
ResNeXt: Revolutionizing Deep Learning with Wide Residual Networks
Introduction
In the ever-evolving landscape of deep learning, the ResNeXt architecture has emerged as a pivotal innovation, redefining the boundaries of convolutional neural networks (CNNs). Building upon the foundational concepts of ResNet (Residual Networks), ResNeXt introduces a novel approach by incorporating the dimension of “cardinality” in addition to depth and width. This essay delves into the intricacies of ResNeXt, exploring its unique structure, the rationale behind its design, and its implications in the field of computer vision and beyond.
A leap in the architecture of neural networks, ResNeXt stands as a testament to the notion that efficiency and complexity can coexist harmoniously, paving the way for deeper understanding through simpler designs.
The Evolution of CNN Architectures
The development of CNNs has been characterized by a pursuit to enhance feature representation and learning efficiency. The introduction of ResNet marked a significant milestone, addressing the vanishing gradient problem through skip connections and enabling the training of much deeper networks. However, the quest for more efficient and powerful networks continued, leading to the conception of ResNeXt.
Concept and Design
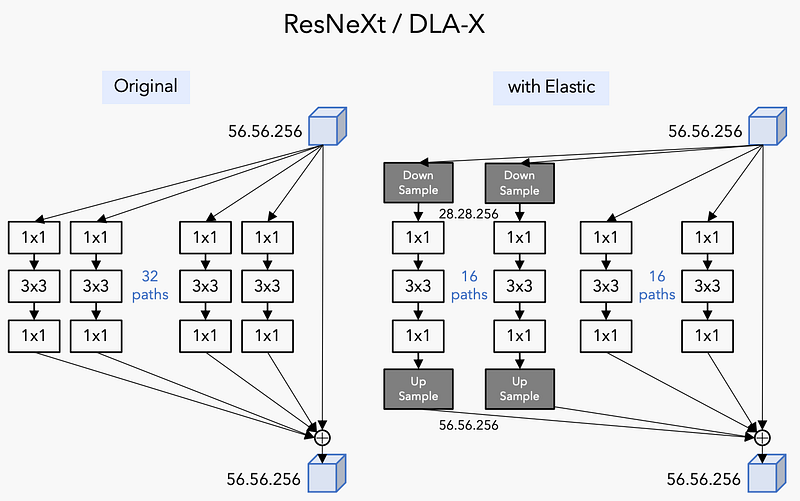
ResNeXt stands for “Residual Networks Next,” indicating its position as an evolution of the ResNet architecture. Its central innovation lies in the introduction of cardinality, a dimension that represents the number of parallel paths within a layer. This approach is inspired by the Inception network’s methodology but simplifies it by using identical transformations across these paths.
The wide residual networks in ResNeXt imply a strategic increase in the width (number of neurons per layer) rather than just depth (number of layers). This tactic enhances the network’s learning capability without a proportional increase in computational complexity. Each layer in ResNeXt consists of a set of transformations, which are aggregated at the end. This block structure, a repeating unit in the network, simplifies the architecture and reduces hyperparameter tuning.
ResNeXt is a type of convolutional neural network (CNN) architecture that is an extension of the ResNet (Residual Networks) architecture. It was developed to improve the performance of CNNs by enhancing their ability to learn feature representations. ResNeXt introduces a new dimension, called “cardinality,” in addition to depth and width, commonly used in network design. This innovation enables the model to achieve higher accuracy without significantly increasing computational complexity.
Here’s an overview of its key aspects:
- Cardinality: Refers to the number of parallel paths in the network’s layers. In ResNeXt, multiple smaller transformations (set of convolutions) are applied, and their outputs are aggregated. This idea is similar to the way the Inception network works but in a simpler and more parameter-efficient manner.
- Wide Residual Networks: ResNeXt also integrates the concept of wide residual networks. These are a variant of ResNet where the layers are wider (more neurons per layer) but shallower (fewer layers). This approach is found to be more effective than just increasing depth, as it provides a better trade-off between accuracy and computational efficiency.
- Block Structure: ResNeXt uses a repeating building block that aggregates a set of transformations with the same topology. This uniformity simplifies the network’s architecture and reduces the number of hyperparameters.
- Efficiency and Performance: By using grouped convolutions and focusing on cardinality, ResNeXt offers improved performance (in terms of classification accuracy) without a substantial increase in computational cost. This makes it suitable for tasks requiring high accuracy without excessive resource usage.
- Applications: ResNeXt has been successfully applied in various fields of computer vision, such as image classification, object detection, and segmentation, demonstrating its versatility and effectiveness.
Overall, ResNeXt represents an important step in the evolution of CNN architectures, showing that carefully balancing depth, width, and cardinality can lead to significant improvements in model performance.
Advantages and Efficiency
One of the key advantages of ResNeXt is its efficiency. The use of grouped convolutions and focus on cardinality rather than just depth or width leads to better utilization of computational resources. This efficiency does not come at the cost of performance; ResNeXt demonstrates significant improvements in tasks like image classification, object detection, and segmentation over its predecessors.
Applications and Impact
The architecture has found applications across a broad range of computer vision tasks. Its ability to handle complex patterns and structures efficiently makes it suitable for high-accuracy requirements in various fields, from medical imaging to autonomous vehicles.
Code
Implementing a ResNeXt model in Python with a synthetic dataset and visualizing the results involves several steps. Below, I’ll provide a complete guide and code snippets to help you through this process. The implementation will use libraries like TensorFlow and Keras.
- Generate a Synthetic Dataset We’ll create a simple synthetic dataset using NumPy for demonstration purposes.
- Define the ResNeXt Model We will define a simplified version of the ResNeXt model. Note that building the exact ResNeXt model from scratch is complex and beyond the scope of this example.
- Train the Model We will train the model on the synthetic dataset.
- Plot the Results We’ll use Matplotlib to plot the training history.
Here’s the Python code to implement these steps:
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, Add
import numpy as np
import matplotlib.pyplot as plt
# Generate Synthetic Dataset
def generate_synthetic_data(num_samples=1000, img_shape=(32, 32, 3)):
X = np.random.rand(num_samples, *img_shape).astype(np.float32)
y = np.random.randint(0, 10, num_samples)
return X, y
X_train, y_train = generate_synthetic_data()
X_test, y_test = generate_synthetic_data()
# Define a Simplified ResNeXt Block
def resnext_block(inputs, filters, cardinality):
convs = []
for _ in range(cardinality):
x = Conv2D(filters, (3, 3), padding='same')(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
convs.append(x)
x = Add()(convs)
x = Conv2D(filters, (1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
shortcut = Conv2D(filters, (1, 1), padding='same')(inputs)
shortcut = BatchNormalization()(shortcut)
x = Add()([x, shortcut])
return Activation('relu')(x)
# Model Definition
inputs = tf.keras.Input(shape=(32, 32, 3))
x = resnext_block(inputs, filters=64, cardinality=8)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
outputs = tf.keras.layers.Dense(10, activation='softmax')(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train the Model
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))
# Plot the Results
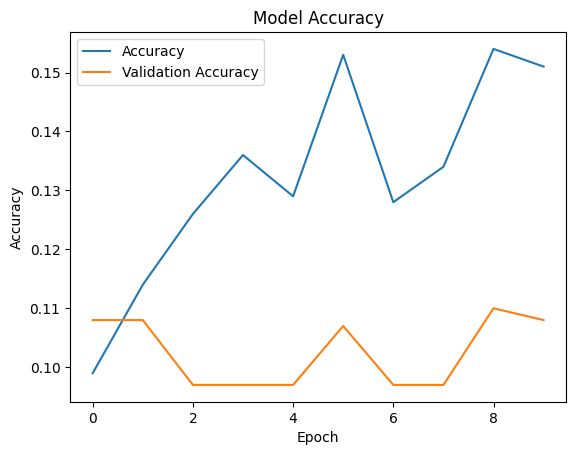
plt.plot(history.history['accuracy'], label='Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend()
plt.show()Note:
- The above code provides a simplified ResNeXt block for demonstration. The full ResNeXt architecture is more complex and involves multiple such blocks with varying parameters.
- The synthetic dataset is random and does not represent real-world data. It’s used here for demonstration purposes only.
- The number of epochs, data shapes, and model parameters can be adjusted based on specific requirements or computational resources.
Epoch 1/10 32/32 [==============================] - 34s 757ms/step - loss: 2.4287 - accuracy: 0.0990 - val_loss: 2.3127 - val_accuracy: 0.1080 Epoch 2/10 32/32 [==============================] - 24s 754ms/step - loss: 2.3052 - accuracy: 0.1140 - val_loss: 2.3871 - val_accuracy: 0.1080 Epoch 3/10 32/32 [==============================] - 29s 914ms/step - loss: 2.2912 - accuracy: 0.1260 - val_loss: 2.4742 - val_accuracy: 0.0970 Epoch 4/10 32/32 [==============================] - 24s 767ms/step - loss: 2.2891 - accuracy: 0.1360 - val_loss: 2.5461 - val_accuracy: 0.0970 Epoch 5/10 32/32 [==============================] - 29s 905ms/step - loss: 2.2839 - accuracy: 0.1290 - val_loss: 2.5983 - val_accuracy: 0.0970 Epoch 6/10 32/32 [==============================] - 29s 913ms/step - loss: 2.2824 - accuracy: 0.1530 - val_loss: 2.6647 - val_accuracy: 0.1070 Epoch 7/10 32/32 [==============================] - 23s 727ms/step - loss: 2.2811 - accuracy: 0.1280 - val_loss: 2.6787 - val_accuracy: 0.0970 Epoch 8/10 32/32 [==============================] - 24s 736ms/step - loss: 2.2742 - accuracy: 0.1340 - val_loss: 2.6749 - val_accuracy: 0.0970 Epoch 9/10 32/32 [==============================] - 30s 937ms/step - loss: 2.2693 - accuracy: 0.1540 - val_loss: 2.6836 - val_accuracy: 0.1100 Epoch 10/10 32/32 [==============================] - 25s 795ms/step - loss: 2.2665 - accuracy: 0.1510 - val_loss: 2.7231 - val_accuracy: 0.1080
Conclusion
ResNeXt represents a significant leap forward in the design of neural networks. By balancing depth, width, and cardinality, it achieves high levels of accuracy and efficiency, addressing some of the key challenges in deep learning. As the field continues to evolve, architectures like ResNeXt will play a crucial role in unlocking new potentials and applications, furthering the boundaries of what artificial intelligence can achieve.



