
Restricted Boltzmann Machine Creation as Recommendation System for Movie Review (part 1)
Intuitive Introduction on Restricted Boltzmann Machine and Detailed Data Processing Steps for Model Training using Movie Rating Data

This is Part 1 of how to build a Restricted Boltzmann Machine (RBM) as a recommendation system. Here the focus is on data processing.
What you will learn is how to transform raw movie rating data into data ready to train the RBM model. It is split into 3 parts.
- RBM introduction
- Problem statement
- Data processing
Now let’s begin the journey 🏃♂️🏃♀️.
- RBM introduction
First, let’s start with the Boltzmann machine (BM). BM is a type of unsupervised neural network. Three distinct features characterize BM as illustrated in Figure 1.
- No output layers
- No direction between connection
- Each neuron is densely connected to each other, even between input nodes (visible nodes)
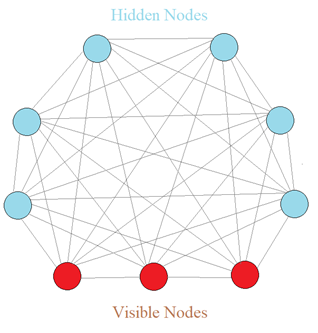
Why BM so special? Fundamentally, BM does not expect inputs. On the contrary, it generates states or values of a model on its own. Thus, BM is a generative model, not a deterministic model. BM does not differentiate visible nodes and hidden nodes. Visible nodes are just where we measure values.
However, BM has an issue. As the number of nodes increases, the number of connections increases exponentially, making it impossible to compute a full BM. Therefore, RBM is proposed as Figure 2 shows.
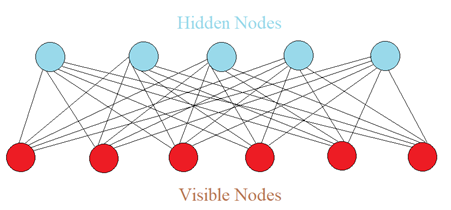
Compared to full BM, RBM does not allow connections between hidden nodes, and connections between visible nodes. This is the only difference 📣📣.
Through the training process, we feed a large amount of data to RBM, RBM learns how to allocate each hidden node to represent features of movies such as genres, actors, directors, etc. In another word, the weight of each node is adjusted in such a way that hidden nodes are better reflective of the features.
Specifically, RBM will accept inputs from visible nodes into hidden nodes. It tries to reconstruct the input values based on hidden node values. If the reconstructed values are incorrect, the weights are adjusted, and RBM reconstructs the input again. In the end, RBM is trained to best represent the system which generates all the data. The benefit is with all weights optimized, RBM can understand what is normal and abnormal for the system.
2. Problem statement
A large amount of movie rating data is given to build an RBM. The task is to predict if a user likes a movie as 1 or dislike as 0.
3. Data processing
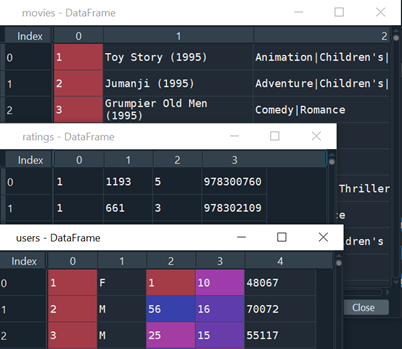
The data MovieLens 100K movie ratings are from GroupLens Research here. Briefly looking at the data in Figure 3, Movies data contain names and types of movies, Ratings data contains user ID, movie ID, user rating from 0 to 5 and timestamps, and User data contain user ID, gender, age, job code, and zip code.
3.1 Import data
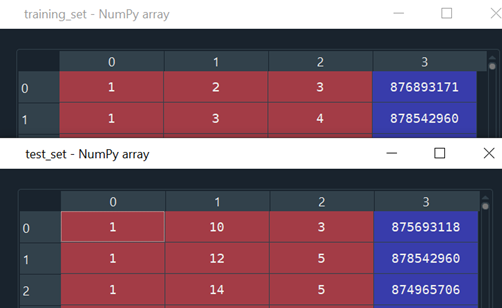
The dataset contains 80,000 rows for the training set and 20,000 rows for the test set. Let’s read in them. Specifically,
training_set = pd.read_csv(‘ml-100k/u1.base’, delimiter = ‘\t’)
training_set = np.array(training_set, dtype = ‘int’)test_set = pd.read_csv(‘ml-100k/u1.test’, delimiter = ‘\t’)
test_set = np.array(test_set, dtype = ‘int’)Note we convert Dataframe to Numpy array because we will use Pytorch tensor which requires array as input. Figure 4 shows the training/test set, including user ID, movie ID, rating, and timestamps (irreverent for model training).
3.2 Data structure creation
To prepare the training/test data, we need to create training/test sets in array format with each row representing a user and each cell in the row representing the rating for each movie. This is the expected input for RBM.
To do this, we need the total number of users as row numbers and the total number of movies as a column number.
nb_users = int(max(max(training_set[:, 0]), max(test_set[:, 0])))
nb_movies = int(max(max(training_set[:, 1]), max(test_set[:, 1])))We create a function for data conversion which returns a list of lists. Each child list represents one user’s ratings for all movies. If the user did not rate a movie, initialize the rating with 0.
def convert(data):
new_data = []
for id_users in range(1, nb_users + 1):
id_movies = data[:,1][data[:,0] == id_users]
id_ratings = data[:,2][data[:,0] == id_users]
ratings = np.zeros(nb_movies)
ratings[id_movies — 1] = id_ratings
new_data.append(list(ratings))
return new_dataWith the above conversion, we convert the training set and test set.
training_set = convert(training_set)
test_set = convert(test_set)Figure 5 shows the final training set. Again, each row contains a user’s ratings for all movies.
Finally, we convert the list of list type into Tensor because we will use Pytorch to build the RBM.
training_set = torch.FloatTensor(training_set)
test_set = torch.FloatTensor(test_set)3.3 Binary data conversion
Our task is to predict if users like the movies as 1 and not like as 0. RBM will take the movie ratings by a user and try to predict movies that were not rated by the user. Since the to-be-predicted ratings are computed from the original input, we must keep the input ratings and predicted ratings in a consistent manner.
Specifically, rating set as 0 previously is reset to be -1, movies given 1 or 2 are set as 0 (not like), and movies rating over 3 set as 1 (like).
training_set[training_set == 0] = -1
training_set[training_set == 1] = 0
training_set[training_set == 2] = 0
training_set[training_set >= 3] = 1test_set[test_set == 0] = -1
test_set[test_set == 1] = 0
test_set[test_set == 2] = 0
test_set[test_set >= 3] = 1Great. We successfully converted raw to binary rating data, ready to train the model.
Great! That’s all for Part 1. The next article will walk through how to build an RBM step by step. If you need the source code, visit my Github page 🤞🤞.