
Recommendation System: An Introduction

Believe it or not, recommendation system is one of the most successful and widely used machine learning application in real world business problems.
As an example, I often read funny comments on a Youtube video stating that people find out about a particular video not because they searched it explicitly, but because “Youtube algorithm” recommended it to them. I find it fascinating that the recommendation system allows you to find relevant videos that you might never find had it never been recommended to you.
In this article, I want to talk about three different recommendation systems: content-based filtering, collaborative filtering, and context-aware filtering. Specifically, I want to discuss about what they are, how they work, and their pros and cons. Finally, the metrics to measure how good a recommendation is will also be briefly discussed.
First, let’s talk about content-based recommendation system!
What is Content-Based Recommendation System?
Content-based recommender system recommends new items based on feature similarities to items that a person has liked in the past.

Let’s use image above as an example. Let’s say you just watched Twilight movie and you loved it to death, hence you gave it 10 stars rating on a movie database. The content-based recommender system then will try to recognize certain features in Twilight movie, i.e its genre, theme, movie summary text, etc. and use these features to find other movies that have feature similarity to Twilight. At the end, probably you will get a recommendation to watch Fifty Shades of Grey.
One thing that distinguish content-based recommendation to collaborative filtering is that it doesn’t rely on information about other people’s preferences. So, the recommendation is made based only on your preferences and what you have liked in the past.
What are the Examples of Content-Based Recommender System?
As explained above, content-based recommender system recommends new items based on their feature or attribute similarity to the items that you have liked in the past. Below is the example of content-based recommender system:
- Clothing → you frequently bought casual and black clothes with cotton material in the past, hence the system will give you recommendations about similar clothes.
- Movies → you gave a high rating to movies with Leonardo DiCaprio, Christopher Nolan, and Action genre in the past, hence the system will give you recommendations about movies with these features.
- News → you liked stories about technology and machine learning in the past, hence the system will give you recommendations about news within technology and machine learning topics.
How does Content-Based Recommender System Works?
In short, content-based recommender system uses similarity algorithm as its principle to determine whether the content of an item is similar to the item that you have liked. Among all similarity algorithm, cosine similarity is one of the most common one. Below is the formula of cosine similarity.
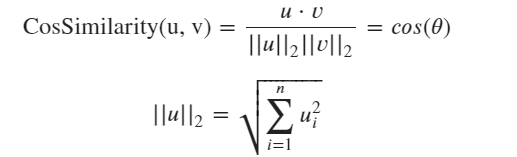
where u is the vector of an item in embedding space and v is the vector of your preference in embedding space. The value could be in the range of -1 to 1. If the value is closer to 1, it means that there is a strong similarity. If the value is closer to 0, then there is no similarity. Meanwhile, if the value is closer to -1, then it means that they are similar vectors, but in the opposite direction.
I think it will be easier to understand how content-based recommender system works with an illustration.
Suppose you have watched different movies and then gave ratings from 1 to10 to each of the movies that you have watched. Based on this information, a user-movie matrix can be built.

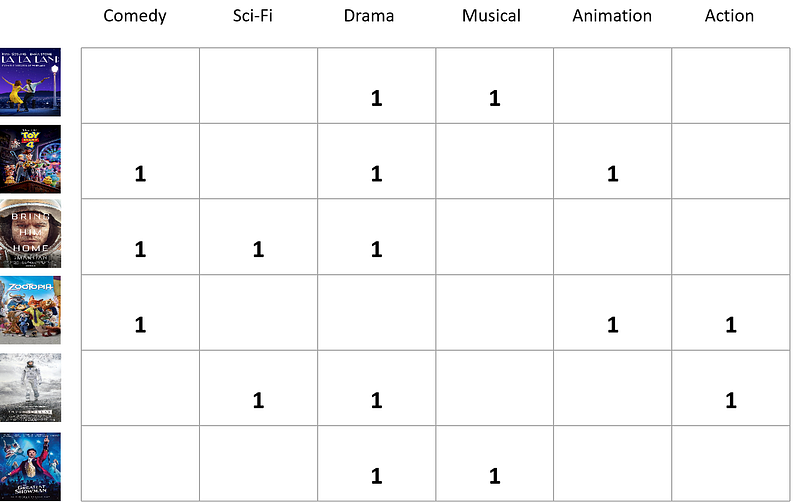
Let’s say there are six different movies in a store: La La Land, Toy Story 4, The Martian, Zootopia, Interstellar, and The Greatest Showman. Out of these six, you have watched three of them: La La Land, The Martian, and Zootopia. The task is to find out which other movies that we should recommend to you. To do this, first we need to define the features of each of these movies. For this illustration, let’s use movie genre as the features.
Each movie then will be hot-encoded based on their genre, i.e its value will be 1 if a movie has a specific genre. Let’s take a look at La La Land for example, this movie has Musical and Drama genres, hence it will have a value of 1 for Musical and Drama. This matrix is called movie feature matrix.
After we have user movie matrix and movie feature matrix, the next step will be computing the weighted feature matrix. It is very easy to compute this matrix. All we have to do is to scale the movie features based on the rating you gave to certain movies. To scale the movie features, just multiply a movie feature with the rating.
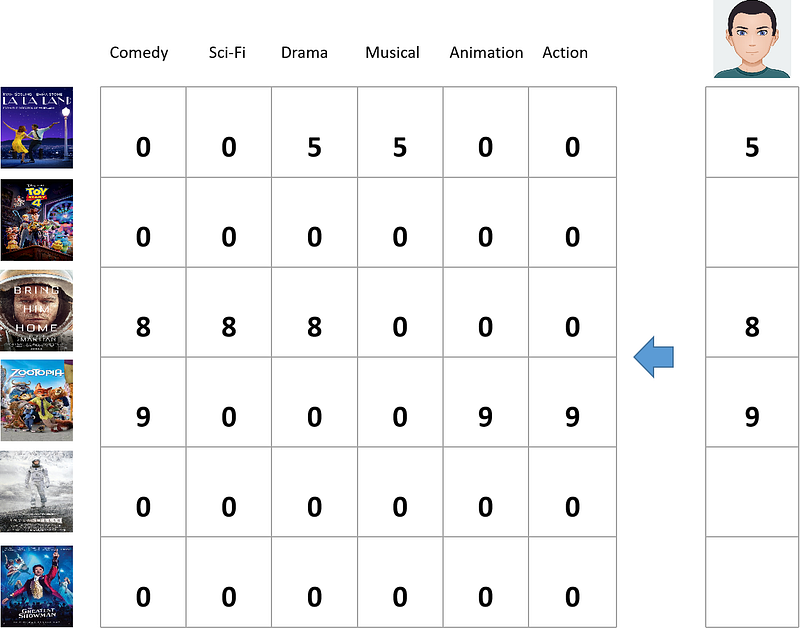
As shown in the figure above, you gave La La Land 5 stars and La La Land has Drama and Musical genres, hence we multiply 1 that we have in movie feature matrix with the movie rating, which is 5. Then we do the same thing for the other movies like The Martian and Zootopia.
The next step is to sum all of the weighted feature matrix column-wise. At the end, we get #features vector dimension as we can see in the figure below.

Next, the vector of the sum of weighted feature matrix needs to be normalized individually.
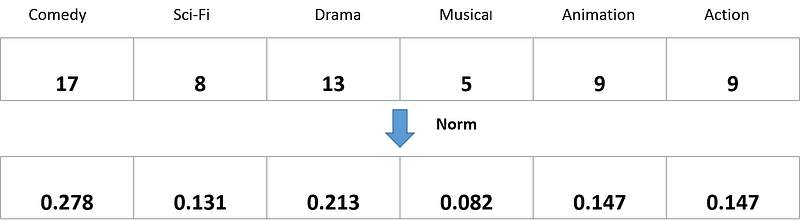
And finally we get the user feature vector. This normalized user feature vector basically tells you each person’s preference with respect to the item’s feature, which in this illustration is movie genre.
From the user feature vector above, we can see that you have a high preference in a movie with Comedy genre (0.278), followed by Drama genre (0.213), and so on.
Next, we can make an inference about which other movies that you would probably like. In order to do this, we need to compute the dot product of user feature vector and movie feature matrix.
For example, Interstellar has a mixed genre of Sci-Fi, Drama, and Action. From user feature vector, we know you have a preference of 0.131 for movie with Sci-Fi genre, 0.213 for Drama genre, and 0.147 for Action genre. Thus, we can compute the final value for Interstellar equal to 0.131 + 0.213 + 0.147 = 0.491.

Now we get a specific value for each movie based on your preferences. The higher the value, the more likely it is that you would like the movie. However, as we know earlier, you have seen La La Land, Toy Story 4, and Zootopia, hence we need to mask these movies whenever we want to implement the algorithm in a code.
Based on the value that we got, we finally could recommend few movies for you. The first movie that we should recommend to you is Toy Story 4, followed by Interstellar, and The Greatest Showman.
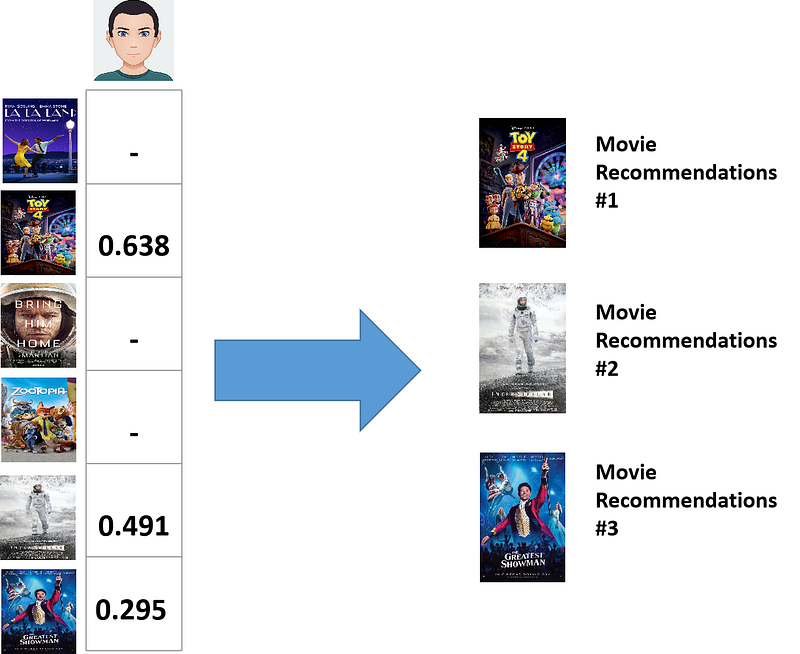
To apply content-based recommendation algorithm to more people, the algorithm is exactly the same and we only need to stack the resulting weighted feature matrices depending on the number of people. Hence, the only difference then is the final shape dimension that we get for weighted feature matrices and user feature vectors.
Pros and Cons of Content-Based Recommendation System
As any other recommendation system algorithm, content-based recommendation system has its pros and cons, depending on the context.
The biggest pros of content-based recommendation system are:
- You only need the data of one specific user or person to recommend items to them. Hence, you don’t need to collect a lot of data consisting of large amount of users to recommend something.
- Content-based recommendation system allows you to recommend items that are very specific to each user’s preference.
On the flip side, here are the drawbacks of content-based recommendation system:
- This recommendation system is a highly simplified model and thus, cannot handle inter-dependencies. Suppose you like action movies with violence and historical documentaries, but not violent documentaries. Content-based recommendation cannot capture this inter-dependencies.
- The specificity of the recommendation given by content-based recommender system means that it will always give you a “safe” recommendation all the time. For example, let’s say you liked Sci-Fi movies. Because of your strong preference in these Sci-Fi movies, the content-based recommendation system then will always give you movie recommendations with Sci-Fi genre. In other words, you won’t get a chance to find out more about great movies from other genres that you might be interested in.
In order to tackle the specificity of the recommendation given by content-based recommendation, let’s now take a look at collaborative filtering algorithm.
What is Collaborative Filtering?
In collaborative filtering, the relationship between one user to other users or between one item to other items exist. Hence, there are two types of collaborative filtering:
- User to user collaborative filtering
- Item to item collaborative filtering
Because the relationship between users exist, then you will get a chance to get a recommendation about items similar to what you have liked in the past and also, the items that the other users which have a high similarity to you have liked in the past.
To make it clearer, let’s take a look at below example.
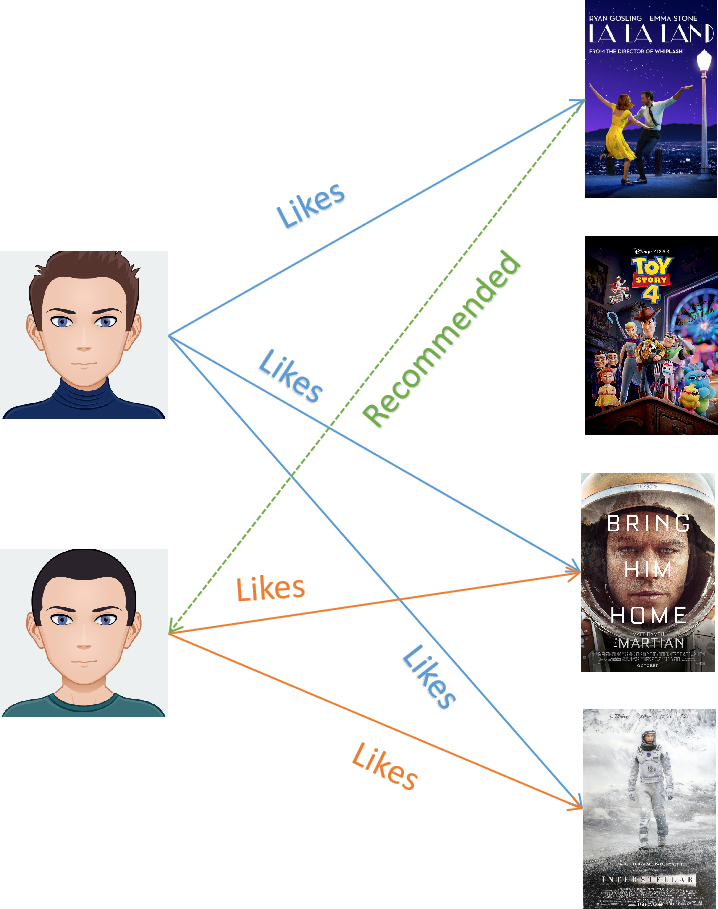
In the image above, you liked Interstellar and The Martian, which both of them are Sci-Fi movies. At the same time, your friend liked Interstellar, The Martian, and La La Land. Since you and your friend liked Interstellar and The Martian, then both of you are similar users and the algorithm will likely to recommend you La La Land, although it doesn’t have Sci-Fi genre. This is the intuition behind user to user collaborative filtering.

In item to item collaborative filtering, different items are said to be similar based on the behavior of the user. In the above image, let’s say both of you and your friend, Carlos liked The Martian and Interstellar. The algorithm then will categorize The Martian and Interstellar as similar items. Then, your other friend, Sarah liked The Martian, but she hasn’t watched Interstellar yet. Based on her interest in The Martian and due to the fact that The Martian and Interstellar are similar items, then item to item collaborative filtering algorithm will likely to recommend her Interstellar.
How does Collaborative Filtering Works?
In order to make it easier to understand how collaborative filtering works, let’s also use an illustration. The illustration below will show you how user to user collaborative filtering works.
Suppose there are four users: Chandler, Monica, Ross, and Rachel. They have watched different movies and then gave ratings from 1 to10 to each of the movies that they have watched. We can illustrate a user movie matrix based on this.
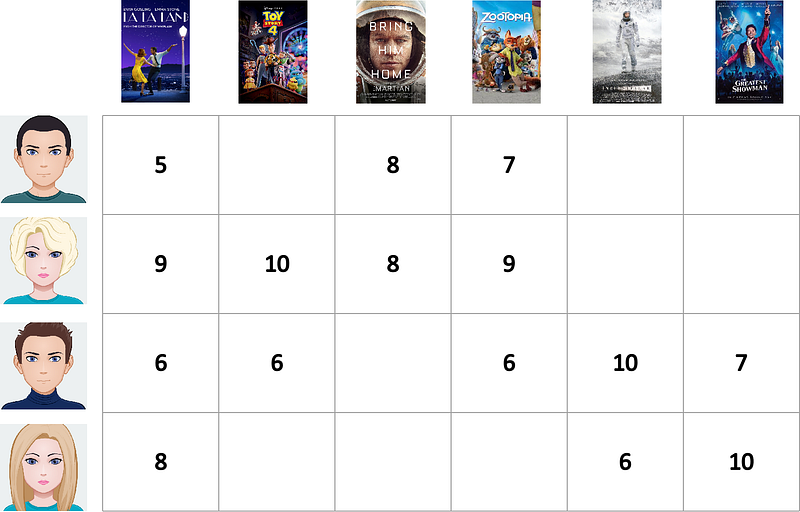
From the user movie matrix above, we want to recommend several movies to Chandler (the first person shown in the user movie matrix above). The first step would be to compute the similarity weight between Chandler and other users based on the movie he already watched (La La Land, The Martian, and Zootopia).
But how do we compute the similarity weight? This could be done using cosine similarity, L2 distance, or Pearson’s correlation algorithm, which the formula is shown below:
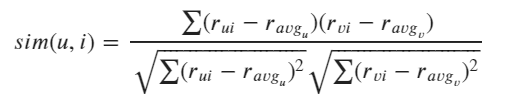
where: r_ui is the rating the user u has given to movie i, r_vi is the rating the user v has given to movie i, r_avg_u is the average rating of user u, and r_avg_v is the average rating of user v. The computation of average rating of each user here is very important to normalize each user rating since different people have different judgement on how they rate a movie.
Using above formula, we can compute the similarity between Chandler and each other user. Let’s say that after we compute the similarity, we get the following user similarity matrix with respect to Chandler.

Once we obtained user similarity matrix, now we can compute the weighted rating matrix by multiplying the user similarity matrix with user rating of the movies that Chandler hasn’t watched yet.

Finally, we can now recommend some new movies for Chandler based on other user behavior by aggregating the weighted rating matrix and then normalizing it with the aggregation of user similarity matrix.

From the image above, user to user collaborative filtering algorithm will recommend Interstellar, followed by The Greatest Showman and Toy Story 4 to Chandler.
Remember that in the above illustration, user to user collaborative filtering algorithm was implemented. To implement item to item collaborative filtering, the computation process is similar. However, instead of computing the user similarity, we compute items similarity normally with cosine similarity.
Which Collaborative Filtering Algorithm Should You Choose?
As you already know, there are two types of collaborative filtering algorithm: user to user and item to item collaborative filtering. Both types of algorithm have their own advantages and disadvantages.
If you want to recommend different kinds of items to user, for example movie with different genres, then it is better to use user to user collaborative filtering since item to item collaborative filtering has a lower serendipity property.
However if you have small number of items with huge amount of ratings, then item to item algorithm will work best since it is computationally less expensive than user to user. This is because in this case, computing all pairs of item’s correlation is less expensive than computing all pairs of user’s correlation.
In order to improve the computation performance of collaborative filtering, it is better to simplify the model such that it will only return the top k-most similar items.
Pros and Cons of Collaborative Filtering
Same as content-based recommendation system, collaborative filtering also has some pros and cons. Here are the pros of collaborative filtering algorithm:
- No domain knowledge is necessary. This is because collaborative filtering uses user interaction with items to generate item recommendations. So it is not a problem if you, as a business owner of a retail store, don’t have a deep knowledge regarding certain items.
- The serendipity factor. Collaborative filtering can solve the major problem of content-based algorithm, which is the ability to recommend an item that is outside your “zone” and you would probably like.
However, below are the cons of collaborative filtering algorithm:
- Data Sparsity. This is the major problem of collaborative filtering algorithm. For example consider the situation when we have a large amount of items to sell but small number of ratings for each item. In this situation, sometimes there will be a point where the recommendation cannot be made when one user doesn’t have anything in common with another users.
- Computational performance. With millions of users, it is very expensive to compute all pairs of user’s correlation.
- Cold start problem. It is very difficult to recommend items to a new user who hasn’t rated any item yet, or if there is a new item which hasn’t received any rating yet from the users.
So far, we know two of the most common recommendation systems: content-based recommendation system and collaborative filtering. However, both of the algorithms are stateless, i.e they don’t take context into consideration when generating recommendation to the user. Let’s take a look at context-aware recommendation system to solve this problem.
What is Context-Aware Recommendation System?
The traditional content-based and collaborative filtering algorithm are somewhat stateless, i.e they don’t put context into consideration when recommending items to users. With the addition of context to the traditional collaborative filtering, then we get the so-called context-aware recommendation system.
But why the addition of context is important? Well, we know that the rating that the users give to certain items are not only depending on the quality of the item itself, but also on the context on who, when, where, and how they experienced the item. Let’s take a look at the table below.
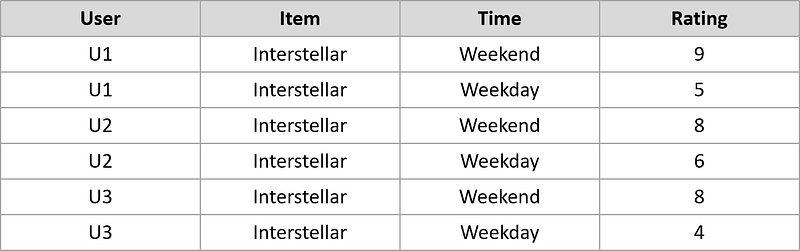
As you can see above, three different users watched Interstellar twice, once on the weekend and once on weekdays. Although they watched the same movie, but the rating that they gave to Interstellar is different on different occasions. This is where the context plays a role. They probably gave Interstellar a lower rating on weekday because they were exhausted just coming back from work when watching it, thus they didn’t enjoy the movie as much as when they watched it on weekend. Because of this, now we know that it is better to recommend Interstellar on weekend rather than weekday.
With the addition of context when recommending items to the users, then of course the quality of recommendations would be much better and the user experience will be improved.
How Context-Aware Recommendation System Works?
In general, there are two types of context-aware recommendation system: contextual pre-filtering and contextual post-filtering.
Contextual Pre-filtering
In contextual pre-filtering, let’s say we have a 3D tensor which consists of user, item, and one context data (time of the day: weekend or weekday). Thus, the diagram of how the contextual pre-filtering works can be seen as below.
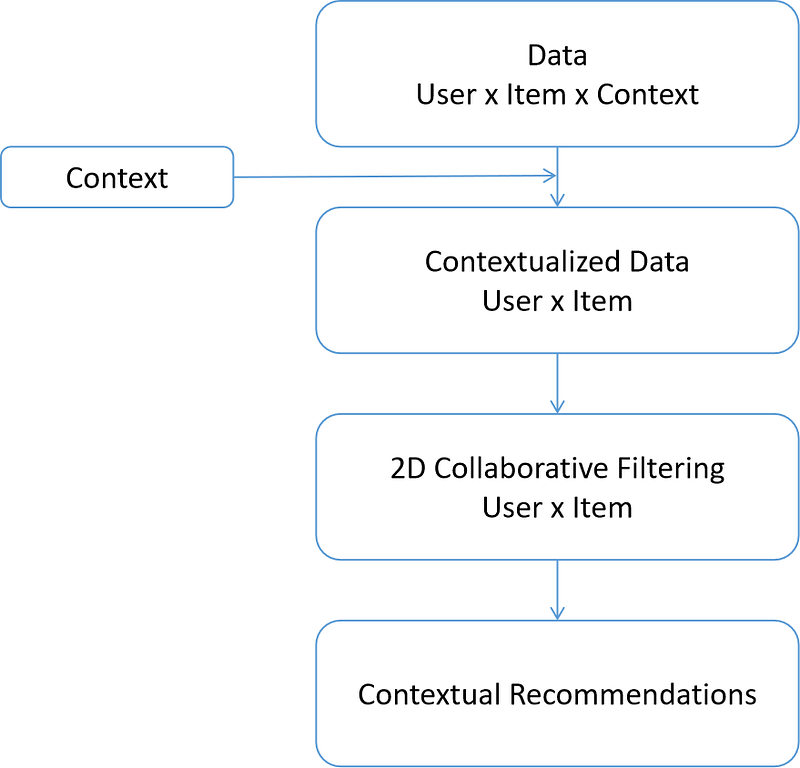
First, our original 3D tensor will be filtered depending on the context. For example, you want to watch a movie on Saturday and you want to get a recommendation which movie should you watch on Saturday, then the 3D tensor will be filtered such that at the end we get a contextualized data, i.e data of users and movies they rate on Saturday.
After that, we basically end up with a 2D matrix of users and items similar to what we have seen in collaborative filtering algorithm. From this step, the way on how the algorithm generates recommendation is exactly the same as collaborative filtering.
Contextual Post-filtering
To illustrate contextual post-filtering, let’s assume the same condition as we have in contextual pre-filtering, i.e we have 3D tensor consists of user, item and one context data. The diagram of how the contextual post-filtering works can be seen as below.
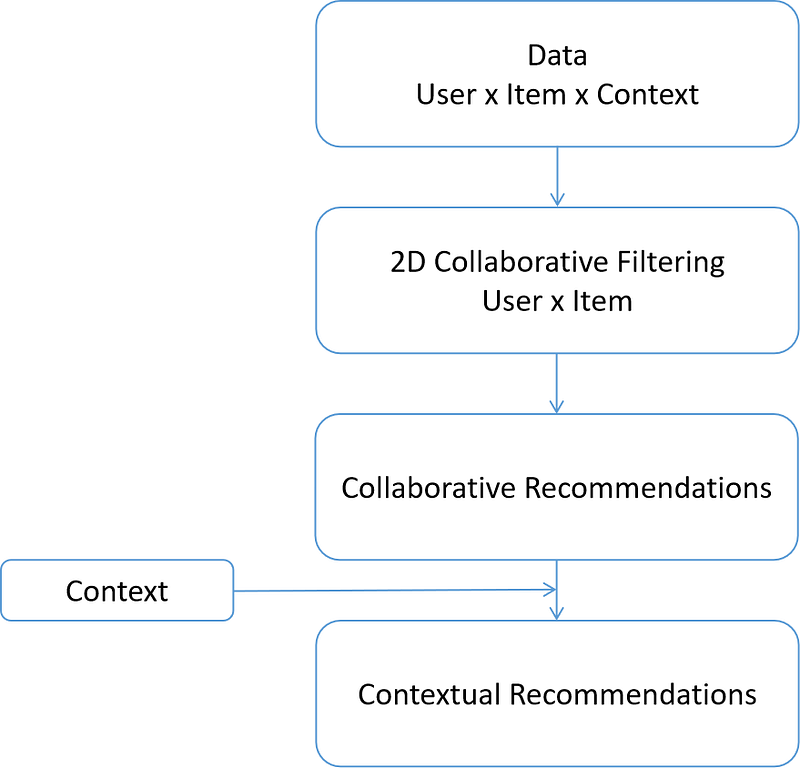
At the beginning, we simply ignore the context in the data, which means that the algorithm will be exactly the same as collaborative filtering all the way until the algorithm generates recommendation to certain users. Next, the recommendation generated from collaborative filtering algorithm will be filtered based on the context, hence the name contextual post-filtering.
Suppose you want to see a movie on Saturday and on Saturday, you normally watch action movies. Hence, from all of the generated recommendations, the recommendations will be further adjusted based on the given context. The adjustment can be that non-action movies will be filtered out or the rank of the movie recommendation will be altered.
Pros and Cons of Content-Aware Recommendation System
The biggest pros of content-aware recommendation system is that its ability to provide additional context for the recommendation algorithm. This provides additional refinements to the recommendation result, which then improves the quality of the recommendation and the user experience as well.
On the flip side, since context-aware recommendation system is built on top of collaborative filtering algorithm, then it shares the same cons as collaborative filtering such as data sparsity problem, computational performance for very big users and items, as well as cold start for new users or new items.
How do We Know that the Recommendation is Good?
To measure how good our recommender system is at generating recommendation to the users, we need to define certain metrics. But the question is, what are the metrics that we can use to quantify the quality of recommendation? This section will cover two common ways to measure how good is the recommendation generated by our recommender system.
Mean Reciprocal Rank
The first measurement is using mean reciprocal rank (MRR). The key idea behind MRR is that it measures how far down the list does a user need to scroll the recommendation before he/she finds the item that they like. The best value is 1, which means that the user find the most useful item for them in the first rank of the generated recommendation list. It’s like when you search something in Google with a keyword, and you find the page that you’re looking for straight in the first rank of Google search. The more the users need to go further down the list of recommendation, the lower the MRR value and hence, the worse the recommendation quality.
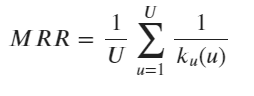
For each user u:
- Generate a list of recommendations.
- Find rank k_u of the relevant recommendations (i.e the recommendation that the user likes). For example, if the user likes the third item in the recommendation list, then k_u is 3.
- Compute reciprocal rank 1/k_u
Sum over the reciprocal rank of all users and divide the result by the total number of users.
Mean Average Precision
The second measurement is mean average precision (MAP). The key idea behind MAP is that it measures what fraction of n generated recommendations are useful for the user. For example, the recommender system gives you five movie recommendations. Out of these five, it turns out that you only like three of them. The average precision then can be computed as the illustration below.
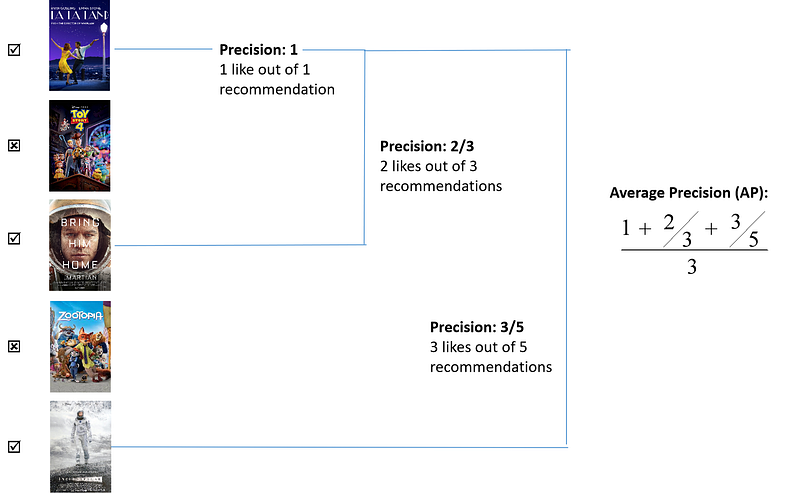
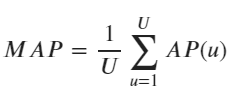
For each user u:
- Compute precision list through relevant recommendations.
- Average the sub-list precision.
Sum over the average precision of all users and divide the result by the total number of users. The maximum value for MAP is 1, which means that the user likes all of the recommendations generated by recommender system.
Takeaways
Now you know already the overview of recommendation system: how they differ with each other, how they work, what are their pros and cos, as well as some of the metrics to measure the quality of the recommendation system.
Here are some takeaways from this article:
- In content-based recommendation system, no user data interaction is needed. The recommendation is made based only on your past activity or history. This gives you a recommendation with high specificity and very low serendipity.
- In collaborative filtering recommendation system, the user data interaction does exist, which allows you to get item recommendations that are outside your zone, i.e higher level of serendipity.
- Collaborative filtering can be classified into two categories: user to user and item to item. Both of categories have their own advantages and disadvantages, so whether you should apply user to user or item to item totally depends on the project and situation.
- Content-aware filtering is a recommendation system built on top of collaborative filtering which provides contextual and more precised recommendation to the users.
- Mean Reciprocal Rank and Mean Average Precision are the common metrics to measure the quality and the usefulness of the recommendations generated by recommender system in the perspective of users.




