology conclusively outperformed Transformers.
Understanding Recurrent and Parallel
To understand the idea behind RetNet, we need to understand a few key concepts of parallel and recurrent.
Let’s consider a Linear Equation:
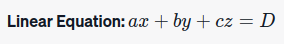
How do we solve this using parallel computation?: In a parallel computational model, we’d use matrix multiplication.
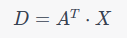
Here, A = [a, b, c]` and X = [x, y, z]` With matrix operations on hardware accelerators (like GPUs), this operation is done almost instantly for all terms simultaneously.
How do we solve this using Recurrent Computation? In a recurrent approach, we’d calculate one term at a time and accumulate:
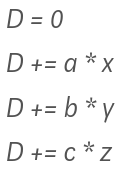
Here, only one multiplication is done at each step, and we need not store multiple variables to handle all this; it can be done with three variables. Earlier, we needed seven variables. This approach saves a lot of cache memory of the GPU.
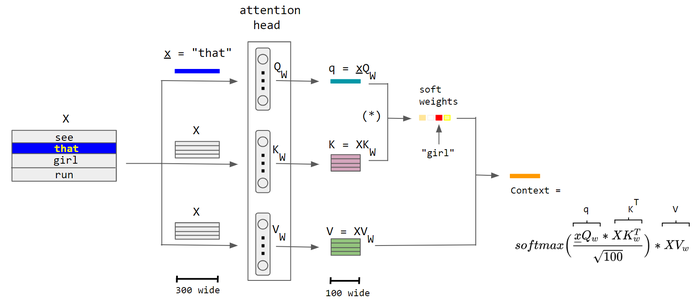
Attention Mechanism
Attention Score Calculation: The attention score between two tokens in a sequence using their query (Q) and key (K) representations is given by:
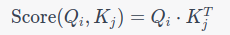
For all pairs of tokens in a sequence of length N, this becomes:
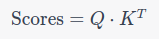
Parallel Computation: You can calculate all ( N²) scores simultaneously using matrix multiplication. After this, applying the softmax function will provide the attention weights:
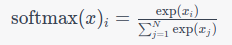
Given the softmax function's dependencies, this operation also benefits from parallelization.
Recurrent Computation: Theoretically, we could compute the scores one at a time, considering one token’s relationship with all others before moving to the next. But there’s a problem: the softmax normalization.
Even if you computed the score for token 1 with all other tokens, you can’t get the final attention weight for token 1 until you have all other scores because of the denominator in the softmax function.
To simplify, in the equation ( ax + by + cz = D ), calculating (ax), (by), and (cz) is similar to getting the raw attention scores. But the addition operation (which can be done step-by-step in sequence) is where the analogy breaks down with attention because the equivalent step in attention is the softmax normalization, which requires all scores simultaneously.
RetNet Architecture
Given that we understand what is recurrent and parallel and how it plays an important role in the Attention mechanism let’s see what RetNet does.
Standard Attention Mechanism
1. Projections:
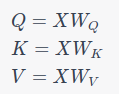
2. Attention Scores:
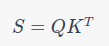
3. Softmax Normalization:
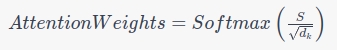
4. Attention Output:

Retention Mechanism
1. Projections:
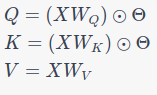
2. Parallel Representation:
Using positional information and a decay factor:
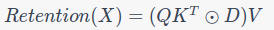
Where (Θ) provides the complex conjugate for positional information and (D) combines causal masking and exponential decay.
3. Recurrent Representation:
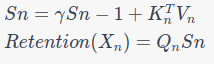
The state (s_n) is updated for each sequence element (X_n).
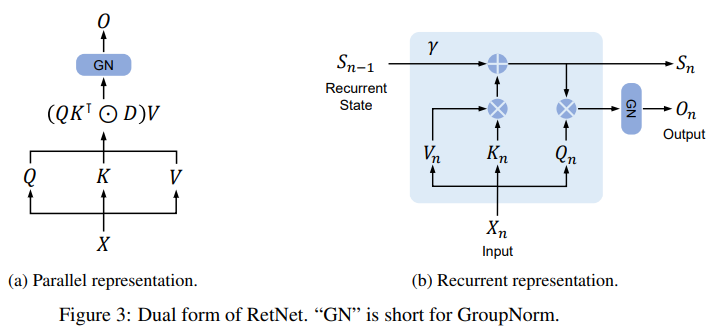
Comparison
Projections: Both methods project the input sequence (X) into Query, Key, and Value matrices. However, the retention mechanism introduces the additional term (⊙ Θ) to incorporate positional information in its projections.
Attention Scores: — Standard Attention: Uses a simple dot product between Queries and Keys. — Retention Mechanism (Parallel): Uses a complex function involving (Q), (K), and (D) (which provides masking and decay).
Normalization: — Standard Attention: Uses the Softmax function on the attention scores. — Retention Mechanism: Doesn’t employ softmax. Instead, it uses the term (⊙ D) for normalization, which inherently combines causal masking and exponential decay.
Output: — Standard Attention: Computes the output as a weighted sum of the Value matrix. — Retention Mechanism (Recurrent): It computes the output for each sequence element, updating a state ( s_n) in the process.
In essence, while the standard attention computes weights to determine the importance of various parts of an input sequence, the retention mechanism aims to introduce a dual form, capturing the benefits of both recurrent (memory saving)and parallel processing (faster computing).
I’m not putting the results, as there is a lot to unpack there, which will make the blog lengthy. If you are interested, go and read the original paper given below.
This marks the end of this blog. The given paper has a lot of maths, and I made it as simple as possible. Writing such articles is very time-consuming, so show love and respect by clapping and sharing the article. Happy learning ❤




